 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Quality as Predictor of Voice Anti-Spoofing Generalization
Mar 26, 2021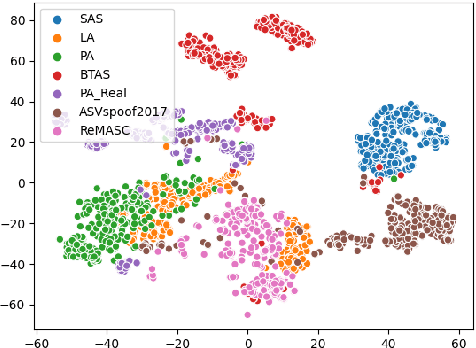
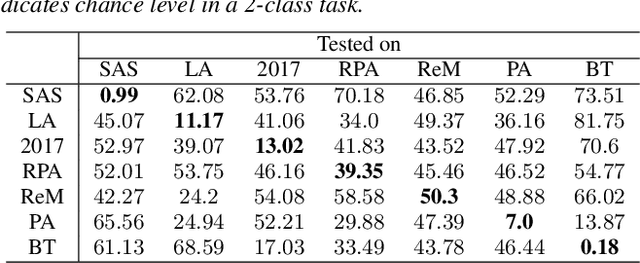
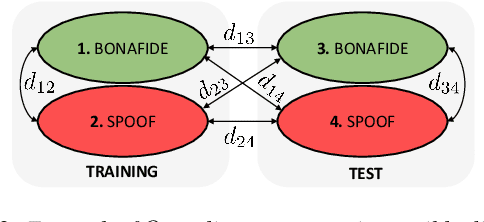
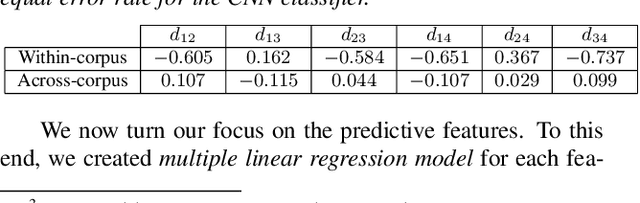
Voice anti-spoofing aims at classifying a given speech input either as a bonafide human sample, or a spoofing attack (e.g. synthetic or replayed sample). Numerous voice anti-spoofing methods have been proposed but most of them fail to generalize across domains (corpora) -- and we do not know \emph{why}. We outline a novel interpretative framework for gauging the impact of data quality upon anti-spoofing performance. Our within- and between-domain experiments pool data from seven public corpora and three anti-spoofing methods based on Gaussian mixture and convolutive neural network models. We assess the impacts of long-term spectral information, speaker population (through x-vector speaker embeddings), signal-to-noise ratio, and selected voice quality features.