 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMSnet 2.0: A Large AMS Database with AI Segmentation for Net Detection
May 14, 2025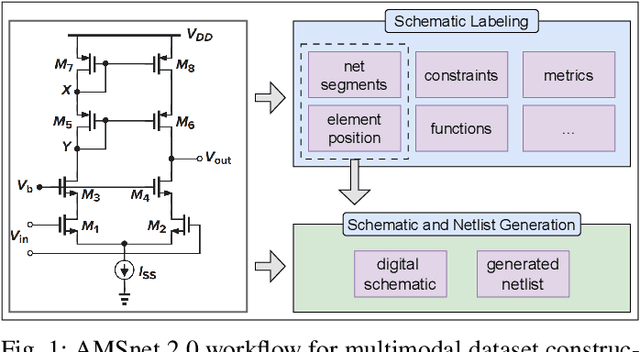
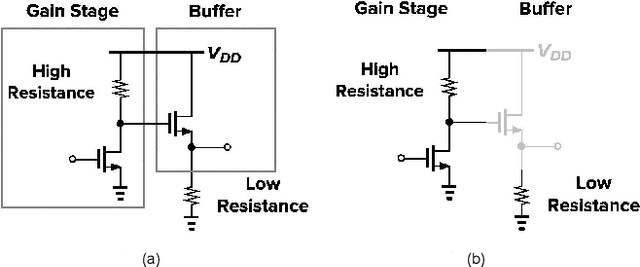
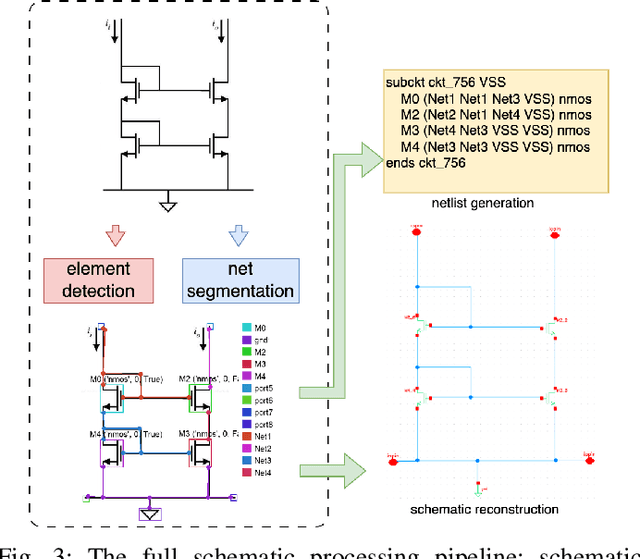
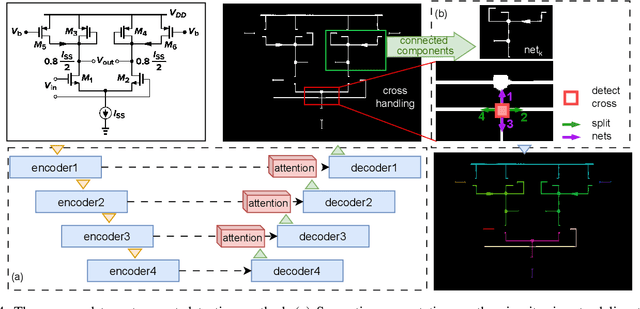
Current multimodal large language models (MLLMs) struggle to understand circuit schematics due to their limited recognition capabilities. This could be attributed to the lack of high-quality schematic-netlist training data. Existing work such as AMSnet applies schematic parsing to generate netlists. However, these methods rely on hard-coded heuristics and are difficult to apply to complex or noisy schematics in this paper. We therefore propose a novel net detection mechanism based on segmentation with high robustness. The proposed method also recovers positional information, allowing digital reconstruction of schematics. We then expand AMSnet dataset with schematic images from various sources and create AMSnet 2.0. AMSnet 2.0 contains 2,686 circuits with schematic images, Spectre-formatted netlists, OpenAccess digital schematics, and positional information for circuit components and nets, whereas AMSnet only includes 792 circuits with SPICE netlists but no digital schematics.
