 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiSCo: Signal Synthesis for Effective Human-Robot Communication Via Large Language Models
Sep 20, 2024

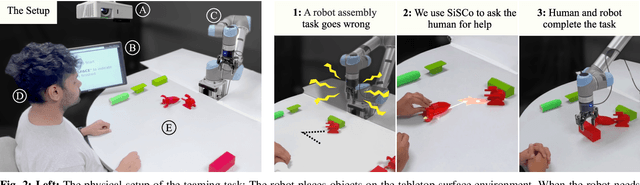

Effective human-robot collaboration hinges on robust communication channels, with visual signaling playing a pivotal role due to its intuitive appeal. Yet, the creation of visually intuitive cues often demands extensive resources and specialized knowledge. The emergence of Large Language Models (LLMs) offers promising avenues for enhancing human-robot interactions and revolutionizing the way we generate context-aware visual cues. To this end, we introduce SiSCo--a novel framework that combines the computational power of LLMs with mixed-reality technologies to streamline the creation of visual cues for human-robot collaboration. Our results show that SiSCo improves the efficiency of communication in human-robot teaming tasks, reducing task completion time by approximately 73% and increasing task success rates by 18% compared to baseline natural language signals. Additionally, SiSCo reduces cognitive load for participants by 46%, as measured by the NASA-TLX subscale, and receives above-average user ratings for on-the-fly signals generated for unseen objects. To encourage further development and broader community engagement, we provide full access to SiSCo's implementation and related materials on our GitHub repository.
iRoCo: Intuitive Robot Control From Anywhere Using a Smartwatch
Mar 11, 2024



This paper introduces iRoCo (intuitive Robot Control) - a framework for ubiquitous human-robot collaboration using a single smartwatch and smartphone. By integrating probabilistic differentiable filters, iRoCo optimizes a combination of precise robot control and unrestricted user movement from ubiquitous devices. We demonstrate and evaluate the effectiveness of iRoCo in practical teleoperation and drone piloting applications. Comparative analysis shows no significant difference between task performance with iRoCo and gold-standard control systems in teleoperation tasks. Additionally, iRoCo users complete drone piloting tasks 32\% faster than with a traditional remote control and report less frustration in a subjective load index questionnaire. Our findings strongly suggest that iRoCo is a promising new approach for intuitive robot control through smartwatches and smartphones from anywhere, at any time. The code is available at www.github.com/wearable-motion-capture
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Projecting Robot Intentions Through Visual Cues: Static vs. Dynamic Signaling
Aug 19, 2023Augmented and mixed-reality techniques harbor a great potential for improving human-robot collaboration. Visual signals and cues may be projected to a human partner in order to explicitly communicate robot intentions and goals. However, it is unclear what type of signals support such a process and whether signals can be combined without adding additional cognitive stress to the partner. This paper focuses on identifying the effective types of visual signals and quantify their impact through empirical evaluations. In particular, the study compares static and dynamic visual signals within a collaborative object sorting task and assesses their ability to shape human behavior. Furthermore, an information-theoretic analysis is performed to numerically quantify the degree of information transfer between visual signals and human behavior. The results of a human subject experiment show that there are significant advantages to combining multiple visual signals within a single task, i.e., increased task efficiency and reduced cognitive load.
Anytime, Anywhere: Human Arm Pose from Smartwatch Data for Ubiquitous Robot Control and Teleoperation
Jun 22, 2023This work devises an optimized machine learning approach for human arm pose estimation from a single smartwatch. Our approach results in a distribution of possible wrist and elbow positions, which allows for a measure of uncertainty and the detection of multiple possible arm posture solutions, i.e., multimodal pose distributions. Combining estimated arm postures with speech recognition, we turn the smartwatch into a ubiquitous, low-cost and versatile robot control interface. We demonstrate in two use-cases that this intuitive control interface enables users to swiftly intervene in robot behavior, to temporarily adjust their goal, or to train completely new control policies by imitation. Extensive experiments show that the approach results in a 40% reduction in prediction error over the current state-of-the-art and achieves a mean error of 2.56cm for wrist and elbow positions.
Imitation Learning based Auto-Correction of Extrinsic Parameters for A Mixed-Reality Setup
Dec 16, 2022
In this paper, we discuss an imitation learning based method for reducing the calibration error for a mixed reality system consisting of a vision sensor and a projector. Unlike a head mounted display, in this setup, augmented information is available to a human subject via the projection of a scene into the real world. Inherently, the camera and projector need to be calibrated as a stereo setup to project accurate information in 3D space. Previous calibration processes require multiple recording and parameter tuning steps to achieve the desired calibration, which is usually time consuming process. In order to avoid such tedious calibration, we train a CNN model to iteratively correct the extrinsic offset given a QR code and a projected pattern. We discuss the overall system setup, data collection for training, and results of the auto-correction model.
Modularity through Attention: Efficient Training and Transfer of Language-Conditioned Policies for Robot Manipulation
Dec 08, 2022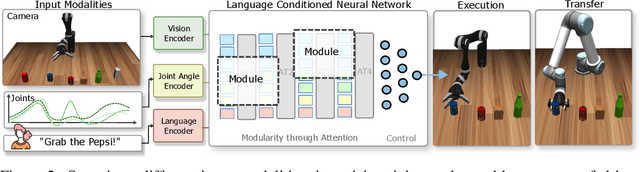

