 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust-Aware Embodied Bayesian Persuasion for Mixed-Autonomy
Sep 18, 2025Safe and efficient interaction between autonomous vehicles (AVs) and human-driven vehicles (HVs) is a critical challenge for future transportation systems. While game-theoretic models capture how AVs influence HVs, they often suffer from a long-term decay of influence and can be perceived as manipulative, eroding the human's trust. This can paradoxically lead to riskier human driving behavior over repeated interactions. In this paper, we address this challenge by proposing the Trust-Aware Embodied Bayesian Persuasion (TA-EBP) framework. Our work makes three key contributions: First, we apply Bayesian persuasion to model communication at traffic intersections, offering a transparent alternative to traditional game-theoretic models. Second, we introduce a trust parameter to the persuasion framework, deriving a theorem for the minimum trust level required for influence. Finally, we ground the abstract signals of Bayesian persuasion theory into a continuous, physically meaningful action space, deriving a second theorem for the optimal signal magnitude, realized as an AV's forward nudge. Additionally, we validate our framework in a mixed-autonomy traffic simulation, demonstrating that TA-EBP successfully persuades HVs to drive more cautiously, eliminating collisions and improving traffic flow compared to baselines that either ignore trust or lack communication. Our work provides a transparent and non-strategic framework for influence in human-robot interaction, enhancing both safety and efficiency.
Interaction-aware Conformal Prediction for Crowd Navigation
Feb 10, 2025During crowd navigation, robot motion plan needs to consider human motion uncertainty, and the human motion uncertainty is dependent on the robot motion plan. We introduce Interaction-aware Conformal Prediction (ICP) to alternate uncertainty-aware robot motion planning and decision-dependent human motion uncertainty quantification. ICP is composed of a trajectory predictor to predict human trajectories, a model predictive controller to plan robot motion with confidence interval radii added for probabilistic safety, a human simulator to collect human trajectory calibration dataset conditioned on the planned robot motion, and a conformal prediction module to quantify trajectory prediction error on the decision-dependent calibration dataset. Crowd navigation simulation experiments show that ICP strikes a good balance of performance among navigation efficiency, social awareness, and uncertainty quantification compared to previous works. ICP generalizes well to navigation tasks under various crowd densities. The fast runtime and efficient memory usage make ICP practical for real-world applications. Code is available at https://github.com/tedhuang96/icp.
Traversing Supervisor Problem: An Approximately Optimal Approach to Multi-Robot Assistance
May 03, 2022
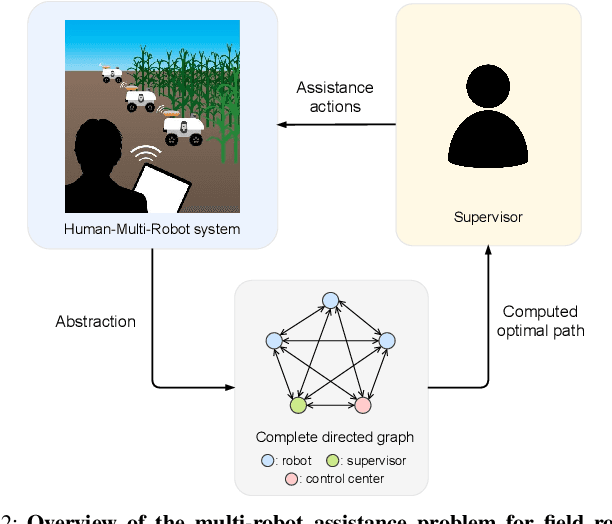
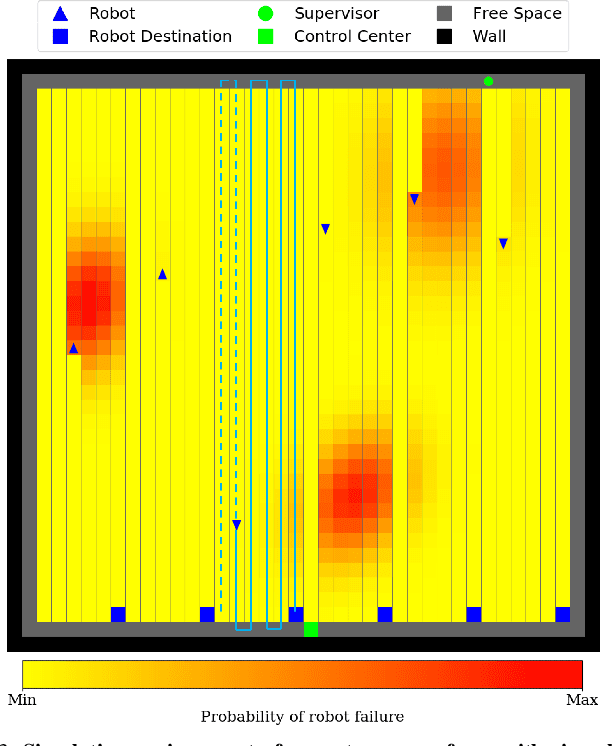
