 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Enabled Adaptive Multi-Task Control for Bipedal Soccer Robots
Apr 21, 2026Developing bipedal football robots in dynamiccombat environments presents challenges related to motionstability and deep coupling of multiple tasks, as well ascontrol switching issues between different states such as up-right walking and fall recovery. To address these problems,this paper proposes a modular reinforcement learning (RL)framework for achieving adaptive multi-task control. Firstly,this framework combines an open-loop feedforward oscilla-tor with a reinforcement learning-based feedback residualstrategy, effectively separating the generation of basic gaitsfrom complex football actions. Secondly, a posture-driven statemachine is introduced, clearly switching between the ballseeking and kicking network (BSKN) and the fall recoverynetwork (FRN), fundamentally preventing state interference.The FRN is efficiently trained through a progressive forceattenuation curriculum learning strategy. The architecture wasverified in Unity simulations of bipedal robots, demonstratingexcellent spatial adaptability-reliably finding and kicking theball even in restricted corner scenarios-and rapid autonomousfall recovery (with an average recovery time of 0.715 seconds).This ensures seamless and stable operation in complex multi-task environments.
Disentangle Object and Non-object Infrared Features via Language Guidance
Jan 14, 2026Infrared object detection focuses on identifying and locating objects in complex environments (\eg, dark, snow, and rain) where visible imaging cameras are disabled by poor illumination. However, due to low contrast and weak edge information in infrared images, it is challenging to extract discriminative object features for robust detection. To deal with this issue, we propose a novel vision-language representation learning paradigm for infrared object detection. An additional textual supervision with rich semantic information is explored to guide the disentanglement of object and non-object features. Specifically, we propose a Semantic Feature Alignment (SFA) module to align the object features with the corresponding text features. Furthermore, we develop an Object Feature Disentanglement (OFD) module that disentangles text-aligned object features and non-object features by minimizing their correlation. Finally, the disentangled object features are entered into the detection head. In this manner, the detection performance can be remarkably enhanced via more discriminative and less noisy features. Extensive experimental results demonstrate that our approach achieves superior performance on two benchmarks: M\textsuperscript{3}FD (83.7\% mAP), FLIR (86.1\% mAP). Our code will be publicly available once the paper is accepted.
