Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Token Selection for Aerial-Ground Person Re-Identification
Paper and Code
Nov 30, 2024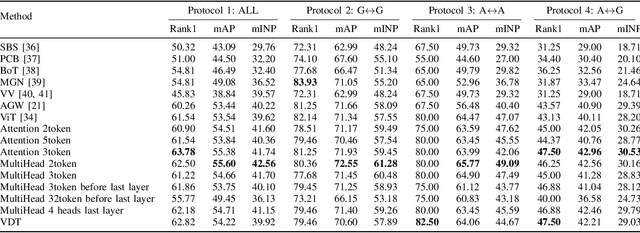
We propose a View-Decoupled Transformer (VDT) framework to address viewpoint discrepancies in person re-identification (ReID), particularly between aerial and ground views. VDT decouples view-specific and view-independent features by leveraging meta and view tokens, processed through self-attention and subtractive separation. Additionally, we introduce a Visual Token Selector (VTS) module that dynamically selects the most informative tokens, reducing redundancy and enhancing efficiency. Our approach significantly improves retrieval performance on the AGPReID dataset, while maintaining computational efficiency similar to baseline models.
View paper on