 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Semantic-Collaborative Gap: An Asymmetric Graph Architecture for Cold-Start Item Recommendation
Jun 04, 2026Collaborative filtering and graph-based recommendation models are highly effective because they leverage observed user interactions, but this dependence creates a fundamental cold-start challenge when newly added content has no interaction history. In Tubi's production retrieval system, this challenge is further constrained by the serving interface: new content must be assigned a standalone embedding immediately, and the model must also produce device embeddings suitable for approximate nearest-neighbor retrieval. We address this setting by formulating cold-start recommendation as an inductive graph-completion problem on a temporal bipartite device-content graph. We propose Shallow-RHS, an asymmetric link-prediction architecture in which the left-hand side (LHS) device tower leverages temporally valid watch-history message passing to capture collaborative signals, while the right-hand side (RHS) content tower is intentionally shallow with respect to the graph and encodes content solely from intrinsic features. The RHS tower does not use ID-based embeddings, content-side subgraphs, neighbor aggregation, or interaction-derived representations, forcing the content encoder to map intrinsic features into a collaborative-filtering-aware embedding space. After training, the learned content encoder generates embeddings for both warm and newly ingested content, enabling implicit graph completion through retrieval of warm surrogate neighbors. We further extend the same representation-completion principle to device cold-start by constructing cohort-based embeddings from demographic features. Large-scale online experiments demonstrate consistent relative improvements in content cold-start engagement, promotion speed, impression acquisition, and device cold-start engagement.
AI-Driven Stylization of 3D Environments
Nov 09, 2024
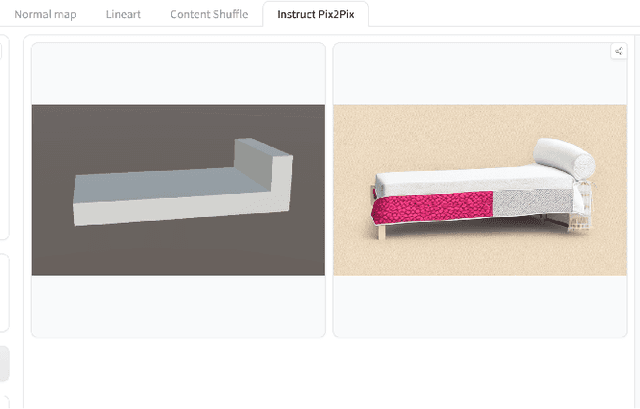


In this system, we discuss methods to stylize a scene of 3D primitive objects into a higher fidelity 3D scene using novel 3D representations like NeRFs and 3D Gaussian Splatting. Our approach leverages existing image stylization systems and image-to-3D generative models to create a pipeline that iteratively stylizes and composites 3D objects into scenes. We show our results on adding generated objects into a scene and discuss limitations.
Scalable Indoor Novel-View Synthesis using Drone-Captured 360 Imagery with 3D Gaussian Splatting
Oct 15, 2024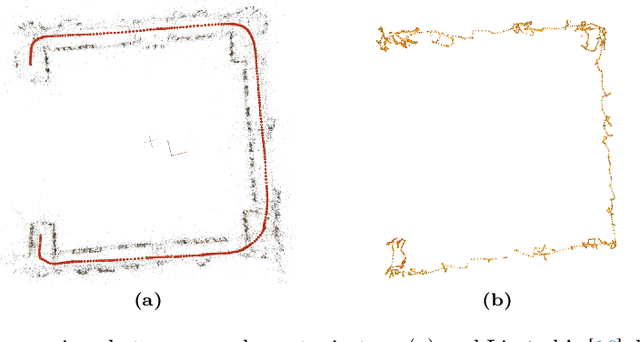

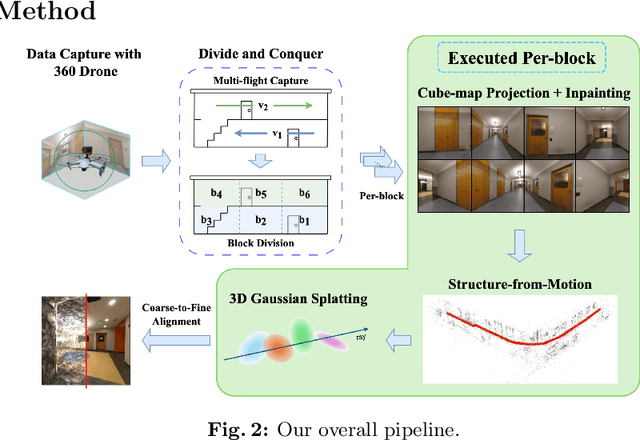
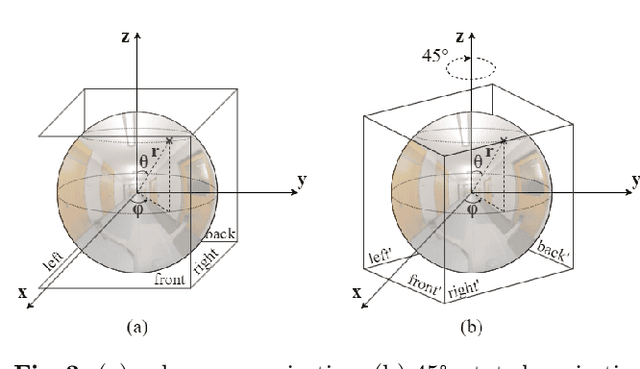
Scene reconstruction and novel-view synthesis for large, complex, multi-story, indoor scenes is a challenging and time-consuming task. Prior methods have utilized drones for data capture and radiance fields for scene reconstruction, both of which present certain challenges. First, in order to capture diverse viewpoints with the drone's front-facing camera, some approaches fly the drone in an unstable zig-zag fashion, which hinders drone-piloting and generates motion blur in the captured data. Secondly, most radiance field methods do not easily scale to arbitrarily large number of images. This paper proposes an efficient and scalable pipeline for indoor novel-view synthesis from drone-captured 360 videos using 3D Gaussian Splatting. 360 cameras capture a wide set of viewpoints, allowing for comprehensive scene capture under a simple straightforward drone trajectory. To scale our method to large scenes, we devise a divide-and-conquer strategy to automatically split the scene into smaller blocks that can be reconstructed individually and in parallel. We also propose a coarse-to-fine alignment strategy to seamlessly match these blocks together to compose the entire scene. Our experiments demonstrate marked improvement in both reconstruction quality, i.e. PSNR and SSIM, and computation time compared to prior approaches.