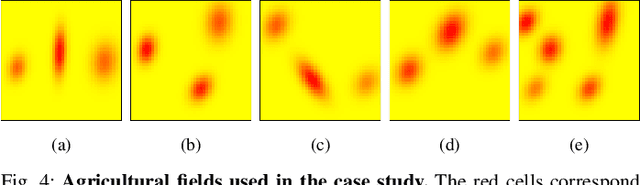
The number of multi-robot systems deployed in field applications has increased dramatically over the years. Despite the recent advancement of navigation algorithms, autonomous robots often encounter challenging situations where the control policy fails and the human assistance is required to resume robot tasks. Human-robot collaboration can help achieve high-levels of autonomy, but monitoring and managing multiple robots at once by a single human supervisor remains a challenging problem. Our goal is to help a supervisor decide which robots to assist in which order such that the team performance can be maximized. We formulate the one-to-many supervision problem in uncertain environments as a dynamic graph traversal problem. An approximation algorithm based on the profitable tour problem on a static graph is developed to solve the original problem, and the approximation error is bounded and analyzed. Our case study on a simulated autonomous farm demonstrates superior team performance than baseline methods in task completion time and human working time, and that our method can be deployed in real-time for robot fleets with moderate size.
Which Echo Chamber? Regions of Attraction in Learning with Decision-Dependent Distributions
Jun 30, 2021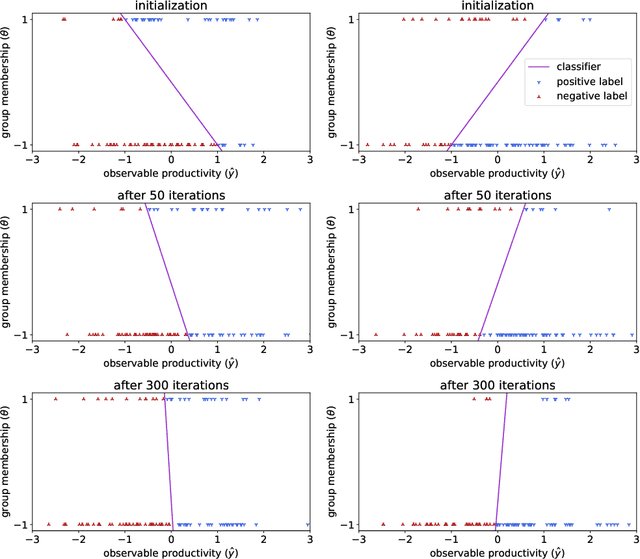
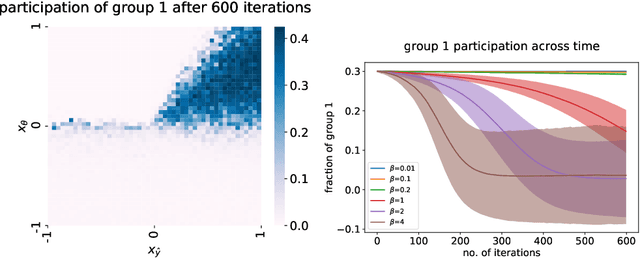
As data-driven methods are deployed in real-world settings, the processes that generate the observed data will often react to the decisions of the learner. For example, a data source may have some incentive for the algorithm to provide a particular label (e.g. approve a bank loan), and manipulate their features accordingly. Work in strategic classification and decision-dependent distributions seeks to characterize the closed-loop behavior of deploying learning algorithms by explicitly considering the effect of the classifier on the underlying data distribution. More recently, works in performative prediction seek to classify the closed-loop behavior by considering general properties of the mapping from classifier to data distribution, rather than an explicit form. Building on this notion, we analyze repeated risk minimization as the perturbed trajectories of the gradient flows of performative risk minimization. We consider the case where there may be multiple local minimizers of performative risk, motivated by real world situations where the initial conditions may have significant impact on the long-term behavior of the system. As a motivating example, we consider a company whose current employee demographics affect the applicant pool they interview: the initial demographics of the company can affect the long-term hiring policies of the company. We provide sufficient conditions to characterize the region of attraction for the various equilibria in this settings. Additionally, we introduce the notion of performative alignment, which provides a geometric condition on the convergence of repeated risk minimization to performative risk minimizers.
