 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-VLA: True Autoregressive Action Expert for Vision-Language-Action Models
Mar 10, 2026We propose a standalone autoregressive (AR) Action Expert that generates actions as a continuous causal sequence while conditioning on refreshable vision-language prefixes. In contrast to existing Vision-Language-Action (VLA) models and diffusion policies that reset temporal context with each new observation and predict actions reactively, our Action Expert maintains its own history through a long-lived memory and is inherently context-aware. This structure addresses the frequency mismatch between fast control and slow reasoning, enabling efficient independent pretraining of kinematic syntax and modular integration with heavy perception backbones, naturally ensuring spatio-temporally consistent action generation across frames. To synchronize these asynchronous hybrid V-L-A modalities, we utilize a re-anchoring mechanism that mathematically accounts for perception staleness during both training and inference. Experiments on simulated and real-robot manipulation tasks demonstrate that the proposed method can effectively replace traditional chunk-based action heads for both specialist and generalist policies. AR-VLA exhibits superior history awareness and substantially smoother action trajectories while maintaining or exceeding the task success rates of state-of-the-art reactive VLAs. Overall, our work introduces a scalable, context-aware action generation schema that provides a robust structural foundation for training effective robotic policies.
NeRF-based Visualization of 3D Cues Supporting Data-Driven Spacecraft Pose Estimation
Sep 18, 2025On-orbit operations require the estimation of the relative 6D pose, i.e., position and orientation, between a chaser spacecraft and its target. While data-driven spacecraft pose estimation methods have been developed, their adoption in real missions is hampered by the lack of understanding of their decision process. This paper presents a method to visualize the 3D visual cues on which a given pose estimator relies. For this purpose, we train a NeRF-based image generator using the gradients back-propagated through the pose estimation network. This enforces the generator to render the main 3D features exploited by the spacecraft pose estimation network. Experiments demonstrate that our method recovers the relevant 3D cues. Furthermore, they offer additional insights on the relationship between the pose estimation network supervision and its implicit representation of the target spacecraft.
Train a Multi-Task Diffusion Policy on RLBench-18 in One Day with One GPU
May 14, 2025We present a method for training multi-task vision-language robotic diffusion policies that reduces training time and memory usage by an order of magnitude. This improvement arises from a previously underexplored distinction between action diffusion and the image diffusion techniques that inspired it: image generation targets are high-dimensional, while robot actions lie in a much lower-dimensional space. Meanwhile, the vision-language conditions for action generation remain high-dimensional. Our approach, Mini-Diffuser, exploits this asymmetry by introducing Level-2 minibatching, which pairs multiple noised action samples with each vision-language condition, instead of the conventional one-to-one sampling strategy. To support this batching scheme, we introduce architectural adaptations to the diffusion transformer that prevent information leakage across samples while maintaining full conditioning access. In RLBench simulations, Mini-Diffuser achieves 95\% of the performance of state-of-the-art multi-task diffusion policies, while using only 5\% of the training time and 7\% of the memory. Real-world experiments further validate that Mini-Diffuser preserves the key strengths of diffusion-based policies, including the ability to model multimodal action distributions and produce behavior conditioned on diverse perceptual inputs. Code available at github.com/utomm/mini-diffuse-actor.
Domain Generalization for 6D Pose Estimation Through NeRF-based Image Synthesis
Jul 15, 2024



This work introduces a novel augmentation method that increases the diversity of a train set to improve the generalization abilities of a 6D pose estimation network. For this purpose, a Neural Radiance Field is trained from synthetic images and exploited to generate an augmented set. Our method enriches the initial set by enabling the synthesis of images with (i) unseen viewpoints, (ii) rich illumination conditions through appearance extrapolation, and (iii) randomized textures. We validate our augmentation method on the challenging use-case of spacecraft pose estimation and show that it significantly improves the pose estimation generalization capabilities. On the SPEED+ dataset, our method reduces the error on the pose by 50% on both target domains.
Domain Generalization for In-Orbit 6D Pose Estimation
Jun 17, 2024



