 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Contrastive Forward-Forward Algorithm
Sep 17, 2024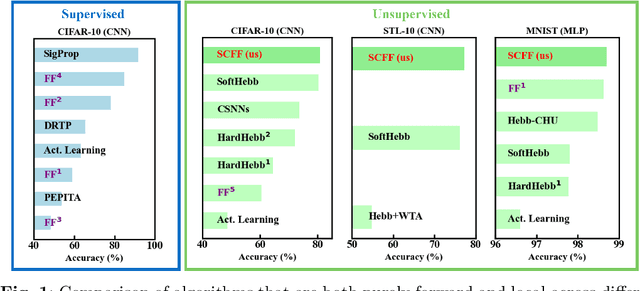

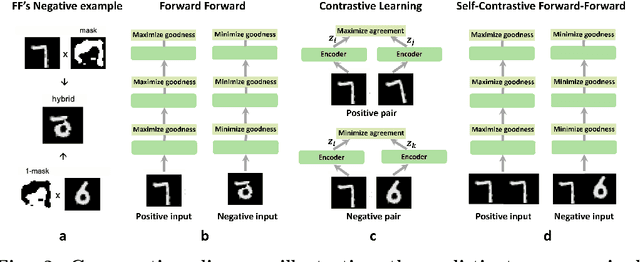
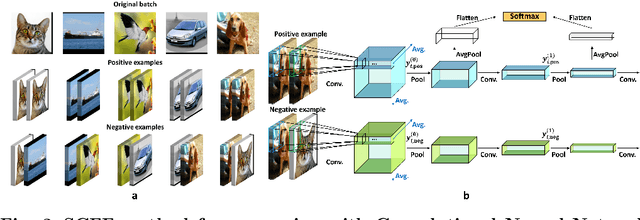
The Forward-Forward (FF) algorithm is a recent, purely forward-mode learning method, that updates weights locally and layer-wise and supports supervised as well as unsupervised learning. These features make it ideal for applications such as brain-inspired learning, low-power hardware neural networks, and distributed learning in large models. However, while FF has shown promise on written digit recognition tasks, its performance on natural images and time-series remains a challenge. A key limitation is the need to generate high-quality negative examples for contrastive learning, especially in unsupervised tasks, where versatile solutions are currently lacking. To address this, we introduce the Self-Contrastive Forward-Forward (SCFF) method, inspired by self-supervised contrastive learning. SCFF generates positive and negative examples applicable across different datasets, surpassing existing local forward algorithms for unsupervised classification accuracy on MNIST (MLP: 98.7%), CIFAR-10 (CNN: 80.75%), and STL-10 (CNN: 77.3%). Additionally, SCFF is the first to enable FF training of recurrent neural networks, opening the door to more complex tasks and continuous-time video and text processing.
Unsupervised End-to-End Training with a Self-Defined Bio-Inspired Target
Mar 18, 2024Current unsupervised learning methods depend on end-to-end training via deep learning techniques such as self-supervised learning, with high computational requirements, or employ layer-by-layer training using bio-inspired approaches like Hebbian learning, using local learning rules incompatible with supervised learning. Both approaches are problematic for edge AI hardware that relies on sparse computational resources and would strongly benefit from alternating between unsupervised and supervised learning phases - thus leveraging widely available unlabeled data from the environment as well as labeled training datasets. To solve this challenge, in this work, we introduce a 'self-defined target' that uses Winner-Take-All (WTA) selectivity at the network's final layer, complemented by regularization through biologically inspired homeostasis mechanism. This approach, framework-agnostic and compatible with both global (Backpropagation) and local (Equilibrium propagation) learning rules, achieves a 97.6% test accuracy on the MNIST dataset. Furthermore, we demonstrate that incorporating a hidden layer enhances classification accuracy and the quality of learned features across all training methods, showcasing the advantages of end-to-end unsupervised training. Extending to semi-supervised learning, our method dynamically adjusts the target according to data availability, reaching a 96.6% accuracy with just 600 labeled MNIST samples. This result highlights our 'unsupervised target' strategy's efficacy and flexibility in scenarios ranging from abundant to no labeled data availability.