Group Benefits Instances Selection for Data Purification
Mar 23, 2024Manually annotating datasets for training deep models is very labor-intensive and time-consuming. To overcome such inferiority, directly leveraging web images to conduct training data becomes a natural choice. Nevertheless, the presence of label noise in web data usually degrades the model performance. Existing methods for combating label noise are typically designed and tested on synthetic noisy datasets. However, they tend to fail to achieve satisfying results on real-world noisy datasets. To this end, we propose a method named GRIP to alleviate the noisy label problem for both synthetic and real-world datasets. Specifically, GRIP utilizes a group regularization strategy that estimates class soft labels to improve noise robustness. Soft label supervision reduces overfitting on noisy labels and learns inter-class similarities to benefit classification. Furthermore, an instance purification operation globally identifies noisy labels by measuring the difference between each training sample and its class soft label. Through operations at both group and instance levels, our approach integrates the advantages of noise-robust and noise-cleaning methods and remarkably alleviates the performance degradation caused by noisy labels. Comprehensive experimental results on synthetic and real-world datasets demonstrate the superiority of GRIP over the existing state-of-the-art methods.
Model-based Constrained MDP for Budget Allocation in Sequential Incentive Marketing
Mar 02, 2023



Sequential incentive marketing is an important approach for online businesses to acquire customers, increase loyalty and boost sales. How to effectively allocate the incentives so as to maximize the return (e.g., business objectives) under the budget constraint, however, is less studied in the literature. This problem is technically challenging due to the facts that 1) the allocation strategy has to be learned using historically logged data, which is counterfactual in nature, and 2) both the optimality and feasibility (i.e., that cost cannot exceed budget) needs to be assessed before being deployed to online systems. In this paper, we formulate the problem as a constrained Markov decision process (CMDP). To solve the CMDP problem with logged counterfactual data, we propose an efficient learning algorithm which combines bisection search and model-based planning. First, the CMDP is converted into its dual using Lagrangian relaxation, which is proved to be monotonic with respect to the dual variable. Furthermore, we show that the dual problem can be solved by policy learning, with the optimal dual variable being found efficiently via bisection search (i.e., by taking advantage of the monotonicity). Lastly, we show that model-based planing can be used to effectively accelerate the joint optimization process without retraining the policy for every dual variable. Empirical results on synthetic and real marketing datasets confirm the effectiveness of our methods.
