 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreaming when Necessary: Advancing World Action Models with Adaptive Multi-Modal Reasoning
Jun 05, 2026World Action Models (WAMs) offer a promising approach to embodied intelligence, yet existing methods rely heavily on video prediction as action priors and lack adaptive multimodal reasoning, limiting their effectiveness on long-horizon, complex tasks. We observe that WAMs require different multimodal reasoning modes under different execution contexts: textual reasoning is essential during task transitions to guide high-level action prediction, while visual reasoning is critical during fine-grained manipulation for precise control. Motivated by this observation, we propose \textbf{AdaWAM}, a world action model with adaptive multimodal reasoning abilities. AdaWAM integrates a lightweight dynamic router that autonomously triggers textual or visual reasoning as needed during task execution. Experiments on both simulated and real-world embodied tasks show that AdaWAM substantially improves inference efficiency while outperforming state-of-the-art embodied policies. Codes and demos are available at: https://adawam.github.io/.
AutoSOTA: An End-to-End Automated Research System for State-of-the-Art AI Model Discovery
Apr 07, 2026Artificial intelligence research increasingly depends on prolonged cycles of reproduction, debugging, and iterative refinement to achieve State-Of-The-Art (SOTA) performance, creating a growing need for systems that can accelerate the full pipeline of empirical model optimization. In this work, we introduce AutoSOTA, an end-to-end automated research system that advances the latest SOTA models published in top-tier AI papers to reproducible and empirically improved new SOTA models. We formulate this problem through three tightly coupled stages: resource preparation and goal setting; experiment evaluation; and reflection and ideation. To tackle this problem, AutoSOTA adopts a multi-agent architecture with eight specialized agents that collaboratively ground papers to code and dependencies, initialize and repair execution environments, track long-horizon experiments, generate and schedule optimization ideas, and supervise validity to avoid spurious gains. We evaluate AutoSOTA on recent research papers collected from eight top-tier AI conferences under filters for code availability and execution cost. Across these papers, AutoSOTA achieves strong end-to-end performance in both automated replication and subsequent optimization. Specifically, it successfully discovers 105 new SOTA models that surpass the original reported methods, averaging approximately five hours per paper. Case studies spanning LLM, NLP, computer vision, time series, and optimization further show that the system can move beyond routine hyperparameter tuning to identify architectural innovation, algorithmic redesigns, and workflow-level improvements. These results suggest that end-to-end research automation can serve not only as a performance optimizer, but also as a new form of research infrastructure that reduces repetitive experimental burden and helps redirect human attention toward higher-level scientific creativity.
Intelligent Multimodal Multi-Sensor Fusion-Based UAV Identification, Localization, and Countermeasures for Safeguarding Low-Altitude Economy
Oct 27, 2025The development of the low-altitude economy has led to a growing prominence of uncrewed aerial vehicle (UAV) safety management issues. Therefore, accurate identification, real-time localization, and effective countermeasures have become core challenges in airspace security assurance. This paper introduces an integrated UAV management and control system based on deep learning, which integrates multimodal multi-sensor fusion perception, precise positioning, and collaborative countermeasures. By incorporating deep learning methods, the system combines radio frequency (RF) spectral feature analysis, radar detection, electro-optical identification, and other methods at the detection level to achieve the identification and classification of UAVs. At the localization level, the system relies on multi-sensor data fusion and the air-space-ground integrated communication network to conduct real-time tracking and prediction of UAV flight status, providing support for early warning and decision-making. At the countermeasure level, it adopts comprehensive measures that integrate ``soft kill'' and ``hard kill'', including technologies such as electromagnetic signal jamming, navigation spoofing, and physical interception, to form a closed-loop management and control process from early warning to final disposal, which significantly enhances the response efficiency and disposal accuracy of low-altitude UAV management.