On the Sample Complexity of Causal Discovery and the Value of Domain Expertise
Feb 05, 2021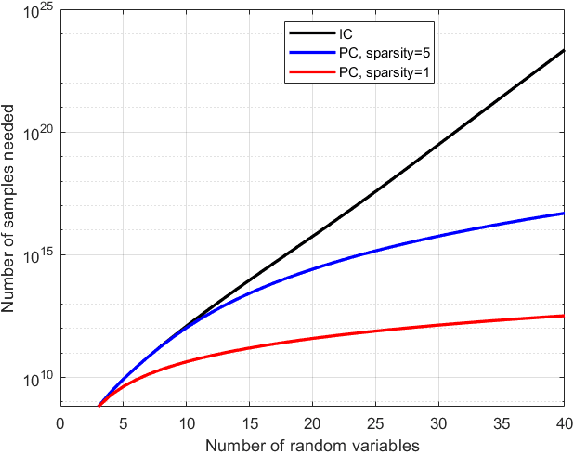

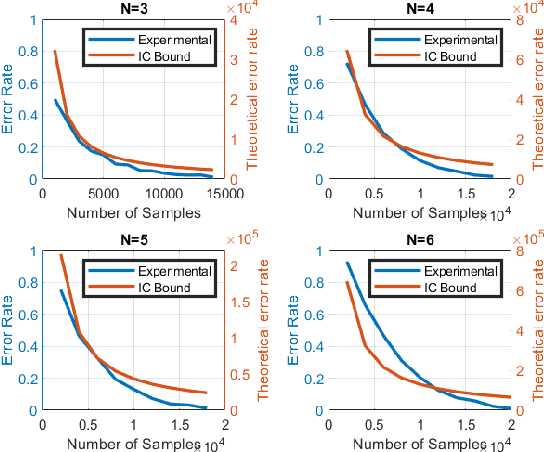

Causal discovery methods seek to identify causal relations between random variables from purely observational data, as opposed to actively collected experimental data where an experimenter intervenes on a subset of correlates. One of the seminal works in this area is the Inferred Causation algorithm, which guarantees successful causal discovery under the assumption of a conditional independence (CI) oracle: an oracle that can states whether two random variables are conditionally independent given another set of random variables. Practical implementations of this algorithm incorporate statistical tests for conditional independence, in place of a CI oracle. In this paper, we analyze the sample complexity of causal discovery algorithms without a CI oracle: given a certain level of confidence, how many data points are needed for a causal discovery algorithm to identify a causal structure? Furthermore, our methods allow us to quantify the value of domain expertise in terms of data samples. Finally, we demonstrate the accuracy of these sample rates with numerical examples, and quantify the benefits of sparsity priors and known causal directions.
