 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFROST-EMA: Finnish and Russian Oral Speech Dataset of Electromagnetic Articulography Measurements with L1, L2 and Imitated L2 Accents
Jun 10, 2025We introduce a new FROST-EMA (Finnish and Russian Oral Speech Dataset of Electromagnetic Articulography) corpus. It consists of 18 bilingual speakers, who produced speech in their native language (L1), second language (L2), and imitated L2 (fake foreign accent). The new corpus enables research into language variability from phonetic and technological points of view. Accordingly, we include two preliminary case studies to demonstrate both perspectives. The first case study explores the impact of L2 and imitated L2 on the performance of an automatic speaker verification system, while the second illustrates the articulatory patterns of one speaker in L1, L2, and a fake accent.
How to Construct Perfect and Worse-than-Coin-Flip Spoofing Countermeasures: A Word of Warning on Shortcut Learning
May 31, 2023Shortcut learning, or `Clever Hans effect` refers to situations where a learning agent (e.g., deep neural networks) learns spurious correlations present in data, resulting in biased models. We focus on finding shortcuts in deep learning based spoofing countermeasures (CMs) that predict whether a given utterance is spoofed or not. While prior work has addressed specific data artifacts, such as silence, no general normative framework has been explored for analyzing shortcut learning in CMs. In this study, we propose a generic approach to identifying shortcuts by introducing systematic interventions on the training and test sides, including the boundary cases of `near-perfect` and `worse than coin flip` (label flip). By using three different models, ranging from classic to state-of-the-art, we demonstrate the presence of shortcut learning in five simulated conditions. We analyze the results using a regression model to understand how biases affect the class-conditional score statistics.
Improving speaker de-identification with functional data analysis of f0 trajectories
Mar 31, 2022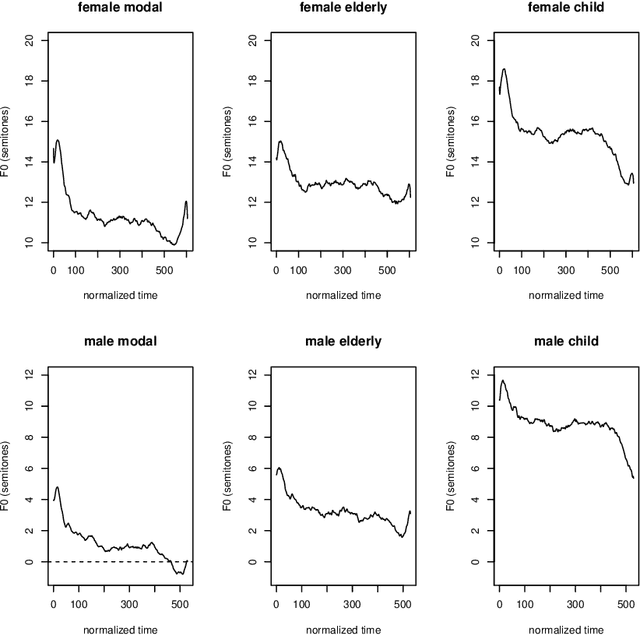