FaceShield: Explainable Face Anti-Spoofing with Multimodal Large Language Models
May 14, 2025
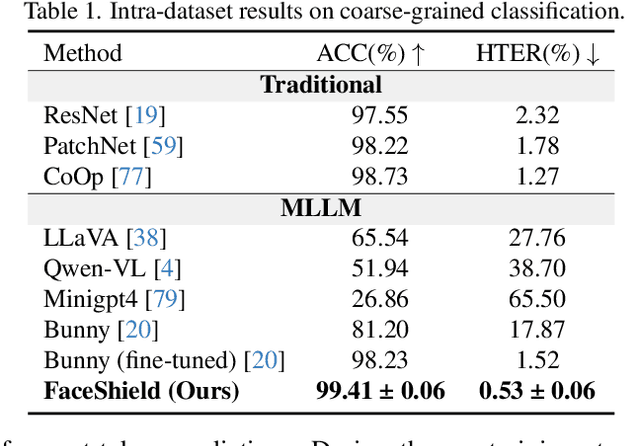
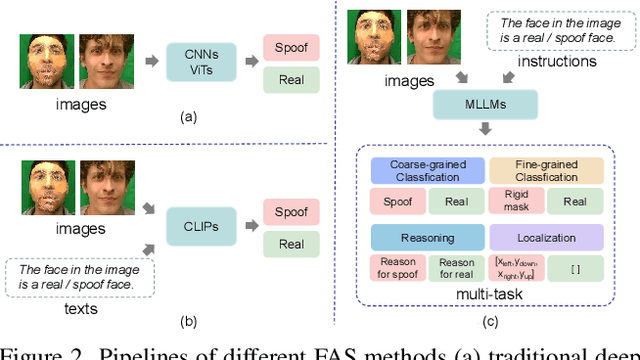
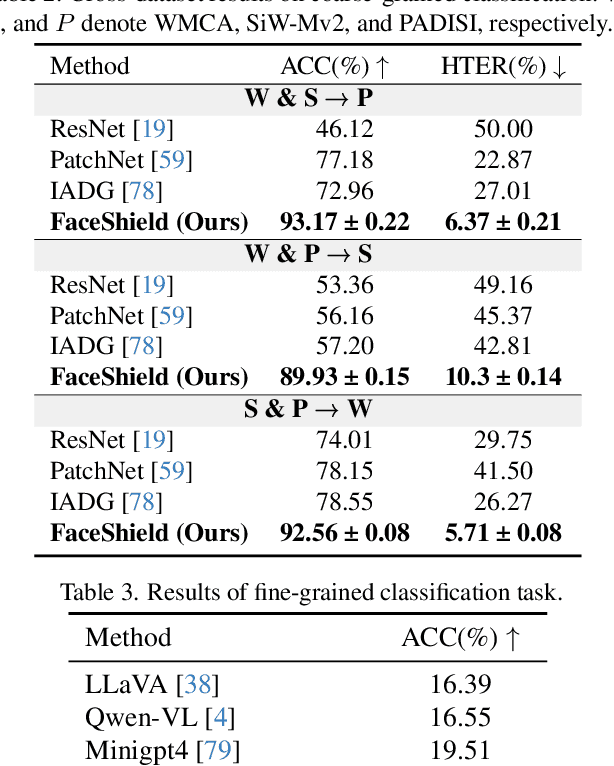
Face anti-spoofing (FAS) is crucial for protecting facial recognition systems from presentation attacks. Previous methods approached this task as a classification problem, lacking interpretability and reasoning behind the predicted results. Recently, multimodal large language models (MLLMs) have shown strong capabilities in perception, reasoning, and decision-making in visual tasks. However, there is currently no universal and comprehensive MLLM and dataset specifically designed for FAS task. To address this gap, we propose FaceShield, a MLLM for FAS, along with the corresponding pre-training and supervised fine-tuning (SFT) datasets, FaceShield-pre10K and FaceShield-sft45K. FaceShield is capable of determining the authenticity of faces, identifying types of spoofing attacks, providing reasoning for its judgments, and detecting attack areas. Specifically, we employ spoof-aware vision perception (SAVP) that incorporates both the original image and auxiliary information based on prior knowledge. We then use an prompt-guided vision token masking (PVTM) strategy to random mask vision tokens, thereby improving the model's generalization ability. We conducted extensive experiments on three benchmark datasets, demonstrating that FaceShield significantly outperforms previous deep learning models and general MLLMs on four FAS tasks, i.e., coarse-grained classification, fine-grained classification, reasoning, and attack localization. Our instruction datasets, protocols, and codes will be released soon.
