 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxATtack: A Multimodal Attack on Voice Anonymization Systems
Jul 16, 2025Voice anonymization systems aim to protect speaker privacy by obscuring vocal traits while preserving the linguistic content relevant for downstream applications. However, because these linguistic cues remain intact, they can be exploited to identify semantic speech patterns associated with specific speakers. In this work, we present VoxATtack, a novel multimodal de-anonymization model that incorporates both acoustic and textual information to attack anonymization systems. While previous research has focused on refining speaker representations extracted from speech, we show that incorporating textual information with a standard ECAPA-TDNN improves the attacker's performance. Our proposed VoxATtack model employs a dual-branch architecture, with an ECAPA-TDNN processing anonymized speech and a pretrained BERT encoding the transcriptions. Both outputs are projected into embeddings of equal dimensionality and then fused based on confidence weights computed on a per-utterance basis. When evaluating our approach on the VoicePrivacy Attacker Challenge (VPAC) dataset, it outperforms the top-ranking attackers on five out of seven benchmarks, namely B3, B4, B5, T8-5, and T12-5. To further boost performance, we leverage anonymized speech and SpecAugment as augmentation techniques. This enhancement enables VoxATtack to achieve state-of-the-art on all VPAC benchmarks, after scoring 20.6% and 27.2% average equal error rate on T10-2 and T25-1, respectively. Our results demonstrate that incorporating textual information and selective data augmentation reveals critical vulnerabilities in current voice anonymization methods and exposes potential weaknesses in the datasets used to evaluate them.
You Are What You Say: Exploiting Linguistic Content for VoicePrivacy Attacks
Jun 11, 2025Speaker anonymization systems hide the identity of speakers while preserving other information such as linguistic content and emotions. To evaluate their privacy benefits, attacks in the form of automatic speaker verification (ASV) systems are employed. In this study, we assess the impact of intra-speaker linguistic content similarity in the attacker training and evaluation datasets, by adapting BERT, a language model, as an ASV system. On the VoicePrivacy Attacker Challenge datasets, our method achieves a mean equal error rate (EER) of 35%, with certain speakers attaining EERs as low as 2%, based solely on the textual content of their utterances. Our explainability study reveals that the system decisions are linked to semantically similar keywords within utterances, stemming from how LibriSpeech is curated. Our study suggests reworking the VoicePrivacy datasets to ensure a fair and unbiased evaluation and challenge the reliance on global EER for privacy evaluations.
Voice Anonymization for All -- Bias Evaluation of the Voice Privacy Challenge Baseline System
Nov 27, 2023In an age of voice-enabled technology, voice anonymization offers a solution to protect people's privacy, provided these systems work equally well across subgroups. This study investigates bias in voice anonymization systems within the context of the Voice Privacy Challenge. We curate a novel benchmark dataset to assess performance disparities among speaker subgroups based on sex and dialect. We analyze the impact of three anonymization systems and attack models on speaker subgroup bias and reveal significant performance variations. Notably, subgroup bias intensifies with advanced attacker capabilities, emphasizing the challenge of achieving equal performance across all subgroups. Our study highlights the need for inclusive benchmark datasets and comprehensive evaluation strategies that address subgroup bias in voice anonymization.
Evaluation of the Speech Resynthesis Capabilities of the VoicePrivacy Challenge Baseline B1
Aug 22, 2023Speaker anonymization systems continue to improve their ability to obfuscate the original speaker characteristics in a speech signal, but often create processing artifacts and unnatural sounding voices as a tradeoff. Many of those systems stem from the VoicePrivacy Challenge (VPC) Baseline B1, using a neural vocoder to synthesize speech from an F0, x-vectors and bottleneck features-based speech representation. Inspired by this, we investigate the reproduction capabilities of the aforementioned baseline, to assess how successful the shared methodology is in synthesizing human-like speech. We use four objective metrics to measure speech quality, waveform similarity, and F0 similarity. Our findings indicate that both the speech representation and the vocoder introduces artifacts, causing an unnatural perception. A MUSHRA-like listening test on 18 subjects corroborate our findings, motivating further research on the analysis and synthesis components of the VPC Baseline B1.
Deep Learning-based F0 Synthesis for Speaker Anonymization
Jun 29, 2023



Voice conversion for speaker anonymization is an emerging concept for privacy protection. In a deep learning setting, this is achieved by extracting multiple features from speech, altering the speaker identity, and waveform synthesis. However, many existing systems do not modify fundamental frequency (F0) trajectories, which convey prosody information and can reveal speaker identity. Moreover, mismatch between F0 and other features can degrade speech quality and intelligibility. In this paper, we formally introduce a method that synthesizes F0 trajectories from other speech features and evaluate its reconstructional capabilities. Then we test our approach within a speaker anonymization framework, comparing it to a baseline and a state-of-the-art F0 modification that utilizes speaker information. The results show that our method improves both speaker anonymity, measured by the equal error rate, and utility, measured by the word error rate.
