 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Back-ends for Online Speaker Recognition and Clustering
Feb 19, 2023This paper focuses on multi-enrollment speaker recognition which naturally occurs in the task of online speaker clustering, and studies the properties of different scoring back-ends in this scenario. First, we show that popular cosine scoring suffers from poor score calibration with a varying number of enrollment utterances. Second, we propose a simple replacement for cosine scoring based on an extremely constrained version of probabilistic linear discriminant analysis (PLDA). The proposed model improves over the cosine scoring for multi-enrollment recognition while keeping the same performance in the case of one-to-one comparisons. Finally, we consider an online speaker clustering task where each step naturally involves multi-enrollment recognition. We propose an online clustering algorithm allowing us to take benefits from the PLDA model such as the ability to handle uncertainty and better score calibration. Our experiments demonstrate the effectiveness of the proposed algorithm.
Baselines and Protocols for Household Speaker Recognition
May 05, 2022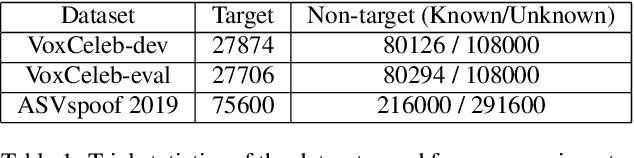
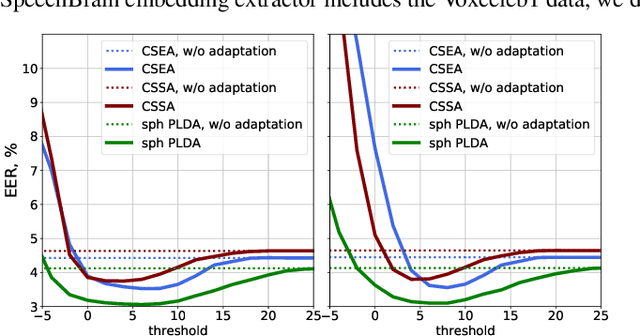
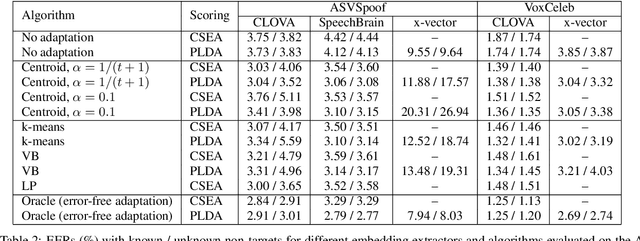
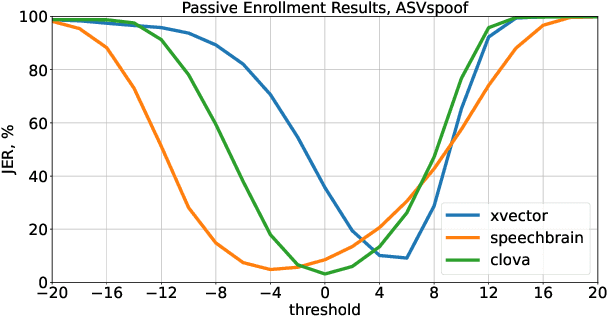
Speaker recognition on household devices, such as smart speakers, features several challenges: (i) robustness across a vast number of heterogeneous domains (households), (ii) short utterances, (iii) possibly absent speaker labels of the enrollment data (passive enrollment), and (iv) presence of unknown persons (guests). While many commercial products exist, there is less published research and no publicly-available evaluation protocols or open-source baselines. Our work serves to bridge this gap by providing an accessible evaluation benchmark derived from public resources (VoxCeleb and ASVspoof 2019 data) along with a preliminary pool of open-source baselines. This includes four algorithms for active enrollment (speaker labels available) and one algorithm for passive enrollment.
Magnitude-aware Probabilistic Speaker Embeddings
Feb 28, 2022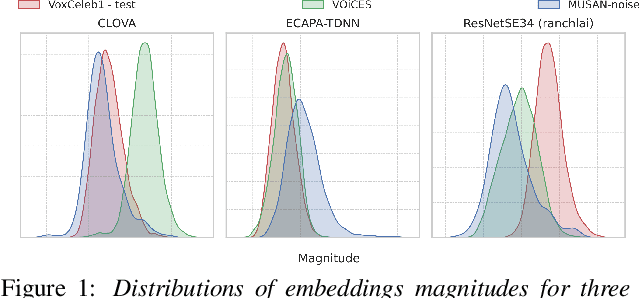