Multi-Scale User Behavior Network for Entire Space Multi-Task Learning
Aug 16, 2022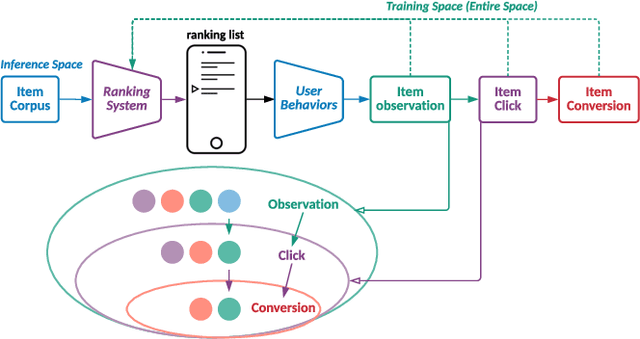

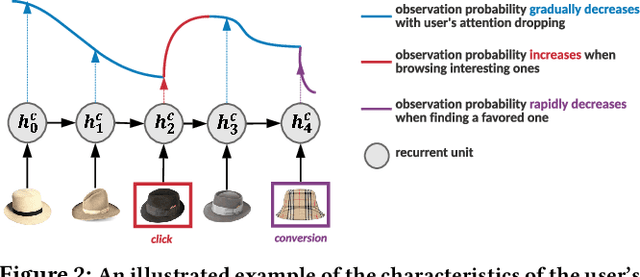
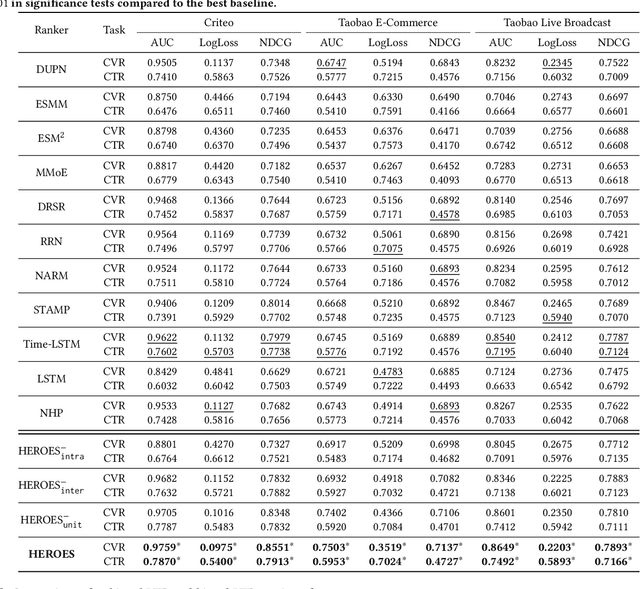
Modelling the user's multiple behaviors is an essential part of modern e-commerce, whose widely adopted application is to jointly optimize click-through rate (CTR) and conversion rate (CVR) predictions. Most of existing methods overlook the effect of two key characteristics of the user's behaviors: for each item list, (i) contextual dependence refers to that the user's behaviors on any item are not purely determinated by the item itself but also are influenced by the user's previous behaviors (e.g., clicks, purchases) on other items in the same sequence; (ii) multiple time scales means that users are likely to click frequently but purchase periodically. To this end, we develop a new multi-scale user behavior network named Hierarchical rEcurrent Ranking On the Entire Space (HEROES) which incorporates the contextual information to estimate the user multiple behaviors in a multi-scale fashion. Concretely, we introduce a hierarchical framework, where the lower layer models the user's engagement behaviors while the upper layer estimates the user's satisfaction behaviors. The proposed architecture can automatically learn a suitable time scale for each layer to capture the dynamic user's behavioral patterns. Besides the architecture, we also introduce the Hawkes process to form a novel recurrent unit which can not only encode the items' features in the context but also formulate the excitation or discouragement from the user's previous behaviors. We further show that HEROES can be extended to build unbiased ranking systems through combinations with the survival analysis technique. Extensive experiments over three large-scale industrial datasets demonstrate the superiority of our model compared with the state-of-the-art methods.