Domain-invariant Progressive Knowledge Distillation for UAV-based Object Detection
Aug 21, 2024
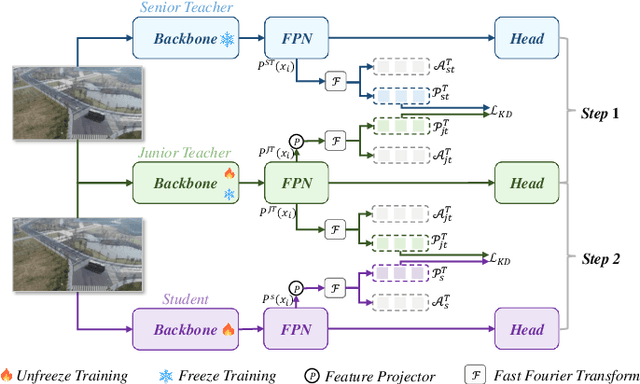
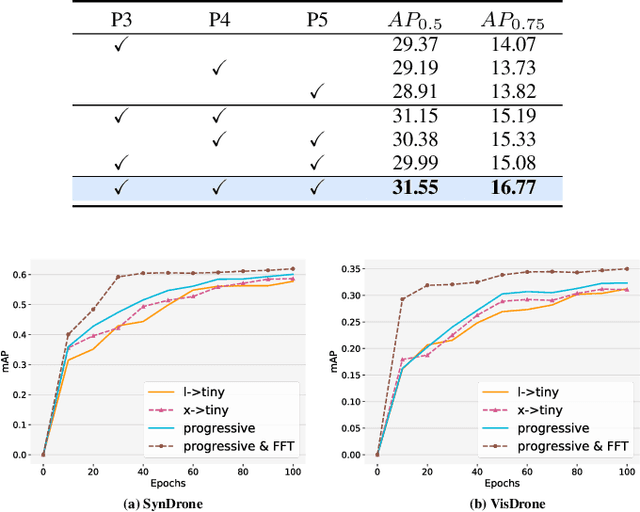
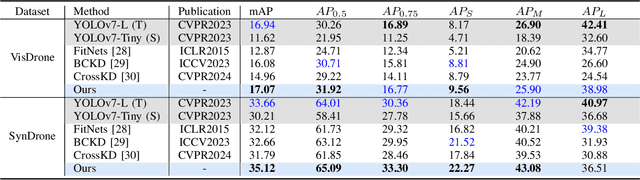
Knowledge distillation (KD) is an effective method for compressing models in object detection tasks. Due to limited computational capability, UAV-based object detection (UAV-OD) widely adopt the KD technique to obtain lightweight detectors. Existing methods often overlook the significant differences in feature space caused by the large gap in scale between the teacher and student models. This limitation hampers the efficiency of knowledge transfer during the distillation process. Furthermore, the complex backgrounds in UAV images make it challenging for the student model to efficiently learn the object features. In this paper, we propose a novel knowledge distillation framework for UAV-OD. Specifically, a progressive distillation approach is designed to alleviate the feature gap between teacher and student models. Then a new feature alignment method is provided to extract object-related features for enhancing student model's knowledge reception efficiency. Finally, extensive experiments are conducted to validate the effectiveness of our proposed approach. The results demonstrate that our proposed method achieves state-of-the-art (SoTA) performance in two UAV-OD datasets.
Fine-grained Metrics for Point Cloud Semantic Segmentation
Jul 31, 2024



Two forms of imbalances are commonly observed in point cloud semantic segmentation datasets: (1) category imbalances, where certain objects are more prevalent than others; and (2) size imbalances, where certain objects occupy more points than others. Because of this, the majority of categories and large objects are favored in the existing evaluation metrics. This paper suggests fine-grained mIoU and mAcc for a more thorough assessment of point cloud segmentation algorithms in order to address these issues. Richer statistical information is provided for models and datasets by these fine-grained metrics, which also lessen the bias of current semantic segmentation metrics towards large objects. The proposed metrics are used to train and assess various semantic segmentation algorithms on three distinct indoor and outdoor semantic segmentation datasets.
Progress or Regress? Self-Improvement Reversal in Post-training
