 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOwl-AuraID 1.0: An Intelligent System for Autonomous Scientific Instrumentation and Scientific Data Analysis
Mar 31, 2026Scientific discovery increasingly depends on high-throughput characterization, yet automation is hindered by proprietary GUIs and the limited generalizability of existing API-based systems. We present Owl-AuraID, a software-hardware collaborative embodied agent system that adopts a GUI-native paradigm to operate instruments through the same interfaces as human experts. Its skill-centric framework integrates Type-1 (GUI operation) and Type-2 (data analysis) skills into end-to-end workflows, connecting physical sample handling with scientific interpretation. Owl-AuraID demonstrates broad coverage across ten categories of precision instruments and diverse workflows, including multimodal spectral analysis, microscopic imaging, and crystallographic analysis, supporting modalities such as FTIR, NMR, AFM, and TGA. Overall, Owl-AuraID provides a practical, extensible foundation for autonomous laboratories and illustrates a path toward evolving laboratory intelligence through reusable operational and analytical skills. The code are available at https://github.com/OpenOwlab/AuraID.
DRiffusion: Draft-and-Refine Process Parallelizes Diffusion Models with Ease
Mar 26, 2026Diffusion models have achieved remarkable success in generating high-fidelity content but suffer from slow, iterative sampling, resulting in high latency that limits their use in interactive applications. We introduce DRiffusion, a parallel sampling framework that parallelizes diffusion inference through a draft-and-refine process. DRiffusion employs skip transitions to generate multiple draft states for future timesteps and computes their corresponding noises in parallel, which are then used in the standard denoising process to produce refined results. Theoretically, our method achieves an acceleration rate of $\tfrac{1}{n}$ or $\tfrac{2}{n+1}$, depending on whether the conservative or aggressive mode is used, where $n$ denotes the number of devices. Empirically, DRiffusion attains 1.4$\times$-3.7$\times$ speedup across multiple diffusion models while incur minimal degradation in generation quality: on MS-COCO dataset, both FID and CLIP remain largely on par with those of the original model, while PickScore and HPSv2.1 show only minor average drops of 0.17 and 0.43, respectively. These results verify that DRiffusion delivers substantial acceleration and preserves perceptual quality.
Scalable Indoor Novel-View Synthesis using Drone-Captured 360 Imagery with 3D Gaussian Splatting
Oct 15, 2024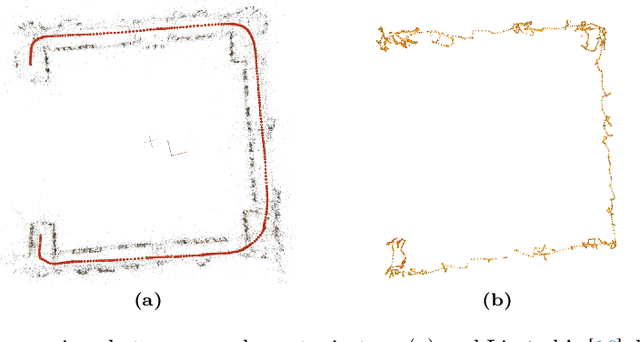

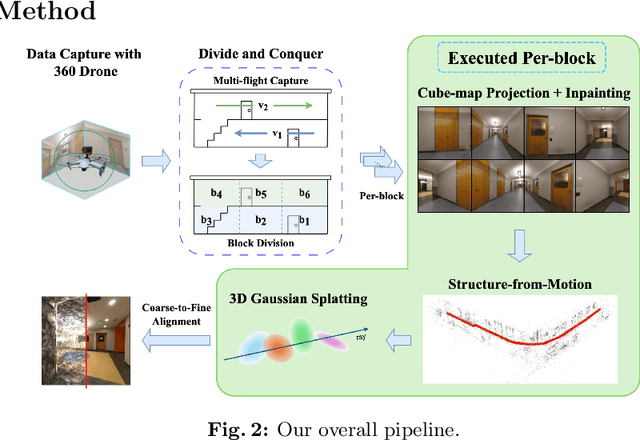
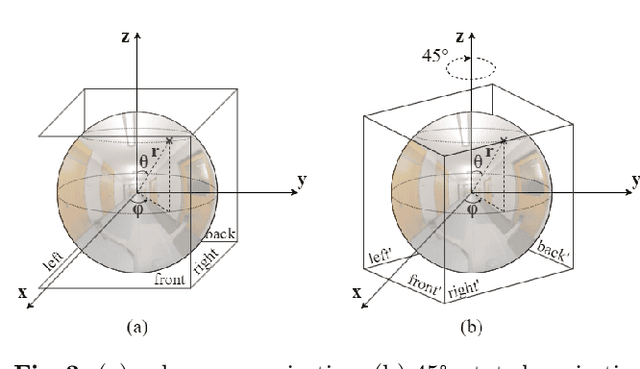
Scene reconstruction and novel-view synthesis for large, complex, multi-story, indoor scenes is a challenging and time-consuming task. Prior methods have utilized drones for data capture and radiance fields for scene reconstruction, both of which present certain challenges. First, in order to capture diverse viewpoints with the drone's front-facing camera, some approaches fly the drone in an unstable zig-zag fashion, which hinders drone-piloting and generates motion blur in the captured data. Secondly, most radiance field methods do not easily scale to arbitrarily large number of images. This paper proposes an efficient and scalable pipeline for indoor novel-view synthesis from drone-captured 360 videos using 3D Gaussian Splatting. 360 cameras capture a wide set of viewpoints, allowing for comprehensive scene capture under a simple straightforward drone trajectory. To scale our method to large scenes, we devise a divide-and-conquer strategy to automatically split the scene into smaller blocks that can be reconstructed individually and in parallel. We also propose a coarse-to-fine alignment strategy to seamlessly match these blocks together to compose the entire scene. Our experiments demonstrate marked improvement in both reconstruction quality, i.e. PSNR and SSIM, and computation time compared to prior approaches.
Boosting Few-Shot Segmentation via Instance-Aware Data Augmentation and Local Consensus Guided Cross Attention
Jan 18, 2024Few-shot segmentation aims to train a segmentation model that can fast adapt to a novel task for which only a few annotated images are provided. Most recent models have adopted a prototype-based paradigm for few-shot inference. These approaches may have limited generalization capacity beyond the standard 1- or 5-shot settings. In this paper, we closely examine and reevaluate the fine-tuning based learning scheme that fine-tunes the classification layer of a deep segmentation network pre-trained on diverse base classes. To improve the generalizability of the classification layer optimized with sparsely annotated samples, we introduce an instance-aware data augmentation (IDA) strategy that augments the support images based on the relative sizes of the target objects. The proposed IDA effectively increases the support set's diversity and promotes the distribution consistency between support and query images. On the other hand, the large visual difference between query and support images may hinder knowledge transfer and cripple the segmentation performance. To cope with this challenge, we introduce the local consensus guided cross attention (LCCA) to align the query feature with support features based on their dense correlation, further improving the model's generalizability to the query image. The significant performance improvements on the standard few-shot segmentation benchmarks PASCAL-$5^i$ and COCO-$20^i$ verify the efficacy of our proposed method.