We address the problem of estimating the relative 6D pose, i.e., position and orientation, of a target spacecraft, from a monocular image, a key capability for future autonomous Rendezvous and Proximity Operations. Due to the difficulty of acquiring large sets of real images, spacecraft pose estimation networks are exclusively trained on synthetic ones. However, because those images do not capture the illumination conditions encountered in orbit, pose estimation networks face a domain gap problem, i.e., they do not generalize to real images. Our work introduces a method that bridges this domain gap. It relies on a novel, end-to-end, neural-based architecture as well as a novel learning strategy. This strategy improves the domain generalization abilities of the network through multi-task learning and aggressive data augmentation policies, thereby enforcing the network to learn domain-invariant features. We demonstrate that our method effectively closes the domain gap, achieving state-of-the-art accuracy on the widespread SPEED+ dataset. Finally, ablation studies assess the impact of key components of our method on its generalization abilities.
Leveraging Neural Radiance Fields for Pose Estimation of an Unknown Space Object during Proximity Operations
May 21, 2024



We address the estimation of the 6D pose of an unknown target spacecraft relative to a monocular camera, a key step towards the autonomous rendezvous and proximity operations required by future Active Debris Removal missions. We present a novel method that enables an "off-the-shelf" spacecraft pose estimator, which is supposed to known the target CAD model, to be applied on an unknown target. Our method relies on an in-the wild NeRF, i.e., a Neural Radiance Field that employs learnable appearance embeddings to represent varying illumination conditions found in natural scenes. We train the NeRF model using a sparse collection of images that depict the target, and in turn generate a large dataset that is diverse both in terms of viewpoint and illumination. This dataset is then used to train the pose estimation network. We validate our method on the Hardware-In-the-Loop images of SPEED+ that emulate lighting conditions close to those encountered on orbit. We demonstrate that our method successfully enables the training of an off-the-shelf spacecraft pose estimation network from a sparse set of images. Furthermore, we show that a network trained using our method performs similarly to a model trained on synthetic images generated using the CAD model of the target.
Robot Trajectron: Trajectory Prediction-based Shared Control for Robot Manipulation
Feb 04, 2024



We address the problem of (a) predicting the trajectory of an arm reaching motion, based on a few seconds of the motion's onset, and (b) leveraging this predictor to facilitate shared-control manipulation tasks, easing the cognitive load of the operator by assisting them in their anticipated direction of motion. Our novel intent estimator, dubbed the \emph{Robot Trajectron} (RT), produces a probabilistic representation of the robot's anticipated trajectory based on its recent position, velocity and acceleration history. Taking arm dynamics into account allows RT to capture the operator's intent better than other SOTA models that only use the arm's position, making it particularly well-suited to assist in tasks where the operator's intent is susceptible to change. We derive a novel shared-control solution that combines RT's predictive capacity to a representation of the locations of potential reaching targets. Our experiments demonstrate RT's effectiveness in both intent estimation and shared-control tasks. We will make the code and data supporting our experiments publicly available at https://github.com/mousecpn/Robot-Trajectron.git.
Machine Vision based Sample-Tube Localization for Mars Sample Return
Mar 17, 2021

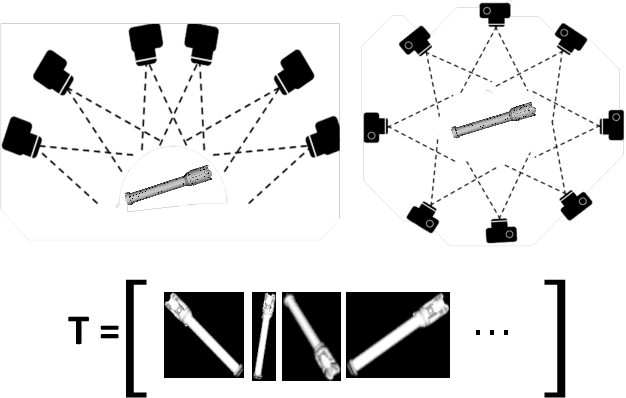
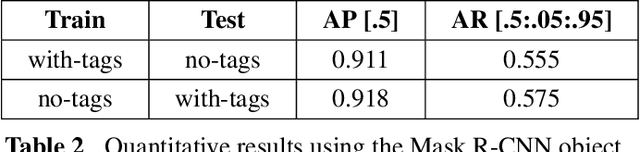
A potential Mars Sample Return (MSR) architecture is being jointly studied by NASA and ESA. As currently envisioned, the MSR campaign consists of a series of 3 missions: sample cache, fetch and return to Earth. In this paper, we focus on the fetch part of the MSR, and more specifically the problem of autonomously detecting and localizing sample tubes deposited on the Martian surface. Towards this end, we study two machine-vision based approaches: First, a geometry-driven approach based on template matching that uses hard-coded filters and a 3D shape model of the tube; and second, a data-driven approach based on convolutional neural networks (CNNs) and learned features. Furthermore, we present a large benchmark dataset of sample-tube images, collected in representative outdoor environments and annotated with ground truth segmentation masks and locations. The dataset was acquired systematically across different terrain, illumination conditions and dust-coverage; and benchmarking was performed to study the feasibility of each approach, their relative strengths and weaknesses, and robustness in the presence of adverse environmental conditions.
Rover Relocalization for Mars Sample Return by Virtual Template Synthesis and Matching
Mar 05, 2021
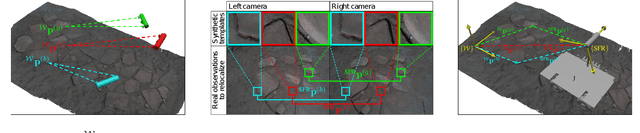