Jul 06, 2024Self-improvement through post-training methods such as iterative preference learning has been acclaimed for enhancing the problem-solving capabilities (e.g., mathematical reasoning) of Large Language Models (LLMs) without human intervention. However, as exploration deepens, it becomes crucial to assess whether these improvements genuinely signify progress in solving more challenging problems or if they could lead to unintended regressions. To address this, we propose a comprehensive evaluative framework that goes beyond the superficial pass@1 metric to scrutinize the underlying enhancements of post-training paradigms for self-improvement. Through rigorous experimentation and analysis across diverse problem-solving tasks, the empirical results point out the phenomenon of \emph{self-improvement reversal}, where models showing improved performance across benchmarks will paradoxically exhibit declines in broader, essential capabilities, like output diversity and out-of-distribution (OOD) generalization. These findings indicate that current self-improvement practices through post-training are inadequate for equipping models to tackle more complex problems. Furthermore, they underscore the necessity of our critical evaluation metrics in discerning the \emph{progress or regress} dichotomy for self-improving LLMs.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024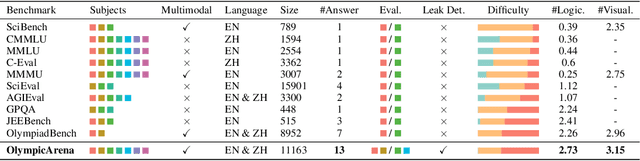
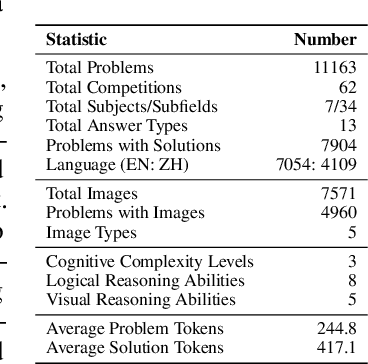
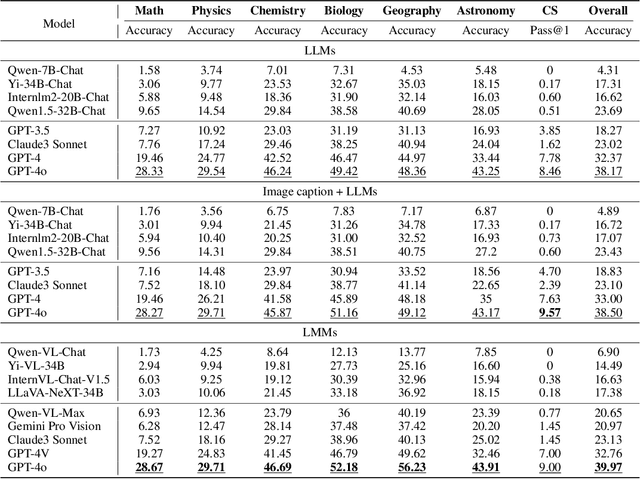
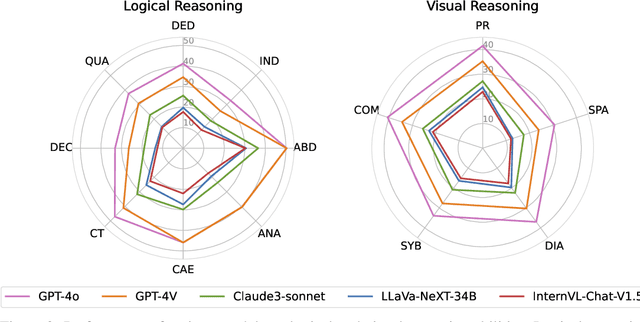
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.
UEMM-Air: A Synthetic Multi-modal Dataset for Unmanned Aerial Vehicle Object Detection
Jun 10, 2024



The development of multi-modal object detection for Unmanned Aerial Vehicles (UAVs) typically relies on a large amount of pixel-aligned multi-modal image data. However, existing datasets face challenges such as limited modalities, high construction costs, and imprecise annotations. To this end, we propose a synthetic multi-modal UAV-based object detection dataset, UEMM-Air. Specially, we simulate various UAV flight scenarios and object types using the Unreal Engine (UE). Then we design the UAV's flight logic to automatically collect data from different scenarios, perspectives, and altitudes. Finally, we propose a novel heuristic automatic annotation algorithm to generate accurate object detection labels. In total, our UEMM-Air consists of 20k pairs of images with 5 modalities and precise annotations. Moreover, we conduct numerous experiments and establish new benchmark results on our dataset. We found that models pre-trained on UEMM-Air exhibit better performance on downstream tasks compared to other similar datasets. The dataset is publicly available (https://github.com/1e12Leon/UEMM-Air) to support the research of multi-modal UAV object detection models.