Who to Watch Next: Two-side Interactive Networks for Live Broadcast Recommendation
Feb 09, 2022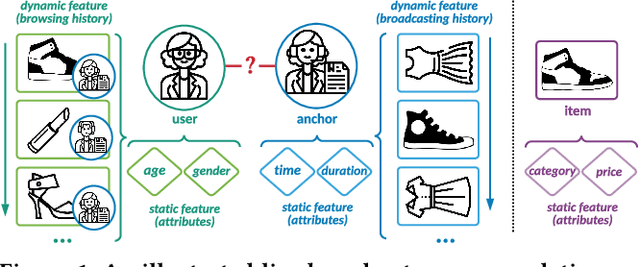
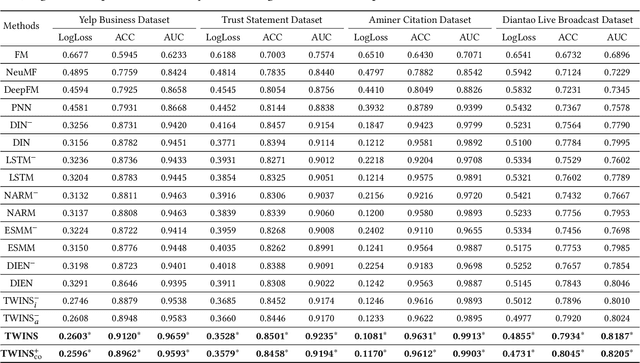
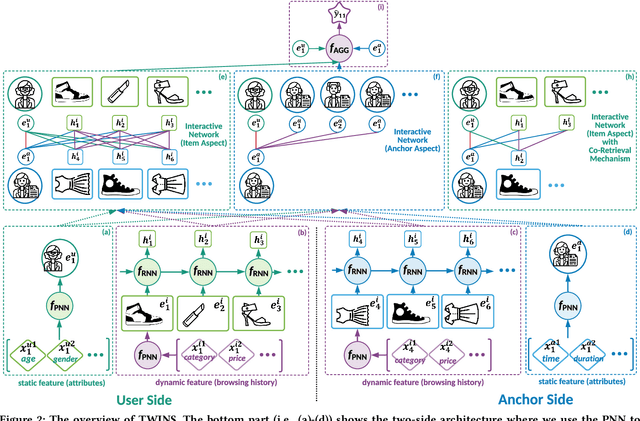

With the prevalence of live broadcast business nowadays, a new type of recommendation service, called live broadcast recommendation, is widely used in many mobile e-commerce Apps. Different from classical item recommendation, live broadcast recommendation is to automatically recommend user anchors instead of items considering the interactions among triple-objects (i.e., users, anchors, items) rather than binary interactions between users and items. Existing methods based on binary objects, ranging from early matrix factorization to recently emerged deep learning, obtain objects' embeddings by mapping from pre-existing features. Directly applying these techniques would lead to limited performance, as they are failing to encode collaborative signals among triple-objects. In this paper, we propose a novel TWo-side Interactive NetworkS (TWINS) for live broadcast recommendation. In order to fully use both static and dynamic information on user and anchor sides, we combine a product-based neural network with a recurrent neural network to learn the embedding of each object. In addition, instead of directly measuring the similarity, TWINS effectively injects the collaborative effects into the embedding process in an explicit manner by modeling interactive patterns between the user's browsing history and the anchor's broadcast history in both item and anchor aspects. Furthermore, we design a novel co-retrieval technique to select key items among massive historic records efficiently. Offline experiments on real large-scale data show the superior performance of the proposed TWINS, compared to representative methods; and further results of online experiments on Diantao App show that TWINS gains average performance improvement of around 8% on ACTR metric, 3% on UCTR metric, 3.5% on UCVR metric.