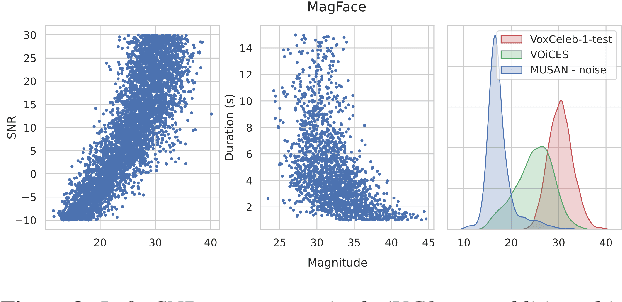
Recently, hyperspherical embeddings have established themselves as a dominant technique for face and voice recognition. Specifically, Euclidean space vector embeddings are learned to encode person-specific information in their direction while ignoring the magnitude. However, recent studies have shown that the magnitudes of the embeddings extracted by deep neural networks may indicate the quality of the corresponding inputs. This paper explores the properties of the magnitudes of the embeddings related to quality assessment and out-of-distribution detection. We propose a new probabilistic speaker embedding extractor using the information encoded in the embedding magnitude and leverage it in the speaker verification pipeline. We also propose several quality-aware diarization methods and incorporate the magnitudes in those. Our results indicate significant improvements over magnitude-agnostic baselines both in speaker verification and diarization tasks.
Extrapolating false alarm rates in automatic speaker verification
Aug 08, 2020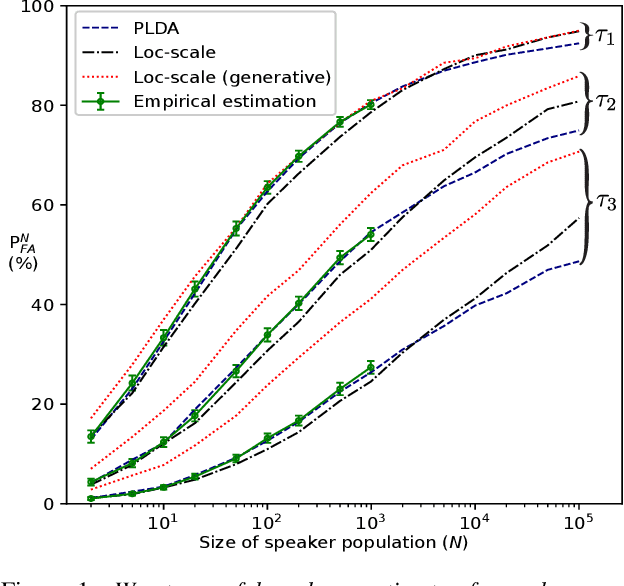

Automatic speaker verification (ASV) vendors and corpus providers would both benefit from tools to reliably extrapolate performance metrics for large speaker populations without collecting new speakers. We address false alarm rate extrapolation under a worst-case model whereby an adversary identifies the closest impostor for a given target speaker from a large population. Our models are generative and allow sampling new speakers. The models are formulated in the ASV detection score space to facilitate analysis of arbitrary ASV systems.
Voice Biometrics Security: Extrapolating False Alarm Rate via Hierarchical Bayesian Modeling of Speaker Verification Scores
Nov 04, 2019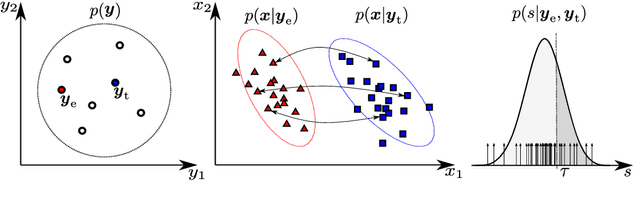
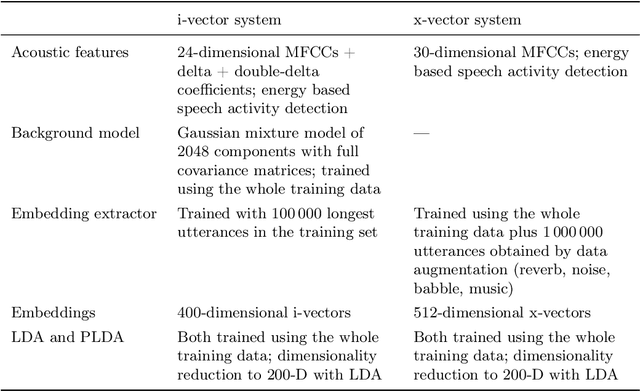
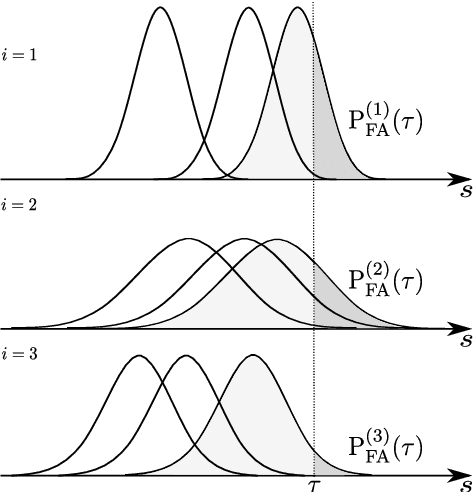

How secure automatic speaker verification (ASV) technology is? More concretely, given a specific target speaker, how likely is it to find another person who gets falsely accepted as that target? This question may be addressed empirically by studying naturally confusable pairs of speakers within a large enough corpus. To this end, one might expect to find at least some speaker pairs that are indistinguishable from each other in terms of ASV. To a certain extent, such aim is mirrored in the standardized ASV evaluation benchmarks. However, the number of speakers in such evaluation benchmarks represents only a small fraction of all possible human voices, making it challenging to extrapolate performance beyond a given corpus. Furthermore, the impostors used in performance evaluation are usually selected randomly. A potentially more meaningful definition of an impostor - at least in the context of security-driven ASV applications - would be closest (most confusable) other speaker to a given target. We put forward a novel performance assessment framework to address both the inadequacy of the random-impostor evaluation model and the size limitation of evaluation corpora by addressing ASV security against closest impostors on arbitrarily large datasets. The framework allows one to make a prediction of the safety of given ASV technology, in its current state, for arbitrarily large speaker database size consisting of virtual (sampled) speakers. As a proof-of-concept, we analyze the performance of two state-of-the-art ASV systems, based on i-vector and x-vector speaker embeddings (as implemented in the popular Kaldi toolkit), on the recent VoxCeleb 1 & 2 corpora. We found that neither the i-vector or x-vector system is immune to increased false alarm rate at increased impostor database size.