Scale-Invariant Feature Disentanglement via Adversarial Learning for UAV-based Object Detection
May 24, 2024
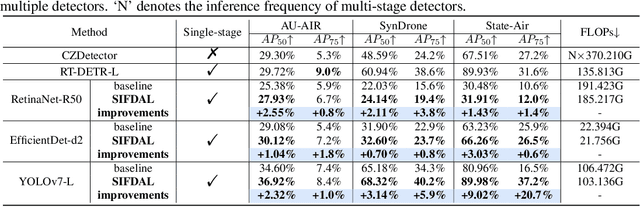
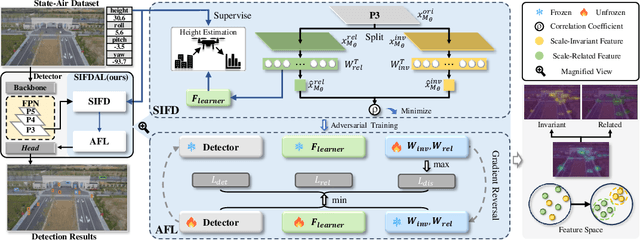

Detecting objects from Unmanned Aerial Vehicles (UAV) is often hindered by a large number of small objects, resulting in low detection accuracy. To address this issue, mainstream approaches typically utilize multi-stage inferences. Despite their remarkable detecting accuracies, real-time efficiency is sacrificed, making them less practical to handle real applications. To this end, we propose to improve the single-stage inference accuracy through learning scale-invariant features. Specifically, a Scale-Invariant Feature Disentangling module is designed to disentangle scale-related and scale-invariant features. Then an Adversarial Feature Learning scheme is employed to enhance disentanglement. Finally, scale-invariant features are leveraged for robust UAV-based object detection. Furthermore, we construct a multi-modal UAV object detection dataset, State-Air, which incorporates annotated UAV state parameters. We apply our approach to three state-of-the-art lightweight detection frameworks on three benchmark datasets, including State-Air. Extensive experiments demonstrate that our approach can effectively improve model accuracy. Our code and dataset are provided in Supplementary Materials and will be publicly available once the paper is accepted.
Refining Segmentation On-the-Fly: An Interactive Framework for Point Cloud Semantic Segmentation
Mar 11, 2024



Existing interactive point cloud segmentation approaches primarily focus on the object segmentation, which aim to determine which points belong to the object of interest guided by user interactions. This paper concentrates on an unexplored yet meaningful task, i.e., interactive point cloud semantic segmentation, which assigns high-quality semantic labels to all points in a scene with user corrective clicks. Concretely, we presents the first interactive framework for point cloud semantic segmentation, named InterPCSeg, which seamlessly integrates with off-the-shelf semantic segmentation networks without offline re-training, enabling it to run in an on-the-fly manner. To achieve online refinement, we treat user interactions as sparse training examples during the test-time. To address the instability caused by the sparse supervision, we design a stabilization energy to regulate the test-time training process. For objective and reproducible evaluation, we develop an interaction simulation scheme tailored for the interactive point cloud semantic segmentation task. We evaluate our framework on the S3DIS and ScanNet datasets with off-the-shelf segmentation networks, incorporating interactions from both the proposed interaction simulator and real users. Quantitative and qualitative experimental results demonstrate the efficacy of our framework in refining the semantic segmentation results with user interactions. The source code will be publicly available.
Modeling the Q-Diversity in a Min-max Play Game for Robust Optimization
May 20, 2023



Models trained with empirical risk minimization (ERM) are revealed to easily rely on spurious correlations, resulting in poor generalization. Group distributionally robust optimization (group DRO) can alleviate this problem by minimizing the worst-case loss over pre-defined groups. While promising, in practice factors like expensive annotations and privacy preclude the availability of group labels. More crucially, when taking a closer look at the failure modes of out-of-distribution generalization, the typical procedure of reweighting in group DRO loses efficiency. Hinged on the limitations, in this work, we reformulate the group DRO framework by proposing Q-Diversity. Characterized by an interactive training mode, Q-Diversity relaxes the group identification from annotation into direct parameterization. Furthermore, a novel mixing strategy across groups is presented to diversify the under-represented groups. In a series of experiments on both synthetic and real-world text classification tasks, results demonstrate that Q-Diversity can consistently improve worst-case accuracy under different distributional shifts, outperforming state-of-the-art alternatives.