Expert Selection in High-Dimensional Markov Decision Processes
Oct 26, 2020
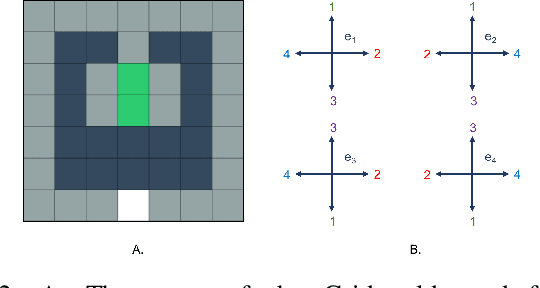
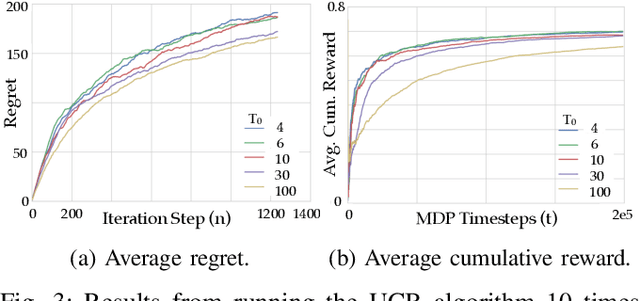
In this work we present a multi-armed bandit framework for online expert selection in Markov decision processes and demonstrate its use in high-dimensional settings. Our method takes a set of candidate expert policies and switches between them to rapidly identify the best performing expert using a variant of the classical upper confidence bound algorithm, thus ensuring low regret in the overall performance of the system. This is useful in applications where several expert policies may be available, and one needs to be selected at run-time for the underlying environment.
Competitive Statistical Estimation with Strategic Data Sources
Apr 29, 2019
In recent years, data has played an increasingly important role in the economy as a good in its own right. In many settings, data aggregators cannot directly verify the quality of the data they purchase, nor the effort exerted by data sources when creating the data. Recent work has explored mechanisms to ensure that the data sources share high quality data with a single data aggregator, addressing the issue of moral hazard. Oftentimes, there is a unique, socially efficient solution. In this paper, we consider data markets where there is more than one data aggregator. Since data can be cheaply reproduced and transmitted once created, data sources may share the same data with more than one aggregator, leading to free-riding between data aggregators. This coupling can lead to non-uniqueness of equilibria and social inefficiency. We examine a particular class of mechanisms that have received study recently in the literature, and we characterize all the generalized Nash equilibria of the resulting data market. We show that, in contrast to the single-aggregator case, there is either infinitely many generalized Nash equilibria or none. We also provide necessary and sufficient conditions for all equilibria to be socially inefficient. In our analysis, we identify the components of these mechanisms which give rise to these undesirable outcomes, showing the need for research into mechanisms for competitive settings with multiple data purchasers and sellers.
People as Sensors: Imputing Maps from Human Actions
Jan 08, 2019

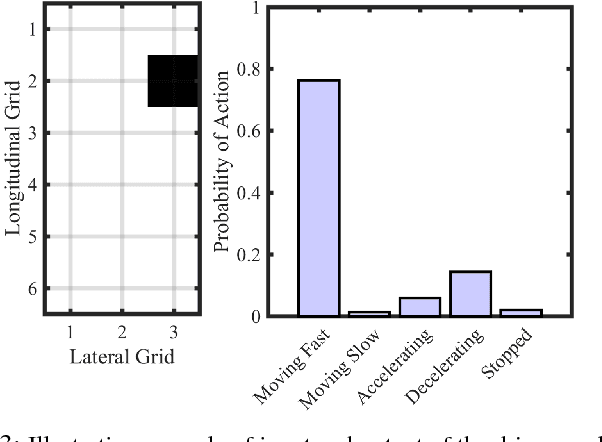
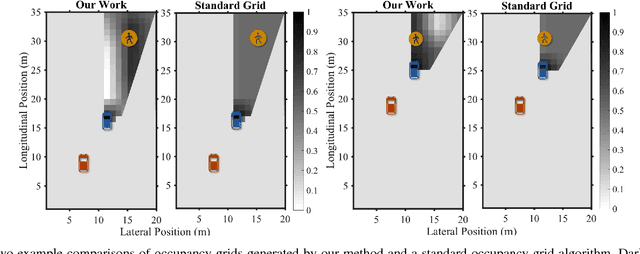
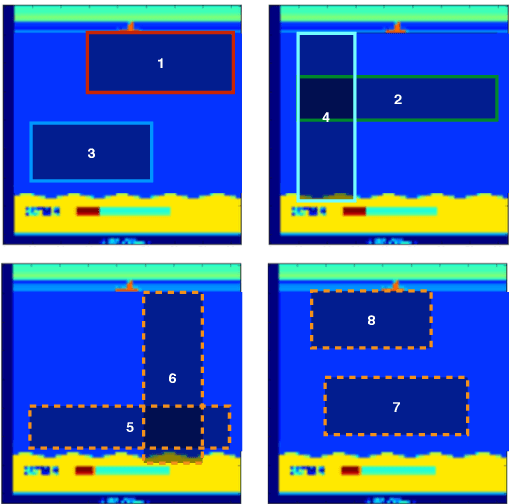
Despite growing attention in autonomy, there are still many open problems, including how autonomous vehicles will interact and communicate with other agents, such as human drivers and pedestrians. Unlike most approaches that focus on pedestrian detection and planning for collision avoidance, this paper considers modeling the interaction between human drivers and pedestrians and how it might influence map estimation, as a proxy for detection. We take a mapping inspired approach and incorporate people as sensors into mapping frameworks. By taking advantage of other agents' actions, we demonstrate how we can impute portions of the map that would otherwise be occluded. We evaluate our framework in human driving experiments and on real-world data, using occupancy grids and landmark-based mapping approaches. Our approach significantly improves overall environment awareness and out-performs standard mapping techniques.
