 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Impact of Noise and Speech Enhancement on the Intelligibility of Speech Codecs
May 05, 2026Preserving speech intelligibility is a minimum requirement for speech codecs in communication. Recently, very low-bitrate neural codecs have gained interest for replacing classical codecs, reinforcing the need to evaluate whether intelligibility is preserved in realistic scenarios. In this paper, we evaluate the intelligibility and listening effort of classical and neural speech codecs in clean and noisy conditions. Further, we assess the impact of speech enhancement (SE) before coding, simulating a possible audio processing pipeline. The results show that classical codecs are more noise robust than neural codecs. Further, SE can lead to significant intelligibility and listening effort improvements for codecs otherwise negatively affected by noise. Listening effort reveals nuanced differences when intelligibility is saturated. Lastly, objective intelligibility based on automatic speech recognition is highly correlated with subjective intelligibility scores averaged per condition.
You Are What You Say: Exploiting Linguistic Content for VoicePrivacy Attacks
Jun 11, 2025Speaker anonymization systems hide the identity of speakers while preserving other information such as linguistic content and emotions. To evaluate their privacy benefits, attacks in the form of automatic speaker verification (ASV) systems are employed. In this study, we assess the impact of intra-speaker linguistic content similarity in the attacker training and evaluation datasets, by adapting BERT, a language model, as an ASV system. On the VoicePrivacy Attacker Challenge datasets, our method achieves a mean equal error rate (EER) of 35%, with certain speakers attaining EERs as low as 2%, based solely on the textual content of their utterances. Our explainability study reveals that the system decisions are linked to semantically similar keywords within utterances, stemming from how LibriSpeech is curated. Our study suggests reworking the VoicePrivacy datasets to ensure a fair and unbiased evaluation and challenge the reliance on global EER for privacy evaluations.
Transparent NLP: Using RAG and LLM Alignment for Privacy Q&A
Feb 10, 2025



The transparency principle of the General Data Protection Regulation (GDPR) requires data processing information to be clear, precise, and accessible. While language models show promise in this context, their probabilistic nature complicates truthfulness and comprehensibility. This paper examines state-of-the-art Retrieval Augmented Generation (RAG) systems enhanced with alignment techniques to fulfill GDPR obligations. We evaluate RAG systems incorporating an alignment module like Rewindable Auto-regressive Inference (RAIN) and our proposed multidimensional extension, MultiRAIN, using a Privacy Q&A dataset. Responses are optimized for preciseness and comprehensibility and are assessed through 21 metrics, including deterministic and large language model-based evaluations. Our results show that RAG systems with an alignment module outperform baseline RAG systems on most metrics, though none fully match human answers. Principal component analysis of the results reveals complex interactions between metrics, highlighting the need to refine metrics. This study provides a foundation for integrating advanced natural language processing systems into legal compliance frameworks.
Examining the Interplay Between Privacy and Fairness for Speech Processing: A Review and Perspective
Sep 05, 2024Speech technology has been increasingly deployed in various areas of daily life including sensitive domains such as healthcare and law enforcement. For these technologies to be effective, they must work reliably for all users while preserving individual privacy. Although tradeoffs between privacy and utility, as well as fairness and utility, have been extensively researched, the specific interplay between privacy and fairness in speech processing remains underexplored. This review and position paper offers an overview of emerging privacy-fairness tradeoffs throughout the entire machine learning lifecycle for speech processing. By drawing on well-established frameworks on fairness and privacy, we examine existing biases and sources of privacy harm that coexist during the development of speech processing models. We then highlight how corresponding privacy-enhancing technologies have the potential to inadvertently increase these biases and how bias mitigation strategies may conversely reduce privacy. By raising open questions, we advocate for a comprehensive evaluation of privacy-fairness tradeoffs for speech technology and the development of privacy-enhancing and fairness-aware algorithms in this domain.
Voice Anonymization for All -- Bias Evaluation of the Voice Privacy Challenge Baseline System
Nov 27, 2023In an age of voice-enabled technology, voice anonymization offers a solution to protect people's privacy, provided these systems work equally well across subgroups. This study investigates bias in voice anonymization systems within the context of the Voice Privacy Challenge. We curate a novel benchmark dataset to assess performance disparities among speaker subgroups based on sex and dialect. We analyze the impact of three anonymization systems and attack models on speaker subgroup bias and reveal significant performance variations. Notably, subgroup bias intensifies with advanced attacker capabilities, emphasizing the challenge of achieving equal performance across all subgroups. Our study highlights the need for inclusive benchmark datasets and comprehensive evaluation strategies that address subgroup bias in voice anonymization.
About Voice: A Longitudinal Study of Speaker Recognition Dataset Dynamics
Apr 07, 2023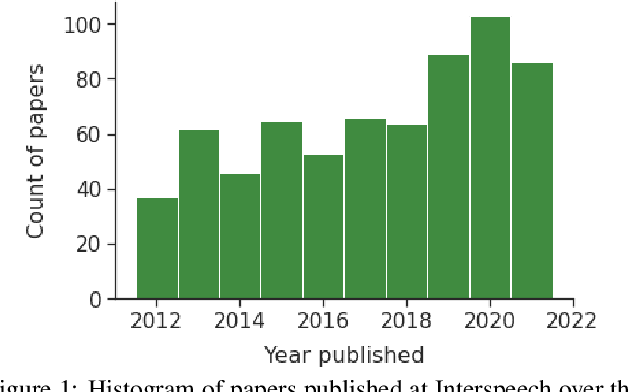