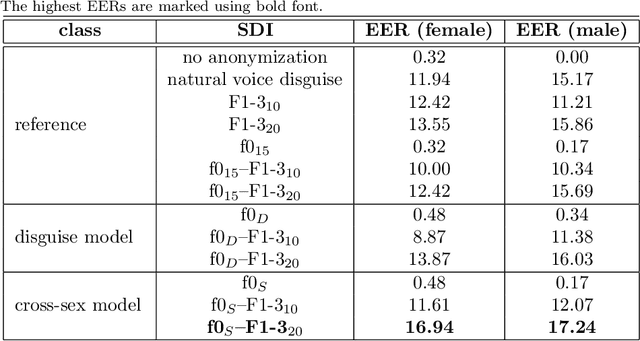
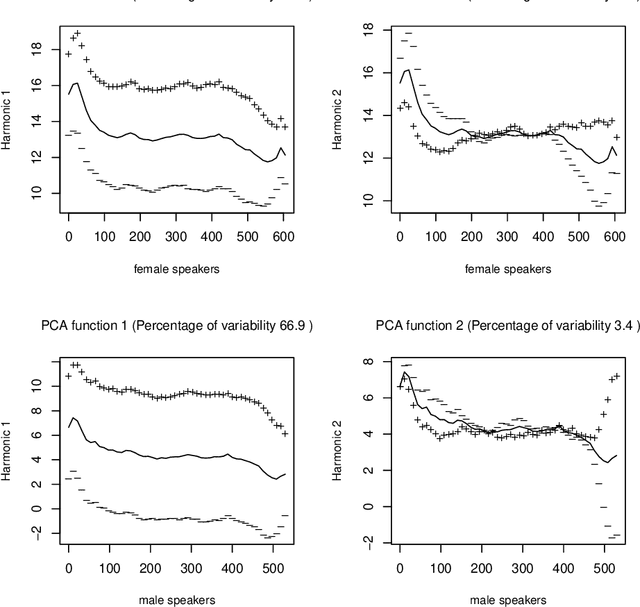
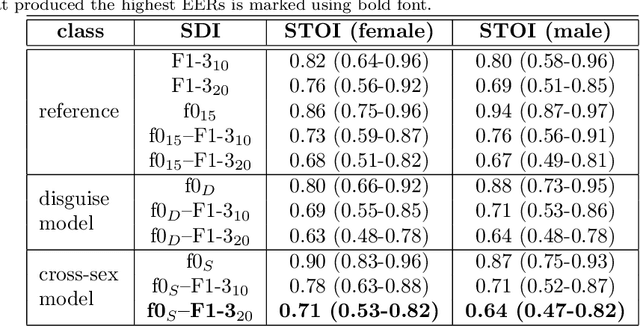
Due to a constantly increasing amount of speech data that is stored in different types of databases, voice privacy has become a major concern. To respond to such concern, speech researchers have developed various methods for speaker de-identification. The state-of-the-art solutions utilize deep learning solutions which can be effective but might be unavailable or impractical to apply for, for example, under-resourced languages. Formant modification is a simpler, yet effective method for speaker de-identification which requires no training data. Still, remaining intonational patterns in formant-anonymized speech may contain speaker-dependent cues. This study introduces a novel speaker de-identification method, which, in addition to simple formant shifts, manipulates f0 trajectories based on functional data analysis. The proposed speaker de-identification method will conceal plausibly identifying pitch characteristics in a phonetically controllable manner and improve formant-based speaker de-identification up to 25%.
Data Quality as Predictor of Voice Anti-Spoofing Generalization
Mar 26, 2021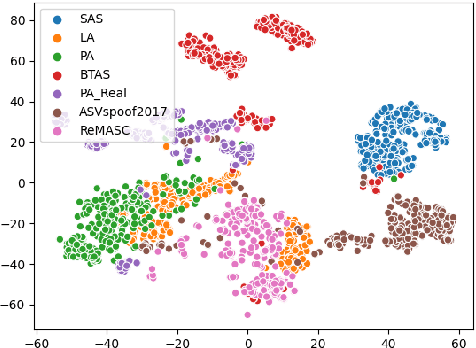
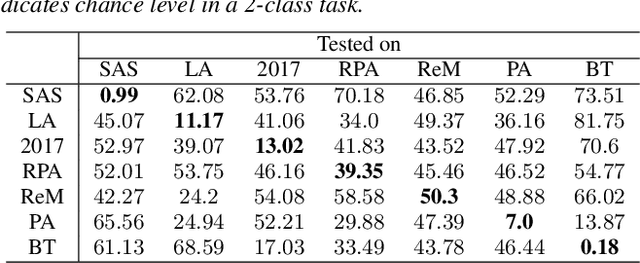
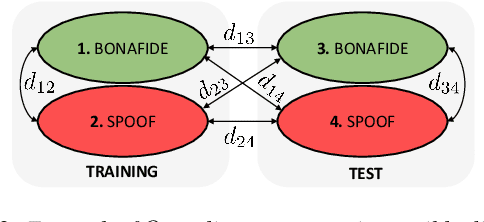
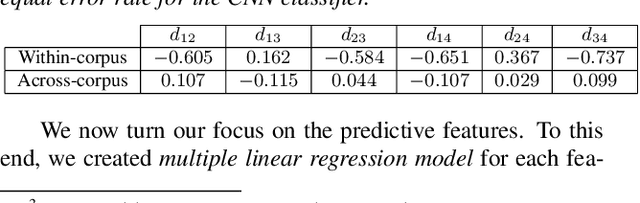
Voice anti-spoofing aims at classifying a given speech input either as a bonafide human sample, or a spoofing attack (e.g. synthetic or replayed sample). Numerous voice anti-spoofing methods have been proposed but most of them fail to generalize across domains (corpora) -- and we do not know \emph{why}. We outline a novel interpretative framework for gauging the impact of data quality upon anti-spoofing performance. Our within- and between-domain experiments pool data from seven public corpora and three anti-spoofing methods based on Gaussian mixture and convolutive neural network models. We assess the impacts of long-term spectral information, speaker population (through x-vector speaker embeddings), signal-to-noise ratio, and selected voice quality features.