Quadratic Basis Pursuit
Feb 09, 2013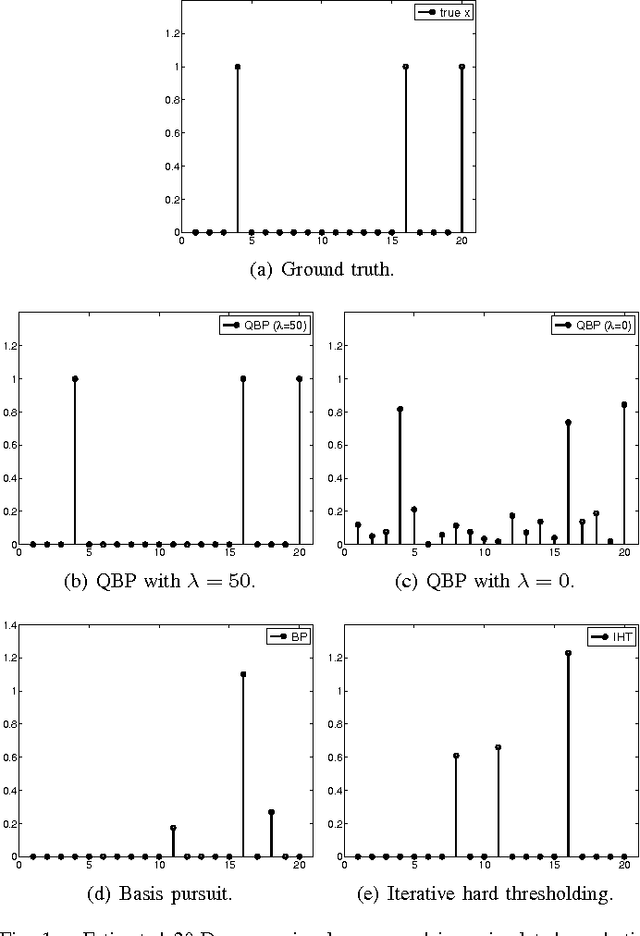

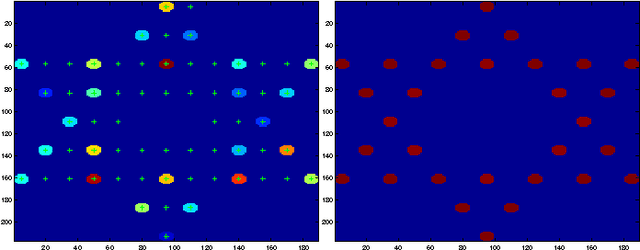

In many compressive sensing problems today, the relationship between the measurements and the unknowns could be nonlinear. Traditional treatment of such nonlinear relationships have been to approximate the nonlinearity via a linear model and the subsequent un-modeled dynamics as noise. The ability to more accurately characterize nonlinear models has the potential to improve the results in both existing compressive sensing applications and those where a linear approximation does not suffice, e.g., phase retrieval. In this paper, we extend the classical compressive sensing framework to a second-order Taylor expansion of the nonlinearity. Using a lifting technique and a method we call quadratic basis pursuit, we show that the sparse signal can be recovered exactly when the sampling rate is sufficiently high. We further present efficient numerical algorithms to recover sparse signals in second-order nonlinear systems, which are considerably more difficult to solve than their linear counterparts in sparse optimization.