 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMDFusion: Bidirectional Fusion Network with Cross-modality Knowledge Distillation for LIDAR Semantic Segmentation
Paper and Code
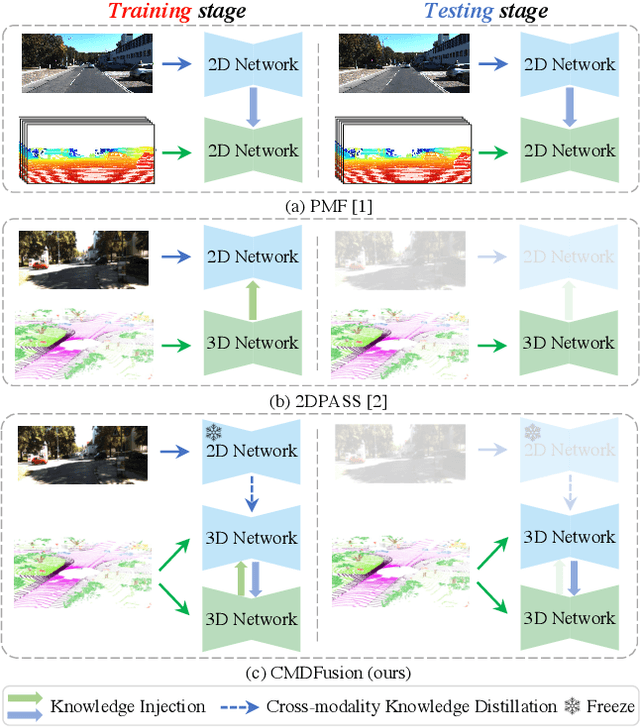
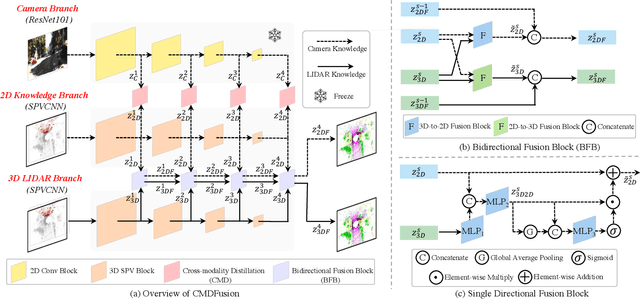
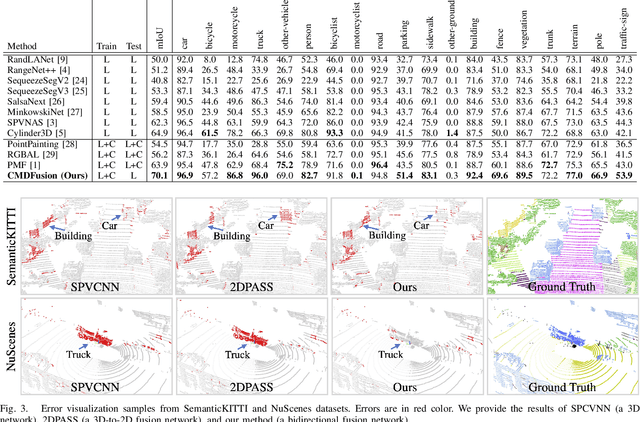

2D RGB images and 3D LIDAR point clouds provide complementary knowledge for the perception system of autonomous vehicles. Several 2D and 3D fusion methods have been explored for the LIDAR semantic segmentation task, but they suffer from different problems. 2D-to-3D fusion methods require strictly paired data during inference, which may not be available in real-world scenarios, while 3D-to-2D fusion methods cannot explicitly make full use of the 2D information. Therefore, we propose a Bidirectional Fusion Network with Cross-Modality Knowledge Distillation (CMDFusion) in this work. Our method has two contributions. First, our bidirectional fusion scheme explicitly and implicitly enhances the 3D feature via 2D-to-3D fusion and 3D-to-2D fusion, respectively, which surpasses either one of the single fusion schemes. Second, we distillate the 2D knowledge from a 2D network (Camera branch) to a 3D network (2D knowledge branch) so that the 3D network can generate 2D information even for those points not in the FOV (field of view) of the camera. In this way, RGB images are not required during inference anymore since the 2D knowledge branch provides 2D information according to the 3D LIDAR input. We show that our CMDFusion achieves the best performance among all fusion-based methods on SemanticKITTI and nuScenes datasets. The code will be released at https://github.com/Jun-CEN/CMDFusion.