 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbout Voice: A Longitudinal Study of Speaker Recognition Dataset Dynamics
Apr 07, 2023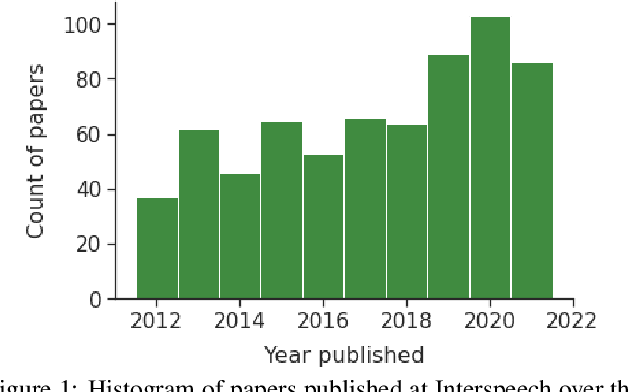

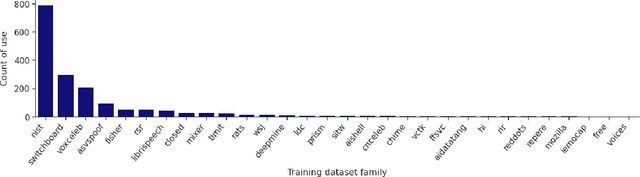

Like face recognition, speaker recognition is widely used for voice-based biometric identification in a broad range of industries, including banking, education, recruitment, immigration, law enforcement, healthcare, and well-being. However, while dataset evaluations and audits have improved data practices in computer vision and face recognition, the data practices in speaker recognition have gone largely unquestioned. Our research aims to address this gap by exploring how dataset usage has evolved over time and what implications this has on bias and fairness in speaker recognition systems. Previous studies have demonstrated the presence of historical, representation, and measurement biases in popular speaker recognition benchmarks. In this paper, we present a longitudinal study of speaker recognition datasets used for training and evaluation from 2012 to 2021. We survey close to 700 papers to investigate community adoption of datasets and changes in usage over a crucial time period where speaker recognition approaches transitioned to the widespread adoption of deep neural networks. Our study identifies the most commonly used datasets in the field, examines their usage patterns, and assesses their attributes that affect bias, fairness, and other ethical concerns. Our findings suggest areas for further research on the ethics and fairness of speaker recognition technology.
Design Guidelines for Inclusive Speaker Verification Evaluation Datasets
Apr 05, 2022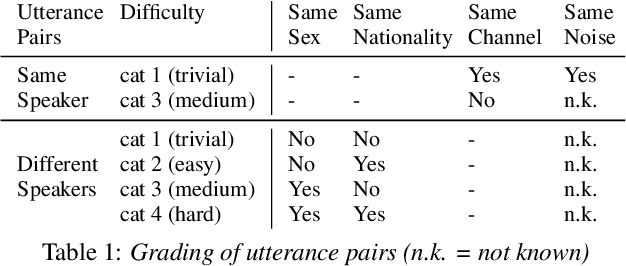
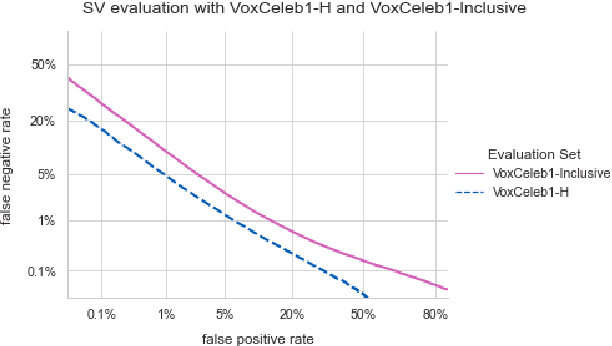
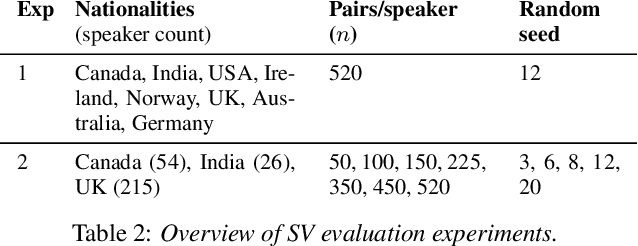
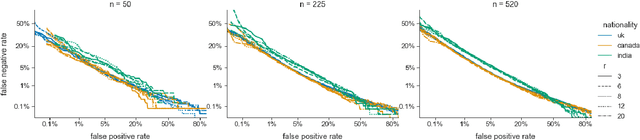
Speaker verification (SV) provides billions of voice-enabled devices with access control, and ensures the security of voice-driven technologies. As a type of biometrics, it is necessary that SV is unbiased, with consistent and reliable performance across speakers irrespective of their demographic, social and economic attributes. Current SV evaluation practices are insufficient for evaluating bias: they are over-simplified and aggregate users, not representative of real-life usage scenarios, and consequences of errors are not accounted for. This paper proposes design guidelines for constructing SV evaluation datasets that address these short-comings. We propose a schema for grading the difficulty of utterance pairs, and present an algorithm for generating inclusive SV datasets. We empirically validate our proposed method in a set of experiments on the VoxCeleb1 dataset. Our results confirm that the count of utterance pairs/speaker, and the difficulty grading of utterance pairs have a significant effect on evaluation performance and variability. Our work contributes to the development of SV evaluation practices that are inclusive and fair.