 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouchThinker: Scaling Tactile Commonsense Reasoning to the Open World with Large-scale Data and Action-aware Representation
Jun 10, 2026Touch is a key modality for embodied agents to understand the physical world. Although recent work has incorporated tactile signals into language systems for tactile commonsense reasoning, scaling such systems to realistic open-world settings remains challenging due to two key bottlenecks: (1) current tactile reasoning datasets remain limited in format and scale, providing insufficient supervision for reasoning from tactile observations to physical commonsense and hindering the learning of transferable tactile commonsense; (2) Tactile signals are inherently redundant and action-specific, yet existing methods often overlook these properties, resulting in inefficient representations with limited semantic expressiveness. To address these limitations, we propose TouchThinker, a tactile-language framework that scales tactile commonsense reasoning to the open world from both data and representation perspectives. First, we construct TouchThinker-1M, a million-scale, multi-source tactile reasoning dataset covering \textbf{415} objects, \textbf{8} scenarios, and \textbf{7} sensor types, providing a solid data foundation for open-world generalization. We further introduce TouchThinker-Bench, an open-world benchmark with more realistic and diverse tasks. Then, we propose action-aware modeling mechanism to improve tactile representation efficiency and enable efficient reasoning. Experimental results demonstrate that TouchThinker achieves competitive performance against state-of-the-art models across multiple datasets. Our code and dataset will be made available at: https://github.com/lvkailin0118/TouchThinker.
Adaptive Causal Alignment for High-Confidence Adversarial Training
Jun 02, 2026Inverse adversarial training leverages high-confidence predictions to stabilize robust learning, yet we uncover a critical paradox: high confidence often stems from overfitting to non-causal background correlations rather than intrinsic object semantics. Our investigation reveals that visual context functions as a dual-natured signal, serving as either a necessary supportive prior or a spurious confounder. This insight renders existing blind suppression strategies flawed, as they inevitably lead to severe Feature Loss. To resolve this, we propose High-Confidence Causally Aligned Training (HICAT), a unified framework that establishes a Semantic Equilibrium. Operating on a ``Measure-Debias-Align'' pipeline, HICAT integrates a Learnable Background-Bias Estimator (LBBE) to adaptively diagnose context utility. Guided by this diagnosis, an Adaptive Debiasing mechanism performs surgical logit rectification, complemented by a geometrically grounded Foreground Logit Orthogonal Enhancement (FLOE) loss to enforce rigorous feature disentanglement. Extensive experiments on CIFAR-10, CIFAR-100, and ImageNet-1K demonstrate that HICAT consistently improves over matched baselines across diverse architectures (CNNs and ViTs) while significantly reducing the robust generalization gap.
Touch-R1: Reinforcing Touch Reasoning in MLLMs
May 26, 2026While rule-based reinforcement learning has recently catalyzed explicit reasoning in multimodal models, tactile reasoning remains largely underexplored. Existing tactile-language models primarily rely on supervised or contrastive objectives, which limits their capacity to ground predictions in physical evidence or rectify misleading visual priors. Tactile reasoning introduces two modality-specific challenges: the ordinal nature of physical attributes (e.g., hardness, roughness) and the cross-sensor distribution shifts inherent in optical tactile hardware. In this work, we introduce TouchReason-1M, a large-scale multimodal dataset comprising over 1M synchronized tactile pairs across four distinct sensors, and TouchReason-Bench, a rigorous framework for evaluating tactile perception and visual-tactile conflict resolution. Building upon these, we propose Touch-R1, a tactile reasoning MLLM based on Qwen2.5-VL-7B. Touch-R1 is trained via a tactile-grounded GRPO objective that combines ordinal-aware accuracy, cross-sensor physical consistency, structured-format control, and an input-side tactile grounding objective. Specifically, the tactile-use reward assigns credit only when authentic tactile inputs yield superior correctness relative to counterfactual controls where the tactile stream is removed, shuffled, or noise-masked. On TouchReason-Bench, Touch-R1-7B outperforms Octopi-13B by 18.4\% and GPT-4o by 24.7\% on average. Its structured reasoning traces reveal emergent behaviors of probing, comparison, and revision, demonstrating that R1-style reasoning can be effectively grounded in physical contact.
