 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs it the model or the metric -- On robustness measures of deeplearning models
Dec 13, 2024Determining the robustness of deep learning models is an established and ongoing challenge within automated decision-making systems. With the advent and success of techniques that enable advanced deep learning (DL), these models are being used in widespread applications, including high-stake ones like healthcare, education, border-control. Therefore, it is critical to understand the limitations of these models and predict their regions of failures, in order to create the necessary guardrails for their successful and safe deployment. In this work, we revisit robustness, specifically investigating the sufficiency of robust accuracy (RA), within the context of deepfake detection. We present robust ratio (RR) as a complementary metric, that can quantify the changes to the normalized or probability outcomes under input perturbation. We present a comparison of RA and RR and demonstrate that despite similar RA between models, the models show varying RR under different tolerance (perturbation) levels.
Real-time tracking of COVID-19 and coronavirus research updates through text mining
Feb 09, 2021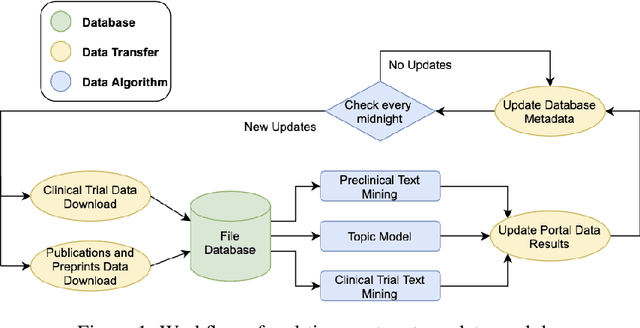
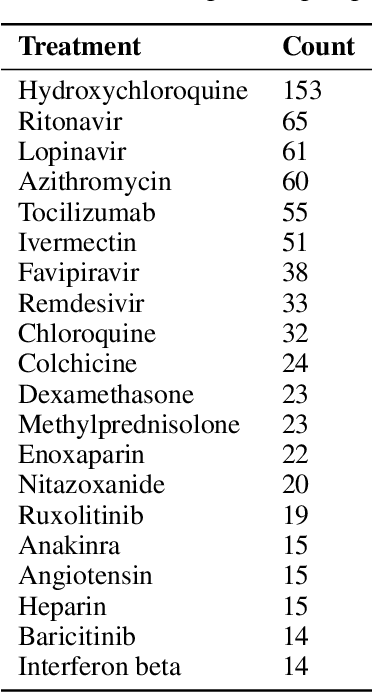
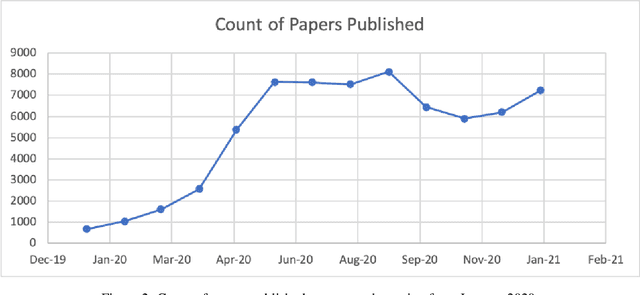
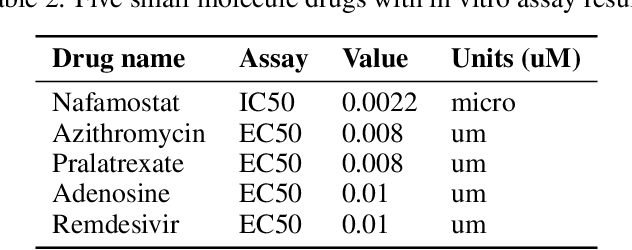
The novel coronavirus (SARS-CoV-2) which causes COVID-19 is an ongoing pandemic. There are ongoing studies with up to hundreds of publications uploaded to databases daily. We are exploring the use-case of artificial intelligence and natural language processing in order to efficiently sort through these publications. We demonstrate that clinical trial information, preclinical studies, and a general topic model can be used as text mining data intelligence tools for scientists all over the world to use as a resource for their own research. To evaluate our method, several metrics are used to measure the information extraction and clustering results. In addition, we demonstrate that our workflow not only have a use-case for COVID-19, but for other disease areas as well. Overall, our system aims to allow scientists to more efficiently research coronavirus. Our automatically updating modules are available on our information portal at https://ghddi-ailab.github.io/Targeting2019-nCoV/ for public viewing.