AMSnet-KG: A Netlist Dataset for LLM-based AMS Circuit Auto-Design Using Knowledge Graph RAG
Nov 07, 2024



High-performance analog and mixed-signal (AMS) circuits are mainly full-custom designed, which is time-consuming and labor-intensive. A significant portion of the effort is experience-driven, which makes the automation of AMS circuit design a formidable challenge. Large language models (LLMs) have emerged as powerful tools for Electronic Design Automation (EDA) applications, fostering advancements in the automatic design process for large-scale AMS circuits. However, the absence of high-quality datasets has led to issues such as model hallucination, which undermines the robustness of automatically generated circuit designs. To address this issue, this paper introduces AMSnet-KG, a dataset encompassing various AMS circuit schematics and netlists. We construct a knowledge graph with annotations on detailed functional and performance characteristics. Facilitated by AMSnet-KG, we propose an automated AMS circuit generation framework that utilizes the comprehensive knowledge embedded in LLMs. We first formulate a design strategy (e.g., circuit architecture using a number of circuit components) based on required specifications. Next, matched circuit components are retrieved and assembled into a complete topology, and transistor sizing is obtained through Bayesian optimization. Simulation results of the netlist are fed back to the LLM for further topology refinement, ensuring the circuit design specifications are met. We perform case studies of operational amplifier and comparator design to verify the automatic design flow from specifications to netlists with minimal human effort. The dataset used in this paper will be open-sourced upon publishing of this paper.
Relating CNN-Transformer Fusion Network for Change Detection
Jul 03, 2024



While deep learning, particularly convolutional neural networks (CNNs), has revolutionized remote sensing (RS) change detection (CD), existing approaches often miss crucial features due to neglecting global context and incomplete change learning. Additionally, transformer networks struggle with low-level details. RCTNet addresses these limitations by introducing \textbf{(1)} an early fusion backbone to exploit both spatial and temporal features early on, \textbf{(2)} a Cross-Stage Aggregation (CSA) module for enhanced temporal representation, \textbf{(3)} a Multi-Scale Feature Fusion (MSF) module for enriched feature extraction in the decoder, and \textbf{(4)} an Efficient Self-deciphering Attention (ESA) module utilizing transformers to capture global information and fine-grained details for accurate change detection. Extensive experiments demonstrate RCTNet's clear superiority over traditional RS image CD methods, showing significant improvement and an optimal balance between accuracy and computational cost.