ForensicZip: More Tokens are Better but Not Necessary in Forensic Vision-Language Models
Mar 12, 2026Multimodal Large Language Models (MLLMs) enable interpretable multimedia forensics by generating textual rationales for forgery detection. However, processing dense visual sequences incurs high computational costs, particularly for high-resolution images and videos. Visual token pruning is a practical acceleration strategy, yet existing methods are largely semantic-driven, retaining salient objects while discarding background regions where manipulation traces such as high-frequency anomalies and temporal jitters often reside. To address this issue, we introduce ForensicZip, a training-free framework that reformulates token compression from a forgery-driven perspective. ForensicZip models temporal token evolution as a Birth-Death Optimal Transport problem with a slack dummy node, quantifying physical discontinuities indicating transient generative artifacts. The forensic scoring further integrates transport-based novelty with high-frequency priors to separate forensic evidence from semantic content under large-ratio compression. Experiments on deepfake and AIGC benchmarks show that at 10\% token retention, ForensicZip achieves $2.97\times$ speedup and over 90\% FLOPs reduction while maintaining state-of-the-art detection performance.
Agent4FaceForgery: Multi-Agent LLM Framework for Realistic Face Forgery Detection
Sep 16, 2025Face forgery detection faces a critical challenge: a persistent gap between offline benchmarks and real-world efficacy,which we attribute to the ecological invalidity of training data.This work introduces Agent4FaceForgery to address two fundamental problems: (1) how to capture the diverse intents and iterative processes of human forgery creation, and (2) how to model the complex, often adversarial, text-image interactions that accompany forgeries in social media. To solve this,we propose a multi-agent framework where LLM-poweredagents, equipped with profile and memory modules, simulate the forgery creation process. Crucially, these agents interact in a simulated social environment to generate samples labeled for nuanced text-image consistency, moving beyond simple binary classification. An Adaptive Rejection Sampling (ARS) mechanism ensures data quality and diversity. Extensive experiments validate that the data generated by our simulationdriven approach brings significant performance gains to detectors of multiple architectures, fully demonstrating the effectiveness and value of our framework.
HCCM: Hierarchical Cross-Granularity Contrastive and Matching Learning for Natural Language-Guided Drones
Aug 29, 2025Natural Language-Guided Drones (NLGD) provide a novel paradigm for tasks such as target matching and navigation. However, the wide field of view and complex compositional semantics in drone scenarios pose challenges for vision-language understanding. Mainstream Vision-Language Models (VLMs) emphasize global alignment while lacking fine-grained semantics, and existing hierarchical methods depend on precise entity partitioning and strict containment, limiting effectiveness in dynamic environments. To address this, we propose the Hierarchical Cross-Granularity Contrastive and Matching learning (HCCM) framework with two components: (1) Region-Global Image-Text Contrastive Learning (RG-ITC), which avoids precise scene partitioning and captures hierarchical local-to-global semantics by contrasting local visual regions with global text and vice versa; (2) Region-Global Image-Text Matching (RG-ITM), which dispenses with rigid constraints and instead evaluates local semantic consistency within global cross-modal representations, enhancing compositional reasoning. Moreover, drone text descriptions are often incomplete or ambiguous, destabilizing alignment. HCCM introduces a Momentum Contrast and Distillation (MCD) mechanism to improve robustness. Experiments on GeoText-1652 show HCCM achieves state-of-the-art Recall@1 of 28.8% (image retrieval) and 14.7% (text retrieval). On the unseen ERA dataset, HCCM demonstrates strong zero-shot generalization with 39.93% mean recall (mR), outperforming fine-tuned baselines.
