 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnicron: Economizing Self-Healing LLM Training at Scale
Paper and Code
Dec 30, 2023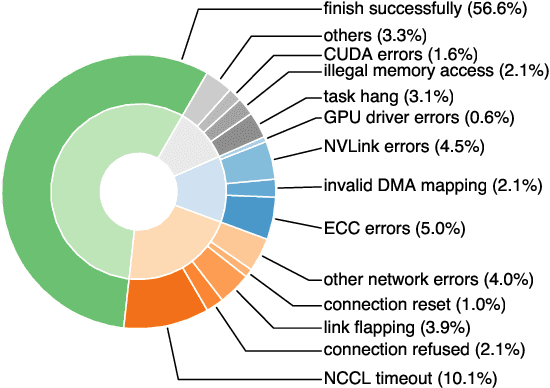
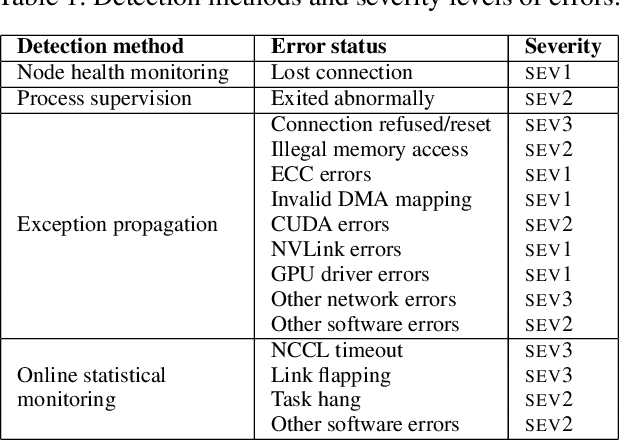
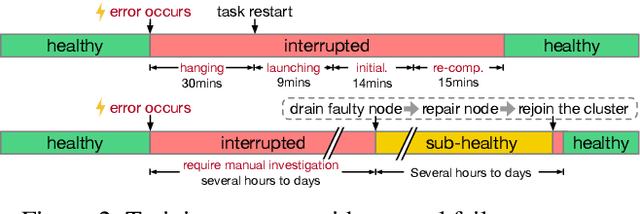

Training large-scale language models is increasingly critical in various domains, but it is hindered by frequent failures, leading to significant time and economic costs. Current failure recovery methods in cloud-based settings inadequately address the diverse and complex scenarios that arise, focusing narrowly on erasing downtime for individual tasks without considering the overall cost impact on a cluster. We introduce Unicron, a workload manager designed for efficient self-healing in large-scale language model training. Unicron optimizes the training process by minimizing failure-related costs across multiple concurrent tasks within a cluster. Its key features include in-band error detection for real-time error identification without extra overhead, a dynamic cost-aware plan generation mechanism for optimal reconfiguration, and an efficient transition strategy to reduce downtime during state changes. Deployed on a 128-GPU distributed cluster, Unicron demonstrates up to a 1.9x improvement in training efficiency over state-of-the-art methods, significantly reducing failure recovery costs and enhancing the reliability of large-scale language model training.