SHIELD : An Evaluation Benchmark for Face Spoofing and Forgery Detection with Multimodal Large Language Models
Feb 06, 2024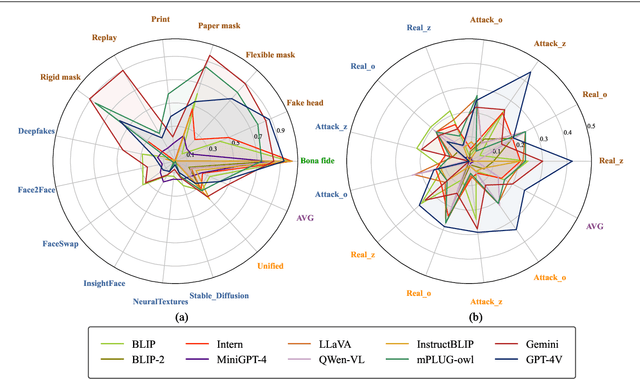
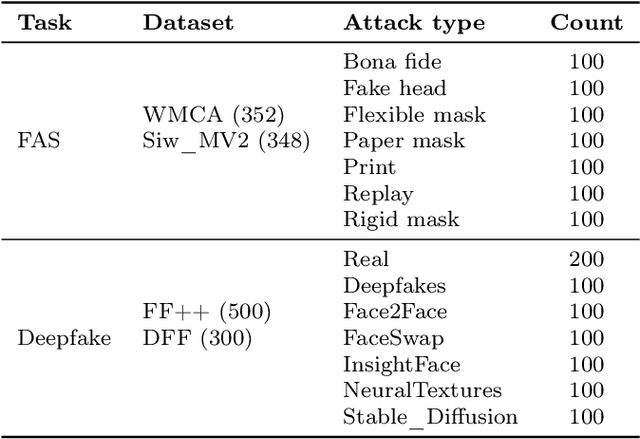

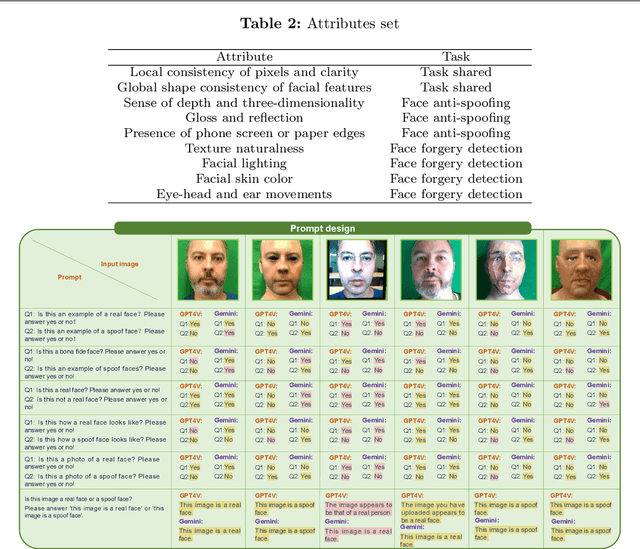
Multimodal large language models (MLLMs) have demonstrated remarkable problem-solving capabilities in various vision fields (e.g., generic object recognition and grounding) based on strong visual semantic representation and language reasoning ability. However, whether MLLMs are sensitive to subtle visual spoof/forged clues and how they perform in the domain of face attack detection (e.g., face spoofing and forgery detection) is still unexplored. In this paper, we introduce a new benchmark, namely SHIELD, to evaluate the ability of MLLMs on face spoofing and forgery detection. Specifically, we design true/false and multiple-choice questions to evaluate multimodal face data in these two face security tasks. For the face anti-spoofing task, we evaluate three different modalities (i.e., RGB, infrared, depth) under four types of presentation attacks (i.e., print attack, replay attack, rigid mask, paper mask). For the face forgery detection task, we evaluate GAN-based and diffusion-based data with both visual and acoustic modalities. Each question is subjected to both zero-shot and few-shot tests under standard and chain of thought (COT) settings. The results indicate that MLLMs hold substantial potential in the face security domain, offering advantages over traditional specific models in terms of interpretability, multimodal flexible reasoning, and joint face spoof and forgery detection. Additionally, we develop a novel Multi-Attribute Chain of Thought (MA-COT) paradigm for describing and judging various task-specific and task-irrelevant attributes of face images, which provides rich task-related knowledge for subtle spoof/forged clue mining. Extensive experiments in separate face anti-spoofing, separate face forgery detection, and joint detection tasks demonstrate the effectiveness of the proposed MA-COT. The project is available at https$:$//github.com/laiyingxin2/SHIELD