 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing Stereotypes of Anger: Emotion AI on African American Vernacular English
Nov 13, 2025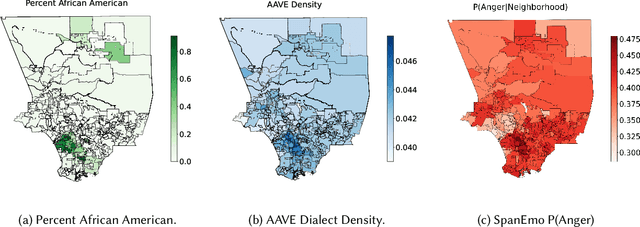
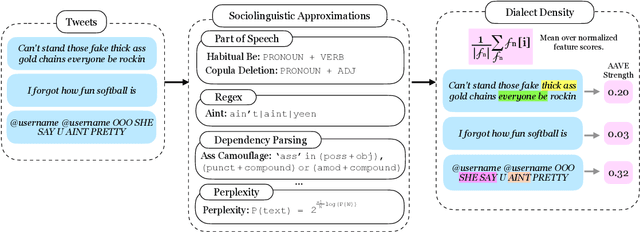
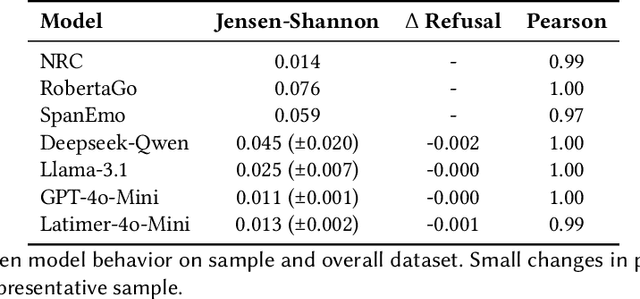

Automated emotion detection is widely used in applications ranging from well-being monitoring to high-stakes domains like mental health and hiring. However, models often rely on annotations that reflect dominant cultural norms, limiting model ability to recognize emotional expression in dialects often excluded from training data distributions, such as African American Vernacular English (AAVE). This study examines emotion recognition model performance on AAVE compared to General American English (GAE). We analyze 2.7 million tweets geo-tagged within Los Angeles. Texts are scored for strength of AAVE using computational approximations of dialect features. Annotations of emotion presence and intensity are collected on a dataset of 875 tweets with both high and low AAVE densities. To assess model accuracy on a task as subjective as emotion perception, we calculate community-informed "silver" labels where AAVE-dense tweets are labeled by African American, AAVE-fluent (ingroup) annotators. On our labeled sample, GPT and BERT-based models exhibit false positive prediction rates of anger on AAVE more than double than on GAE. SpanEmo, a popular text-based emotion model, increases false positive rates of anger from 25 percent on GAE to 60 percent on AAVE. Additionally, a series of linear regressions reveals that models and non-ingroup annotations are significantly more correlated with profanity-based AAVE features than ingroup annotations. Linking Census tract demographics, we observe that neighborhoods with higher proportions of African American residents are associated with higher predictions of anger (Pearson's correlation r = 0.27) and lower joy (r = -0.10). These results find an emergent safety issue of emotion AI reinforcing racial stereotypes through biased emotion classification. We emphasize the need for culturally and dialect-informed affective computing systems.
About Voice: A Longitudinal Study of Speaker Recognition Dataset Dynamics
Apr 07, 2023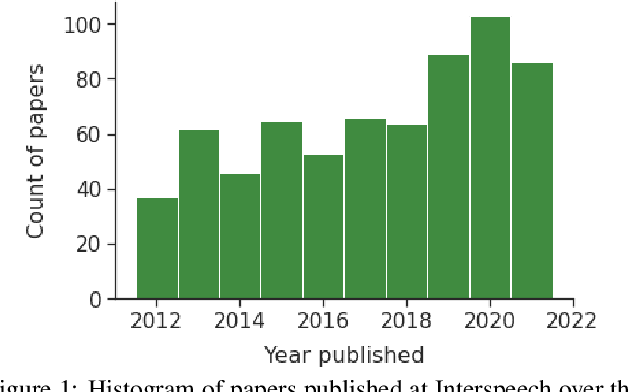

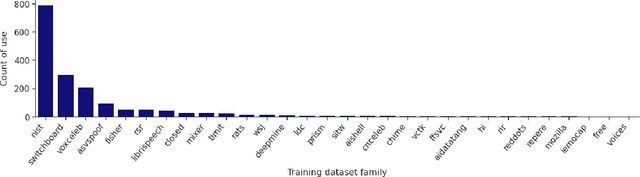

Like face recognition, speaker recognition is widely used for voice-based biometric identification in a broad range of industries, including banking, education, recruitment, immigration, law enforcement, healthcare, and well-being. However, while dataset evaluations and audits have improved data practices in computer vision and face recognition, the data practices in speaker recognition have gone largely unquestioned. Our research aims to address this gap by exploring how dataset usage has evolved over time and what implications this has on bias and fairness in speaker recognition systems. Previous studies have demonstrated the presence of historical, representation, and measurement biases in popular speaker recognition benchmarks. In this paper, we present a longitudinal study of speaker recognition datasets used for training and evaluation from 2012 to 2021. We survey close to 700 papers to investigate community adoption of datasets and changes in usage over a crucial time period where speaker recognition approaches transitioned to the widespread adoption of deep neural networks. Our study identifies the most commonly used datasets in the field, examines their usage patterns, and assesses their attributes that affect bias, fairness, and other ethical concerns. Our findings suggest areas for further research on the ethics and fairness of speaker recognition technology.