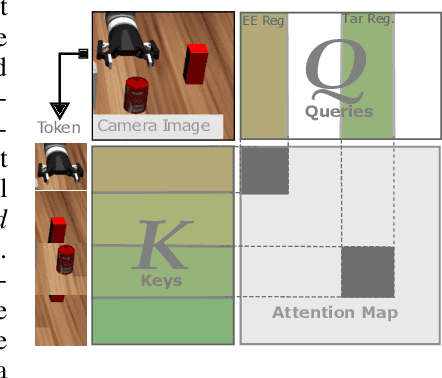

Language-conditioned policies allow robots to interpret and execute human instructions. Learning such policies requires a substantial investment with regards to time and compute resources. Still, the resulting controllers are highly device-specific and cannot easily be transferred to a robot with different morphology, capability, appearance or dynamics. In this paper, we propose a sample-efficient approach for training language-conditioned manipulation policies that allows for rapid transfer across different types of robots. By introducing a novel method, namely Hierarchical Modularity, and adopting supervised attention across multiple sub-modules, we bridge the divide between modular and end-to-end learning and enable the reuse of functional building blocks. In both simulated and real world robot manipulation experiments, we demonstrate that our method outperforms the current state-of-the-art methods and can transfer policies across 4 different robots in a sample-efficient manner. Finally, we show that the functionality of learned sub-modules is maintained beyond the training process and can be used to introspect the robot decision-making process. Code is available at https://github.com/ir-lab/ModAttn.
Multimodal Data Fusion for Power-On-and-GoRobotic Systems in Retail
Mar 23, 2021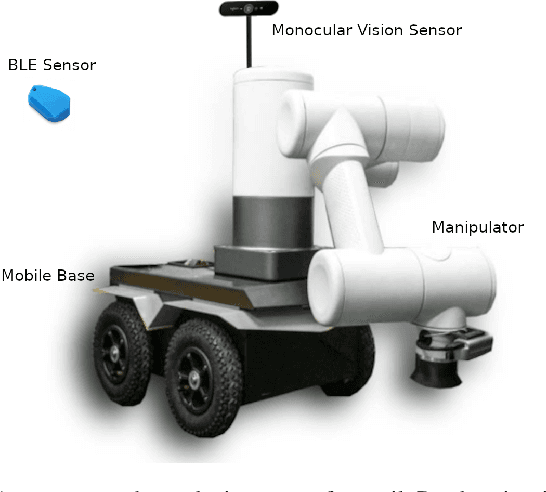
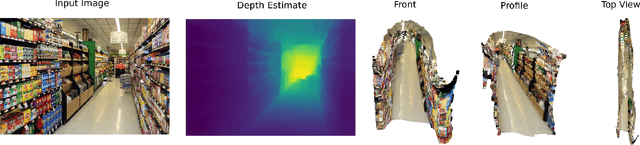
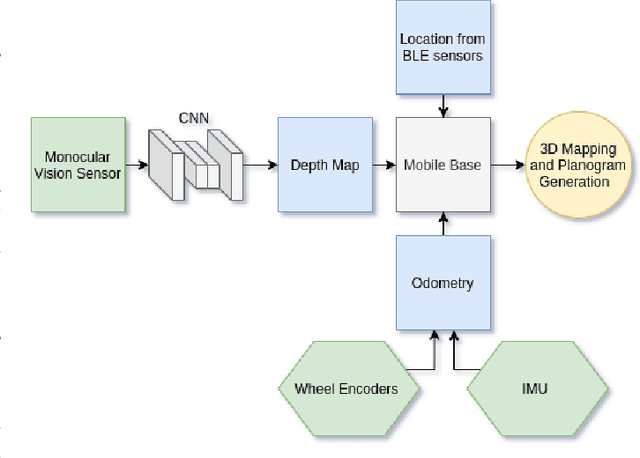