A Survey on Human-Centric LLMs
Nov 26, 2024



The rapid evolution of large language models (LLMs) and their capacity to simulate human cognition and behavior has given rise to LLM-based frameworks and tools that are evaluated and applied based on their ability to perform tasks traditionally performed by humans, namely those involving cognition, decision-making, and social interaction. This survey provides a comprehensive examination of such human-centric LLM capabilities, focusing on their performance in both individual tasks (where an LLM acts as a stand-in for a single human) and collective tasks (where multiple LLMs coordinate to mimic group dynamics). We first evaluate LLM competencies across key areas including reasoning, perception, and social cognition, comparing their abilities to human-like skills. Then, we explore real-world applications of LLMs in human-centric domains such as behavioral science, political science, and sociology, assessing their effectiveness in replicating human behaviors and interactions. Finally, we identify challenges and future research directions, such as improving LLM adaptability, emotional intelligence, and cultural sensitivity, while addressing inherent biases and enhancing frameworks for human-AI collaboration. This survey aims to provide a foundational understanding of LLMs from a human-centric perspective, offering insights into their current capabilities and potential for future development.
Unicron: Economizing Self-Healing LLM Training at Scale
Dec 30, 2023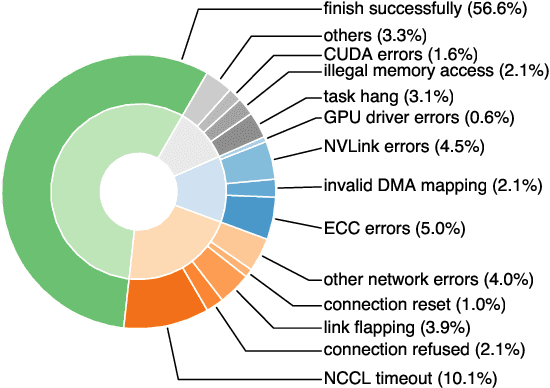
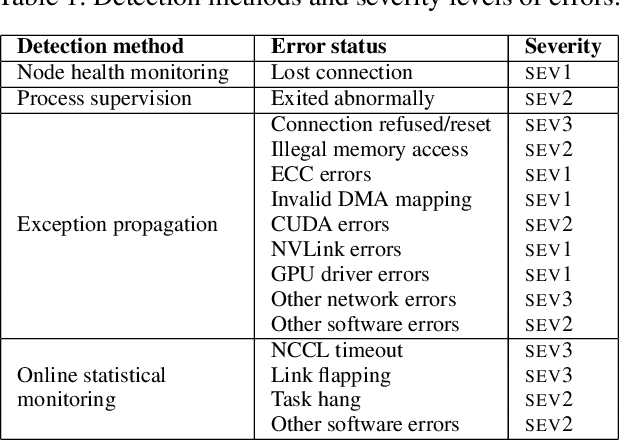
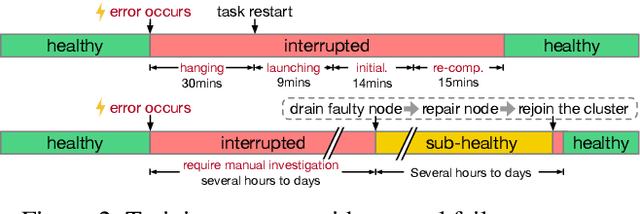

Training large-scale language models is increasingly critical in various domains, but it is hindered by frequent failures, leading to significant time and economic costs. Current failure recovery methods in cloud-based settings inadequately address the diverse and complex scenarios that arise, focusing narrowly on erasing downtime for individual tasks without considering the overall cost impact on a cluster. We introduce Unicron, a workload manager designed for efficient self-healing in large-scale language model training. Unicron optimizes the training process by minimizing failure-related costs across multiple concurrent tasks within a cluster. Its key features include in-band error detection for real-time error identification without extra overhead, a dynamic cost-aware plan generation mechanism for optimal reconfiguration, and an efficient transition strategy to reduce downtime during state changes. Deployed on a 128-GPU distributed cluster, Unicron demonstrates up to a 1.9x improvement in training efficiency over state-of-the-art methods, significantly reducing failure recovery costs and enhancing the reliability of large-scale language model training.