DDAP: Dual-Domain Anti-Personalization against Text-to-Image Diffusion Models
Jul 29, 2024Diffusion-based personalized visual content generation technologies have achieved significant breakthroughs, allowing for the creation of specific objects by just learning from a few reference photos. However, when misused to fabricate fake news or unsettling content targeting individuals, these technologies could cause considerable societal harm. To address this problem, current methods generate adversarial samples by adversarially maximizing the training loss, thereby disrupting the output of any personalized generation model trained with these samples. However, the existing methods fail to achieve effective defense and maintain stealthiness, as they overlook the intrinsic properties of diffusion models. In this paper, we introduce a novel Dual-Domain Anti-Personalization framework (DDAP). Specifically, we have developed Spatial Perturbation Learning (SPL) by exploiting the fixed and perturbation-sensitive nature of the image encoder in personalized generation. Subsequently, we have designed a Frequency Perturbation Learning (FPL) method that utilizes the characteristics of diffusion models in the frequency domain. The SPL disrupts the overall texture of the generated images, while the FPL focuses on image details. By alternating between these two methods, we construct the DDAP framework, effectively harnessing the strengths of both domains. To further enhance the visual quality of the adversarial samples, we design a localization module to accurately capture attentive areas while ensuring the effectiveness of the attack and avoiding unnecessary disturbances in the background. Extensive experiments on facial benchmarks have shown that the proposed DDAP enhances the disruption of personalized generation models while also maintaining high quality in adversarial samples, making it more effective in protecting privacy in practical applications.
GM-DF: Generalized Multi-Scenario Deepfake Detection
Jun 28, 2024Existing face forgery detection usually follows the paradigm of training models in a single domain, which leads to limited generalization capacity when unseen scenarios and unknown attacks occur. In this paper, we elaborately investigate the generalization capacity of deepfake detection models when jointly trained on multiple face forgery detection datasets. We first find a rapid degradation of detection accuracy when models are directly trained on combined datasets due to the discrepancy across collection scenarios and generation methods. To address the above issue, a Generalized Multi-Scenario Deepfake Detection framework (GM-DF) is proposed to serve multiple real-world scenarios by a unified model. First, we propose a hybrid expert modeling approach for domain-specific real/forgery feature extraction. Besides, as for the commonality representation, we use CLIP to extract the common features for better aligning visual and textual features across domains. Meanwhile, we introduce a masked image reconstruction mechanism to force models to capture rich forged details. Finally, we supervise the models via a domain-aware meta-learning strategy to further enhance their generalization capacities. Specifically, we design a novel domain alignment loss to strongly align the distributions of the meta-test domains and meta-train domains. Thus, the updated models are able to represent both specific and common real/forgery features across multiple datasets. In consideration of the lack of study of multi-dataset training, we establish a new benchmark leveraging multi-source data to fairly evaluate the models' generalization capacity on unseen scenarios. Both qualitative and quantitative experiments on five datasets conducted on traditional protocols as well as the proposed benchmark demonstrate the effectiveness of our approach.
Selective Domain-Invariant Feature for Generalizable Deepfake Detection
Mar 19, 2024



With diverse presentation forgery methods emerging continually, detecting the authenticity of images has drawn growing attention. Although existing methods have achieved impressive accuracy in training dataset detection, they still perform poorly in the unseen domain and suffer from forgery of irrelevant information such as background and identity, affecting generalizability. To solve this problem, we proposed a novel framework Selective Domain-Invariant Feature (SDIF), which reduces the sensitivity to face forgery by fusing content features and styles. Specifically, we first use a Farthest-Point Sampling (FPS) training strategy to construct a task-relevant style sample representation space for fusing with content features. Then, we propose a dynamic feature extraction module to generate features with diverse styles to improve the performance and effectiveness of the feature extractor. Finally, a domain separation strategy is used to retain domain-related features to help distinguish between real and fake faces. Both qualitative and quantitative results in existing benchmarks and proposals demonstrate the effectiveness of our approach.