Robotic systems for retail have gained a lot of attention due to the labor-intensive nature of such business environments. Many tasks have the potential to be automated via intelligent robotic systems that have manipulation capabilities. For example, empty shelves can be replenished, stray products can be picked up or new items can be delivered. However, many challenges make the realization of this vision a challenge. In particular, robots are still too expensive and do not work out of the box. In this paper, we discuss a work-in-progress approach for enabling power-on-and-go robots in retail environments through a combination of active, physical sensors and passive, artificial sensors. In particular, we use low-cost hardware sensors in conjunction with machine learning techniques in order to generate high-quality environmental information. More specifically, we present a setup in which a standard monocular camera and Bluetooth low-energy yield a reliable robot system that can immediately be used after placing a couple of sensors in the environment. The camera information is used to synthesize accurate 3D point clouds, whereas the BLE data is used to integrate the data into a complex map of the environment. The combination of active and passive sensing enables high-quality sensing capabilities at a fraction of the costs traditionally associated with such tasks.
Assistive Relative Pose Estimation for On-orbit Assembly using Convolutional Neural Networks
Feb 19, 2020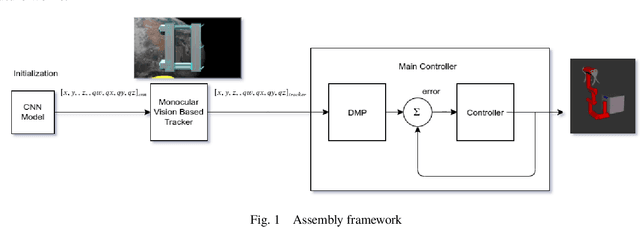
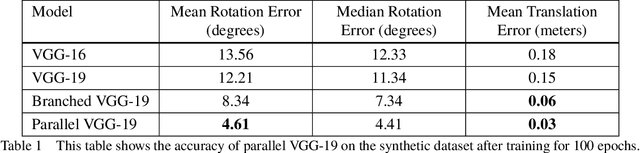


Accurate real-time pose estimation of spacecraft or object in space is a key capability necessary for on-orbit spacecraft servicing and assembly tasks. Pose estimation of objects in space is more challenging than for objects on Earth due to space images containing widely varying illumination conditions, high contrast, and poor resolution in addition to power and mass constraints. In this paper, a convolutional neural network is leveraged to uniquely determine the translation and rotation of an object of interest relative to the camera. The main idea of using CNN model is to assist object tracker used in on space assembly tasks where only feature based method is always not sufficient. The simulation framework designed for assembly task is used to generate dataset for training the modified CNN models and, then results of different models are compared with measure of how accurately models are predicting the pose. Unlike many current approaches for spacecraft or object in space pose estimation, the model does not rely on hand-crafted object-specific features which makes this model more robust and easier to apply to other types of spacecraft. It is shown that the model performs comparable to the current feature-selection methods and can therefore be used in conjunction with them to provide more reliable estimates.