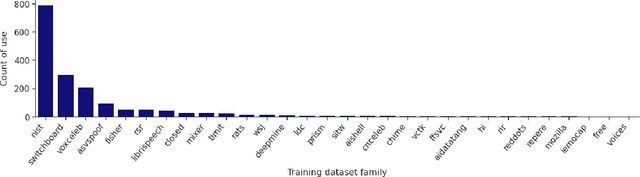

Like face recognition, speaker recognition is widely used for voice-based biometric identification in a broad range of industries, including banking, education, recruitment, immigration, law enforcement, healthcare, and well-being. However, while dataset evaluations and audits have improved data practices in computer vision and face recognition, the data practices in speaker recognition have gone largely unquestioned. Our research aims to address this gap by exploring how dataset usage has evolved over time and what implications this has on bias and fairness in speaker recognition systems. Previous studies have demonstrated the presence of historical, representation, and measurement biases in popular speaker recognition benchmarks. In this paper, we present a longitudinal study of speaker recognition datasets used for training and evaluation from 2012 to 2021. We survey close to 700 papers to investigate community adoption of datasets and changes in usage over a crucial time period where speaker recognition approaches transitioned to the widespread adoption of deep neural networks. Our study identifies the most commonly used datasets in the field, examines their usage patterns, and assesses their attributes that affect bias, fairness, and other ethical concerns. Our findings suggest areas for further research on the ethics and fairness of speaker recognition technology.
VoicePrivacy 2022 System Description: Speaker Anonymization with Feature-matched F0 Trajectories
Oct 31, 2022We introduce a novel method to improve the performance of the VoicePrivacy Challenge 2022 baseline B1 variants. Among the known deficiencies of x-vector-based anonymization systems is the insufficient disentangling of the input features. In particular, the fundamental frequency (F0) trajectories, which are used for voice synthesis without any modifications. Especially in cross-gender conversion, this situation causes unnatural sounding voices, increases word error rates (WERs), and personal information leakage. Our submission overcomes this problem by synthesizing an F0 trajectory, which better harmonizes with the anonymized x-vector. We utilized a low-complexity deep neural network to estimate an appropriate F0 value per frame, using the linguistic content from the bottleneck features (BN) and the anonymized x-vector. Our approach results in a significantly improved anonymization system and increased naturalness of the synthesized voice. Consequently, our results suggest that F0 extraction is not required for voice anonymization.