SHIELD : An Evaluation Benchmark for Face Spoofing and Forgery Detection with Multimodal Large Language Models
Feb 06, 2024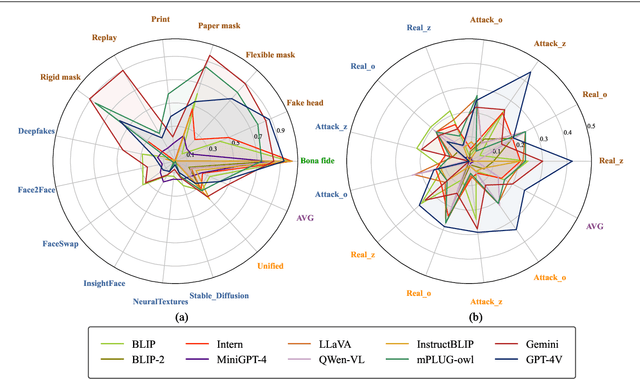
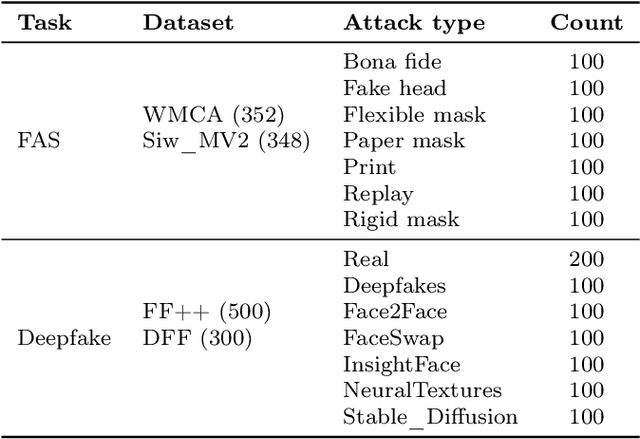

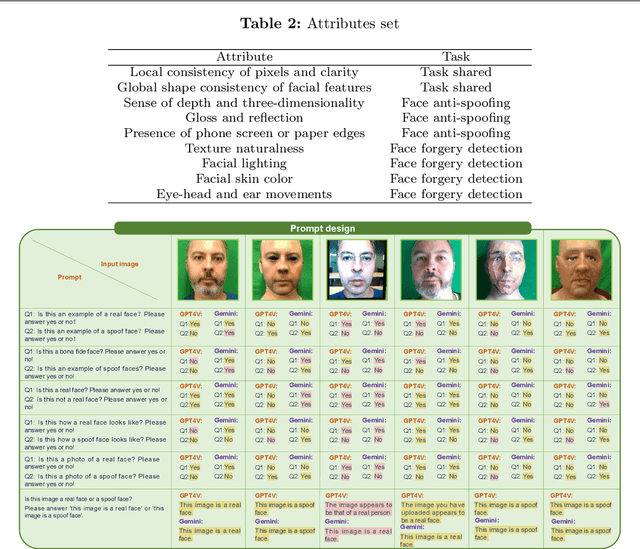
Multimodal large language models (MLLMs) have demonstrated remarkable problem-solving capabilities in various vision fields (e.g., generic object recognition and grounding) based on strong visual semantic representation and language reasoning ability. However, whether MLLMs are sensitive to subtle visual spoof/forged clues and how they perform in the domain of face attack detection (e.g., face spoofing and forgery detection) is still unexplored. In this paper, we introduce a new benchmark, namely SHIELD, to evaluate the ability of MLLMs on face spoofing and forgery detection. Specifically, we design true/false and multiple-choice questions to evaluate multimodal face data in these two face security tasks. For the face anti-spoofing task, we evaluate three different modalities (i.e., RGB, infrared, depth) under four types of presentation attacks (i.e., print attack, replay attack, rigid mask, paper mask). For the face forgery detection task, we evaluate GAN-based and diffusion-based data with both visual and acoustic modalities. Each question is subjected to both zero-shot and few-shot tests under standard and chain of thought (COT) settings. The results indicate that MLLMs hold substantial potential in the face security domain, offering advantages over traditional specific models in terms of interpretability, multimodal flexible reasoning, and joint face spoof and forgery detection. Additionally, we develop a novel Multi-Attribute Chain of Thought (MA-COT) paradigm for describing and judging various task-specific and task-irrelevant attributes of face images, which provides rich task-related knowledge for subtle spoof/forged clue mining. Extensive experiments in separate face anti-spoofing, separate face forgery detection, and joint detection tasks demonstrate the effectiveness of the proposed MA-COT. The project is available at https$:$//github.com/laiyingxin2/SHIELD