 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Token Selection for Aerial-Ground Person Re-Identification
Nov 30, 2024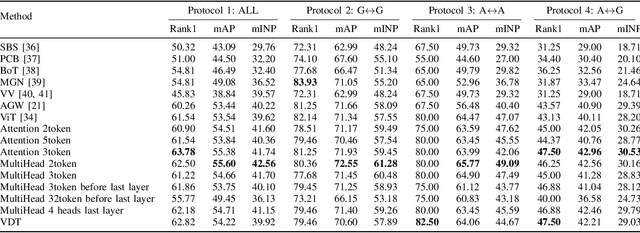
We propose a View-Decoupled Transformer (VDT) framework to address viewpoint discrepancies in person re-identification (ReID), particularly between aerial and ground views. VDT decouples view-specific and view-independent features by leveraging meta and view tokens, processed through self-attention and subtractive separation. Additionally, we introduce a Visual Token Selector (VTS) module that dynamically selects the most informative tokens, reducing redundancy and enhancing efficiency. Our approach significantly improves retrieval performance on the AGPReID dataset, while maintaining computational efficiency similar to baseline models.
Learning to Singulate Objects in Packed Environments using a Dexterous Hand
Sep 01, 2024



Robotic object singulation, where a robot must isolate, grasp, and retrieve a target object in a cluttered environment, is a fundamental challenge in robotic manipulation. This task is difficult due to occlusions and how other objects act as obstacles for manipulation. A robot must also reason about the effect of object-object interactions as it tries to singulate the target. Prior work has explored object singulation in scenarios where there is enough free space to perform relatively long pushes to separate objects, in contrast to when space is tight and objects have little separation from each other. In this paper, we propose the Singulating Objects in Packed Environments (SOPE) framework. We propose a novel method that involves a displacement-based state representation and a multi-phase reinforcement learning procedure that enables singulation using the 16-DOF Allegro Hand. We demonstrate extensive experiments in Isaac Gym simulation, showing the ability of our system to singulate a target object in clutter. We directly transfer the policy trained in simulation to the real world. Over 250 physical robot manipulation trials, our method obtains success rates of 79.2%, outperforming alternative learning and non-learning methods.
Blending Distributed NeRFs with Tri-stage Robust Pose Optimization
May 05, 2024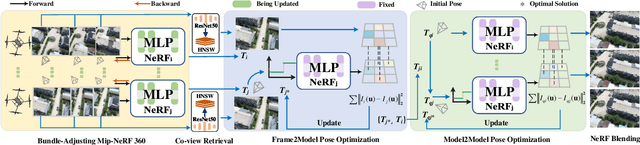
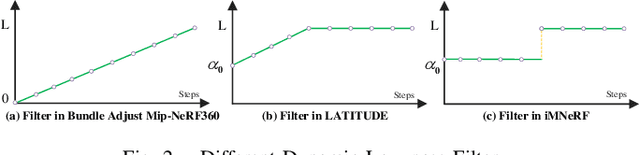

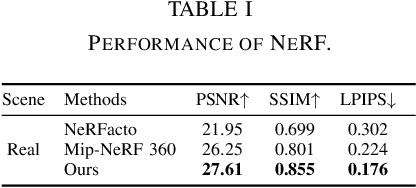
Due to the limited model capacity, leveraging distributed Neural Radiance Fields (NeRFs) for modeling extensive urban environments has become a necessity. However, current distributed NeRF registration approaches encounter aliasing artifacts, arising from discrepancies in rendering resolutions and suboptimal pose precision. These factors collectively deteriorate the fidelity of pose estimation within NeRF frameworks, resulting in occlusion artifacts during the NeRF blending stage. In this paper, we present a distributed NeRF system with tri-stage pose optimization. In the first stage, precise poses of images are achieved by bundle adjusting Mip-NeRF 360 with a coarse-to-fine strategy. In the second stage, we incorporate the inverting Mip-NeRF 360, coupled with the truncated dynamic low-pass filter, to enable the achievement of robust and precise poses, termed Frame2Model optimization. On top of this, we obtain a coarse transformation between NeRFs in different coordinate systems. In the third stage, we fine-tune the transformation between NeRFs by Model2Model pose optimization. After obtaining precise transformation parameters, we proceed to implement NeRF blending, showcasing superior performance metrics in both real-world and simulation scenarios. Codes and data will be publicly available at https://github.com/boilcy/Distributed-NeRF.