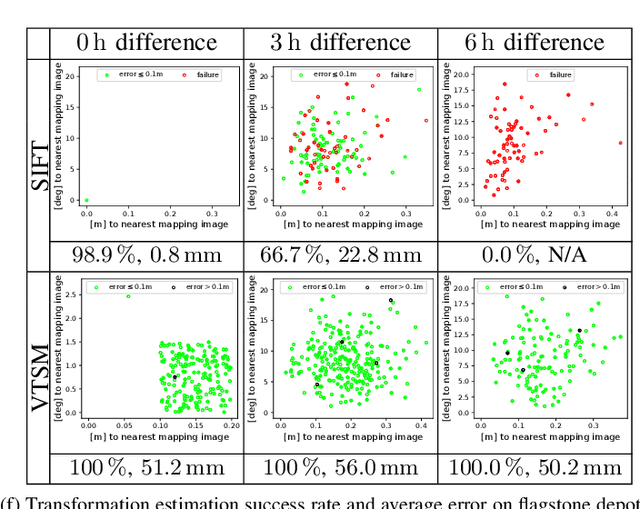
We consider the problem of rover relocalization in the context of the notional Mars Sample Return campaign. In this campaign, a rover (R1) needs to be capable of autonomously navigating and localizing itself within an area of approximately 50 x 50 m using reference images collected years earlier by another rover (R0). We propose a visual localizer that exhibits robustness to the relatively barren terrain that we expect to find in relevant areas, and to large lighting and viewpoint differences between R0 and R1. The localizer synthesizes partial renderings of a mesh built from reference R0 images and matches those to R1 images. We evaluate our method on a dataset totaling 2160 images covering the range of expected environmental conditions (terrain, lighting, approach angle). Experimental results show the effectiveness of our approach. This work informs the Mars Sample Return campaign on the choice of a site where Perseverance (R0) will place a set of sample tubes for future retrieval by another rover (R1).
Assistive Relative Pose Estimation for On-orbit Assembly using Convolutional Neural Networks
Feb 19, 2020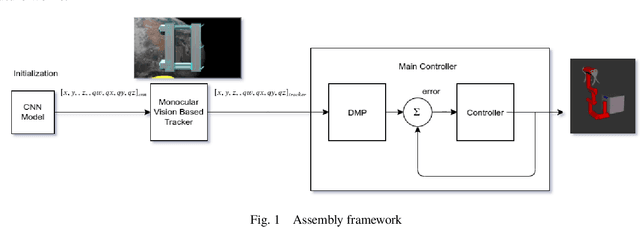
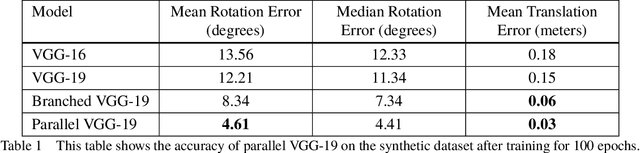


Accurate real-time pose estimation of spacecraft or object in space is a key capability necessary for on-orbit spacecraft servicing and assembly tasks. Pose estimation of objects in space is more challenging than for objects on Earth due to space images containing widely varying illumination conditions, high contrast, and poor resolution in addition to power and mass constraints. In this paper, a convolutional neural network is leveraged to uniquely determine the translation and rotation of an object of interest relative to the camera. The main idea of using CNN model is to assist object tracker used in on space assembly tasks where only feature based method is always not sufficient. The simulation framework designed for assembly task is used to generate dataset for training the modified CNN models and, then results of different models are compared with measure of how accurately models are predicting the pose. Unlike many current approaches for spacecraft or object in space pose estimation, the model does not rely on hand-crafted object-specific features which makes this model more robust and easier to apply to other types of spacecraft. It is shown that the model performs comparable to the current feature-selection methods and can therefore be used in conjunction with them to provide more reliable estimates.