 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEARL: Geometry Aligns Semantics for Training-Free Open-Vocabulary Semantic Segmentation
Mar 23, 2026Training-free open-vocabulary semantic segmentation (OVSS) promises rapid adaptation to new label sets without retraining. Yet, many methods rely on heavy post-processing or handle text and vision in isolation, leaving cross-modal geometry underutilized. Others introduce auxiliary vision backbones or multi-model pipelines, which increase complexity and latency while compromising design simplicity. We present PEARL, \textbf{\underline{P}}rocrust\textbf{\underline{e}}s \textbf{\underline{a}}lignment with text-awa\textbf{\underline{r}}e \textbf{\underline{L}}aplacian propagation, a compact two-step inference that follows an align-then-propagate principle. The Procrustes alignment step performs an orthogonal projection inside the last self-attention block, rotating keys toward the query subspace via a stable polar iteration. The text-aware Laplacian propagation then refines per-pixel logits on a small grid through a confidence-weighted, text-guided graph solve: text provides both a data-trust signal and neighbor gating, while image gradients preserve boundaries. In this work, our method is fully training-free, plug-and-play, and uses only fixed constants, adding minimal latency with a small per-head projection and a few conjugate-gradient steps. Our approach, PEARL, sets a new state-of-the-art in training-free OVSS without extra data or auxiliary backbones across standard benchmarks, achieving superior performance under both with-background and without-background protocols.
Taming SAM3 in the Wild: A Concept Bank for Open-Vocabulary Segmentation
Feb 06, 2026The recent introduction of \texttt{SAM3} has revolutionized Open-Vocabulary Segmentation (OVS) through \textit{promptable concept segmentation}, which grounds pixel predictions in flexible concept prompts. However, this reliance on pre-defined concepts makes the model vulnerable: when visual distributions shift (\textit{data drift}) or conditional label distributions evolve (\textit{concept drift}) in the target domain, the alignment between visual evidence and prompts breaks down. In this work, we present \textsc{ConceptBank}, a parameter-free calibration framework to restore this alignment on the fly. Instead of adhering to static prompts, we construct a dataset-specific concept bank from the target statistics. Our approach (\textit{i}) anchors target-domain evidence via class-wise visual prototypes, (\textit{ii}) mines representative supports to suppress outliers under data drift, and (\textit{iii}) fuses candidate concepts to rectify concept drift. We demonstrate that \textsc{ConceptBank} effectively adapts \texttt{SAM3} to distribution drifts, including challenging natural-scene and remote-sensing scenarios, establishing a new baseline for robustness and efficiency in OVS. Code and model are available at https://github.com/pgsmall/ConceptBank.
Anti-Collapse Loss for Deep Metric Learning Based on Coding Rate Metric
Jul 03, 2024Deep metric learning (DML) aims to learn a discriminative high-dimensional embedding space for downstream tasks like classification, clustering, and retrieval. Prior literature predominantly focuses on pair-based and proxy-based methods to maximize inter-class discrepancy and minimize intra-class diversity. However, these methods tend to suffer from the collapse of the embedding space due to their over-reliance on label information. This leads to sub-optimal feature representation and inferior model performance. To maintain the structure of embedding space and avoid feature collapse, we propose a novel loss function called Anti-Collapse Loss. Specifically, our proposed loss primarily draws inspiration from the principle of Maximal Coding Rate Reduction. It promotes the sparseness of feature clusters in the embedding space to prevent collapse by maximizing the average coding rate of sample features or class proxies. Moreover, we integrate our proposed loss with pair-based and proxy-based methods, resulting in notable performance improvement. Comprehensive experiments on benchmark datasets demonstrate that our proposed method outperforms existing state-of-the-art methods. Extensive ablation studies verify the effectiveness of our method in preventing embedding space collapse and promoting generalization performance.
Scale-Invariant Feature Disentanglement via Adversarial Learning for UAV-based Object Detection
May 24, 2024
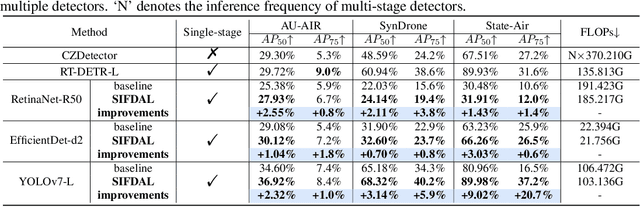
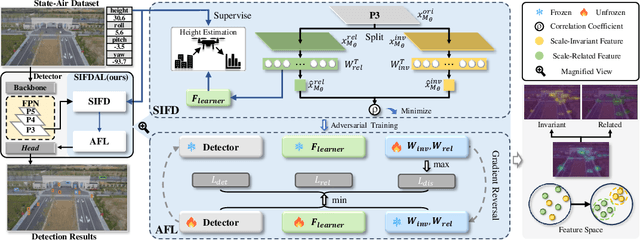