Voice Mimicry Attacks Assisted by Automatic Speaker Verification
Jun 03, 2019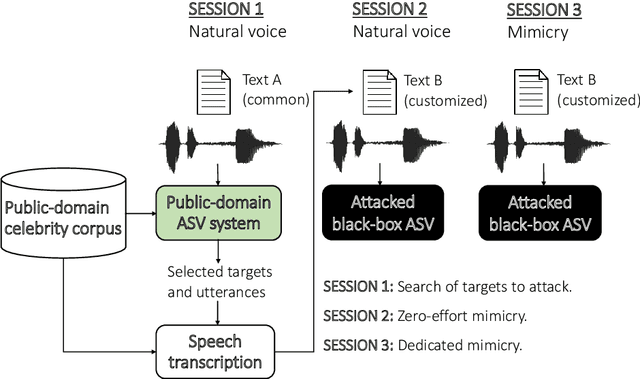

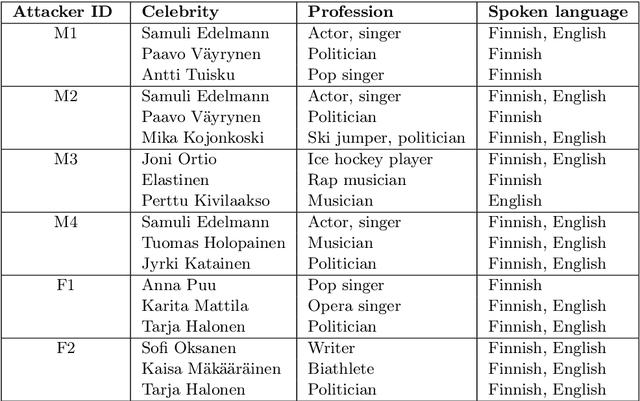
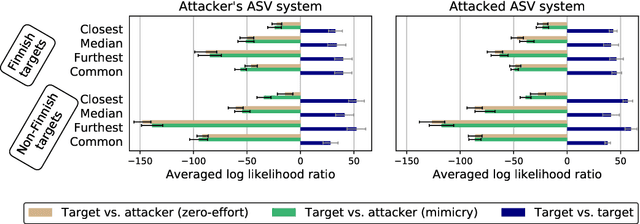
In this work, we simulate a scenario, where a publicly available ASV system is used to enhance mimicry attacks against another closed source ASV system. In specific, ASV technology is used to perform a similarity search between the voices of recruited attackers (6) and potential target speakers (7,365) from VoxCeleb corpora to find the closest targets for each of the attackers. In addition, we consider 'median', 'furthest', and 'common' targets to serve as a reference points. Our goal is to gain insights how well similarity rankings transfer from the attacker's ASV system to the attacked ASV system, whether the attackers are able to improve their attacks by mimicking, and how the properties of the voices of attackers change due to mimicking. We address these questions through ASV experiments, listening tests, and prosodic and formant analyses. For the ASV experiments, we use i-vector technology in the attacker side, and x-vectors in the attacked side. For the listening tests, we recruit listeners through crowdsourcing. The results of the ASV experiments indicate that the speaker similarity scores transfer well from one ASV system to another. Both the ASV experiments and the listening tests reveal that the mimicry attempts do not, in general, help in bringing attacker's scores closer to the target's. A detailed analysis shows that mimicking does not improve attacks, when the natural voices of attackers and targets are similar to each other. The analysis of prosody and formants suggests that the attackers were able to considerably change their speaking rates when mimicking, but the changes in F0 and formants were modest. Overall, the results suggest that untrained impersonators do not pose a high threat towards ASV systems, but the use of ASV systems to attack other ASV systems is a potential threat.
Can We Use Speaker Recognition Technology to Attack Itself? Enhancing Mimicry Attacks Using Automatic Target Speaker Selection
Nov 09, 2018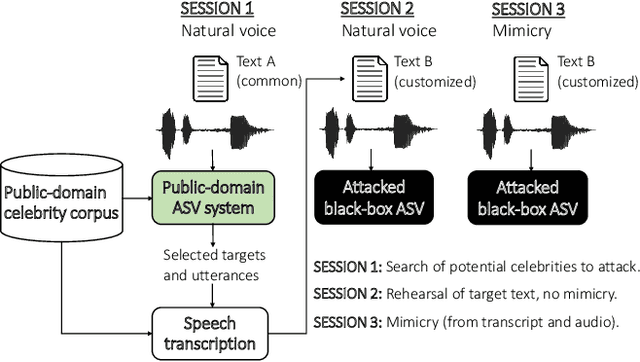

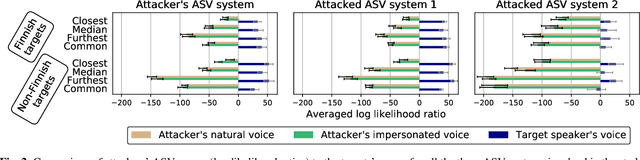

We consider technology-assisted mimicry attacks in the context of automatic speaker verification (ASV). We use ASV itself to select targeted speakers to be attacked by human-based mimicry. We recorded 6 naive mimics for whom we select target celebrities from VoxCeleb1 and VoxCeleb2 corpora (7,365 potential targets) using an i-vector system. The attacker attempts to mimic the selected target, with the utterances subjected to ASV tests using an independently developed x-vector system. Our main finding is negative: even if some of the attacker scores against the target speakers were slightly increased, our mimics did not succeed in spoofing the x-vector system. Interestingly, however, the relative ordering of the selected targets (closest, furthest, median) are consistent between the systems, which suggests some level of transferability between the systems.