 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
Sep 18, 2025This paper presents RynnVLA-001, a vision-language-action(VLA) model built upon large-scale video generative pretraining from human demonstrations. We propose a novel two-stage pretraining methodology. The first stage, Ego-Centric Video Generative Pretraining, trains an Image-to-Video model on 12M ego-centric manipulation videos to predict future frames conditioned on an initial frame and a language instruction. The second stage, Human-Centric Trajectory-Aware Modeling, extends this by jointly predicting future keypoint trajectories, thereby effectively bridging visual frame prediction with action prediction. Furthermore, to enhance action representation, we propose ActionVAE, a variational autoencoder that compresses sequences of actions into compact latent embeddings, reducing the complexity of the VLA output space. When finetuned on the same downstream robotics datasets, RynnVLA-001 achieves superior performance over state-of-the-art baselines, demonstrating that the proposed pretraining strategy provides a more effective initialization for VLA models.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
HandAugment: A Simple Data Augmentation Method for Depth-Based 3D Hand Pose Estimation
Jan 23, 2020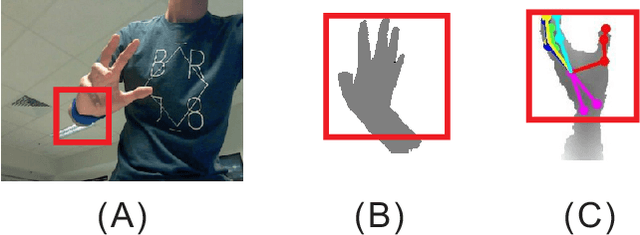

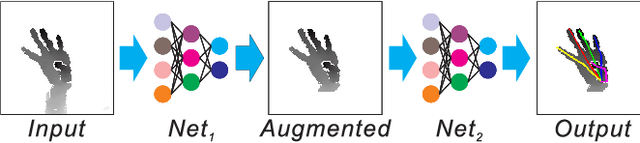

Hand pose estimation from 3D depth images, has been explored widely using various kinds of techniques in the field of computer vision. Though, deep learning based method improve the performance greatly recently, however, this problem still remains unsolved due to lack of large datasets, like ImageNet or effective data synthesis methods. In this paper, we propose HandAugment, a method to synthesize image data to augment the training process of the neural networks. Our method has two main parts: First, We propose a scheme of two-stage neural networks. This scheme can make the neural networks focus on the hand regions and thus to improve the performance. Second, we introduce a simple and effective method to synthesize data by combining real and synthetic image together in the image space. Finally, we show that our method achieves the first place in the task of depth-based 3D hand pose estimation in HANDS 2019 challenge.
End-To-End Face Detection and Recognition
Mar 31, 2017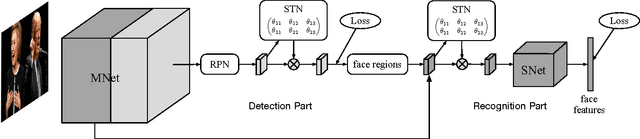
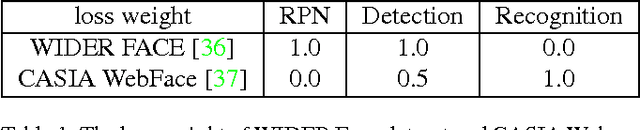
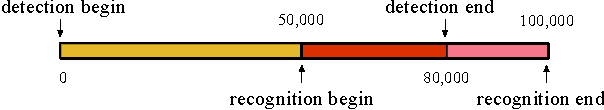

Plenty of face detection and recognition methods have been proposed and got delightful results in decades. Common face recognition pipeline consists of: 1) face detection, 2) face alignment, 3) feature extraction, 4) similarity calculation, which are separated and independent from each other. The separated face analyzing stages lead the model redundant calculation and are hard for end-to-end training. In this paper, we proposed a novel end-to-end trainable convolutional network framework for face detection and recognition, in which a geometric transformation matrix was directly learned to align the faces, instead of predicting the facial landmarks. In training stage, our single CNN model is supervised only by face bounding boxes and personal identities, which are publicly available from WIDER FACE \cite{Yang2016} dataset and CASIA-WebFace \cite{Yi2014} dataset. Tested on Face Detection Dataset and Benchmark (FDDB) \cite{Jain2010} dataset and Labeled Face in the Wild (LFW) \cite{Huang2007} dataset, we have achieved 89.24\% recall for face detection task and 98.63\% verification accuracy for face recognition task simultaneously, which are comparable to state-of-the-art results.