Detecting objects from Unmanned Aerial Vehicles (UAV) is often hindered by a large number of small objects, resulting in low detection accuracy. To address this issue, mainstream approaches typically utilize multi-stage inferences. Despite their remarkable detecting accuracies, real-time efficiency is sacrificed, making them less practical to handle real applications. To this end, we propose to improve the single-stage inference accuracy through learning scale-invariant features. Specifically, a Scale-Invariant Feature Disentangling module is designed to disentangle scale-related and scale-invariant features. Then an Adversarial Feature Learning scheme is employed to enhance disentanglement. Finally, scale-invariant features are leveraged for robust UAV-based object detection. Furthermore, we construct a multi-modal UAV object detection dataset, State-Air, which incorporates annotated UAV state parameters. We apply our approach to three state-of-the-art lightweight detection frameworks on three benchmark datasets, including State-Air. Extensive experiments demonstrate that our approach can effectively improve model accuracy. Our code and dataset are provided in Supplementary Materials and will be publicly available once the paper is accepted.
A Light-weight Transformer-based Self-supervised Matching Network for Heterogeneous Images
Apr 30, 2024



Matching visible and near-infrared (NIR) images remains a significant challenge in remote sensing image fusion. The nonlinear radiometric differences between heterogeneous remote sensing images make the image matching task even more difficult. Deep learning has gained substantial attention in computer vision tasks in recent years. However, many methods rely on supervised learning and necessitate large amounts of annotated data. Nevertheless, annotated data is frequently limited in the field of remote sensing image matching. To address this challenge, this paper proposes a novel keypoint descriptor approach that obtains robust feature descriptors via a self-supervised matching network. A light-weight transformer network, termed as LTFormer, is designed to generate deep-level feature descriptors. Furthermore, we implement an innovative triplet loss function, LT Loss, to enhance the matching performance further. Our approach outperforms conventional hand-crafted local feature descriptors and proves equally competitive compared to state-of-the-art deep learning-based methods, even amidst the shortage of annotated data.
VideoMAC: Video Masked Autoencoders Meet ConvNets
Feb 29, 2024Recently, the advancement of self-supervised learning techniques, like masked autoencoders (MAE), has greatly influenced visual representation learning for images and videos. Nevertheless, it is worth noting that the predominant approaches in existing masked image / video modeling rely excessively on resource-intensive vision transformers (ViTs) as the feature encoder. In this paper, we propose a new approach termed as \textbf{VideoMAC}, which combines video masked autoencoders with resource-friendly ConvNets. Specifically, VideoMAC employs symmetric masking on randomly sampled pairs of video frames. To prevent the issue of mask pattern dissipation, we utilize ConvNets which are implemented with sparse convolutional operators as encoders. Simultaneously, we present a simple yet effective masked video modeling (MVM) approach, a dual encoder architecture comprising an online encoder and an exponential moving average target encoder, aimed to facilitate inter-frame reconstruction consistency in videos. Additionally, we demonstrate that VideoMAC, empowering classical (ResNet) / modern (ConvNeXt) convolutional encoders to harness the benefits of MVM, outperforms ViT-based approaches on downstream tasks, including video object segmentation (+\textbf{5.2\%} / \textbf{6.4\%} $\mathcal{J}\&\mathcal{F}$), body part propagation (+\textbf{6.3\%} / \textbf{3.1\%} mIoU), and human pose tracking (+\textbf{10.2\%} / \textbf{11.1\%} PCK@0.1).
Holistic Prototype Attention Network for Few-Shot VOS
Jul 16, 2023



Few-shot video object segmentation (FSVOS) aims to segment dynamic objects of unseen classes by resorting to a small set of support images that contain pixel-level object annotations. Existing methods have demonstrated that the domain agent-based attention mechanism is effective in FSVOS by learning the correlation between support images and query frames. However, the agent frame contains redundant pixel information and background noise, resulting in inferior segmentation performance. Moreover, existing methods tend to ignore inter-frame correlations in query videos. To alleviate the above dilemma, we propose a holistic prototype attention network (HPAN) for advancing FSVOS. Specifically, HPAN introduces a prototype graph attention module (PGAM) and a bidirectional prototype attention module (BPAM), transferring informative knowledge from seen to unseen classes. PGAM generates local prototypes from all foreground features and then utilizes their internal correlations to enhance the representation of the holistic prototypes. BPAM exploits the holistic information from support images and video frames by fusing co-attention and self-attention to achieve support-query semantic consistency and inner-frame temporal consistency. Extensive experiments on YouTube-FSVOS have been provided to demonstrate the effectiveness and superiority of our proposed HPAN method.