VoicePrivacy 2022 System Description: Speaker Anonymization with Feature-matched F0 Trajectories
Oct 31, 2022We introduce a novel method to improve the performance of the VoicePrivacy Challenge 2022 baseline B1 variants. Among the known deficiencies of x-vector-based anonymization systems is the insufficient disentangling of the input features. In particular, the fundamental frequency (F0) trajectories, which are used for voice synthesis without any modifications. Especially in cross-gender conversion, this situation causes unnatural sounding voices, increases word error rates (WERs), and personal information leakage. Our submission overcomes this problem by synthesizing an F0 trajectory, which better harmonizes with the anonymized x-vector. We utilized a low-complexity deep neural network to estimate an appropriate F0 value per frame, using the linguistic content from the bottleneck features (BN) and the anonymized x-vector. Our approach results in a significantly improved anonymization system and increased naturalness of the synthesized voice. Consequently, our results suggest that F0 extraction is not required for voice anonymization.
Exploring the Importance of F0 Trajectories for Speaker Anonymization using X-vectors and Neural Waveform Models
Oct 13, 2021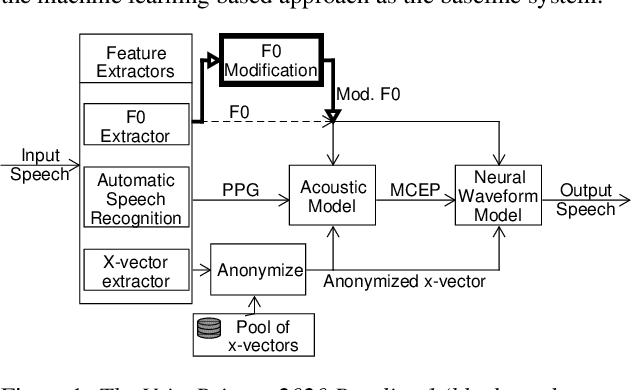
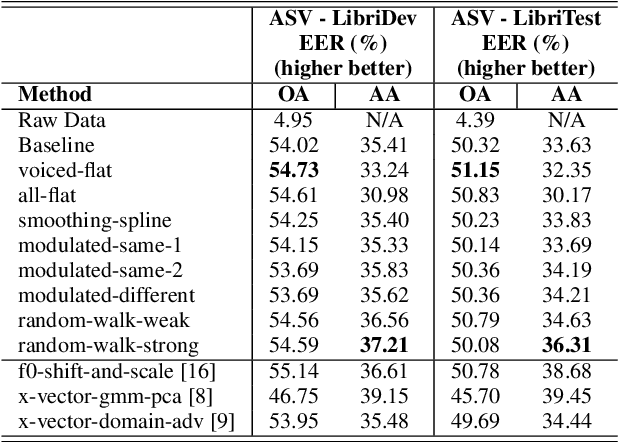
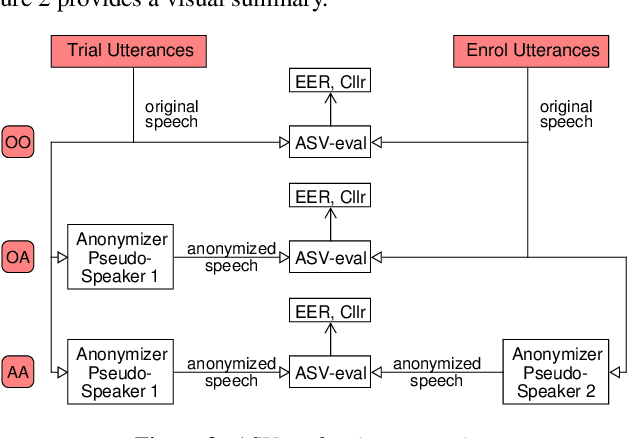
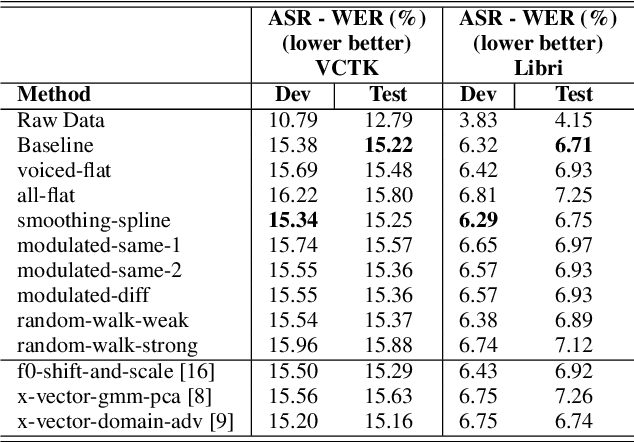
Voice conversion for speaker anonymization is an emerging field in speech processing research. Many state-of-the-art approaches are based on the resynthesis of the phoneme posteriorgrams (PPG), the fundamental frequency (F0) of the input signal together with modified X-vectors. Our research focuses on the role of F0 for speaker anonymization, which is an understudied area. Utilizing the VoicePrivacy Challenge 2020 framework and its datasets we developed and evaluated eight low-complexity F0 modifications prior resynthesis. We found that modifying the F0 can improve speaker anonymization by as much as 8% with minor word-error rate degradation.