 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Scene Augmentation and Synthesis via GSACNet
Mar 29, 2021
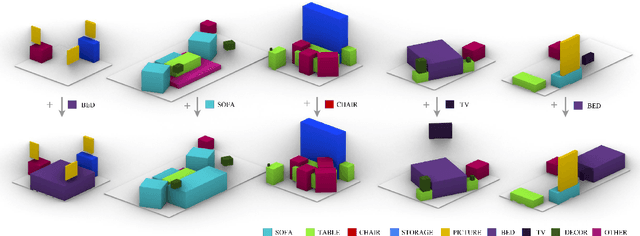
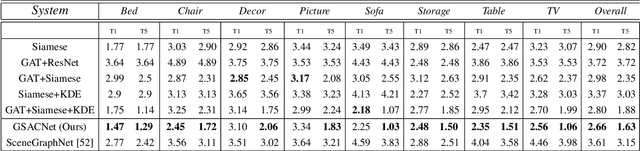
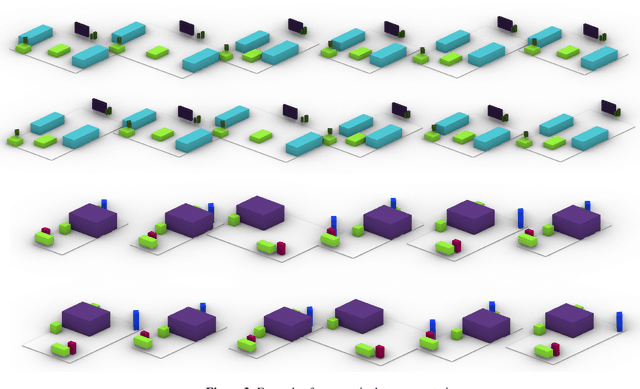
Indoor scene augmentation has become an emerging topic in the field of computer vision and graphics with applications in augmented and virtual reality. However, current state-of-the-art systems using deep neural networks require large datasets for training. In this paper we introduce GSACNet, a contextual scene augmentation system that can be trained with limited scene priors. GSACNet utilizes a novel parametric data augmentation method combined with a Graph Attention and Siamese network architecture followed by an Autoencoder network to facilitate training with small datasets. We show the effectiveness of our proposed system by conducting ablation and comparative studies with alternative systems on the Matterport3D dataset. Our results indicate that our scene augmentation outperforms prior art in scene synthesis with limited scene priors available.
GenScan: A Generative Method for Populating Parametric 3D Scan Datasets
Dec 07, 2020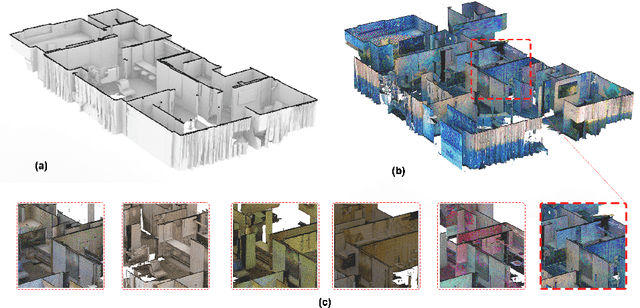
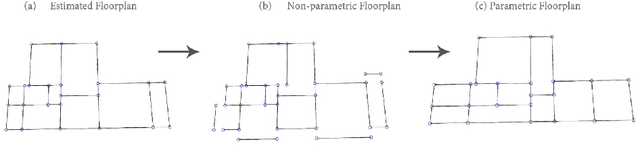


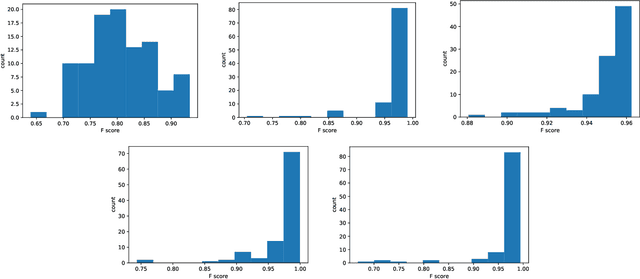
The availability of rich 3D datasets corresponding to the geometrical complexity of the built environments is considered an ongoing challenge for 3D deep learning methodologies. To address this challenge, we introduce GenScan, a generative system that populates synthetic 3D scan datasets in a parametric fashion. The system takes an existing captured 3D scan as an input and outputs alternative variations of the building layout including walls, doors, and furniture with corresponding textures. GenScan is a fully automated system that can also be manually controlled by a user through an assigned user interface. Our proposed system utilizes a combination of a hybrid deep neural network and a parametrizer module to extract and transform elements of a given 3D scan. GenScan takes advantage of style transfer techniques to generate new textures for the generated scenes. We believe our system would facilitate data augmentation to expand the currently limited 3D geometry datasets commonly used in 3D computer vision, generative design, and general 3D deep learning tasks.
Extending DeepSDF for automatic 3D shape retrieval and similarity transform estimation
May 05, 2020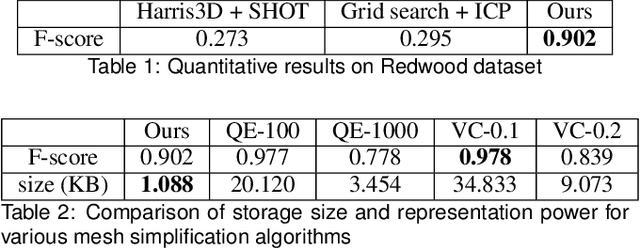
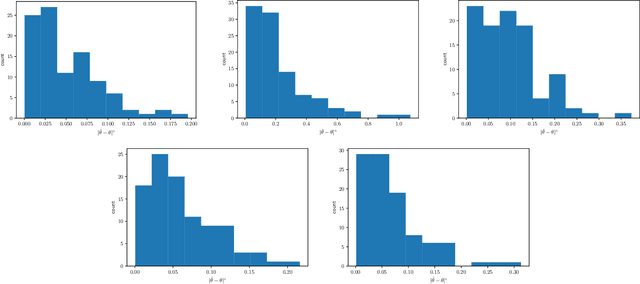
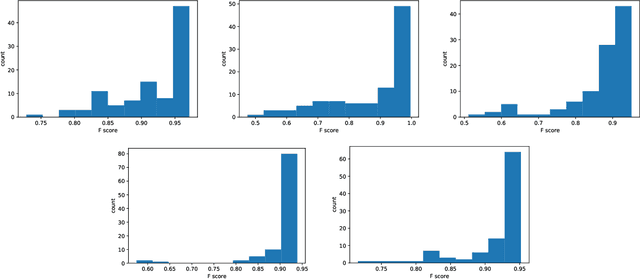
Recent advances in computer graphics and computer vision have allowed for the development of neural network based generative models for 3D shapes based on signed distance functions (SDFs). These models are useful for shape representation, retrieval and completion. However, this approach to shape retrieval and completion has been limited by the need to have query shapes in the same canonical scale and pose as those observed during training, restricting its effectiveness to real world scenes. In this work, we present a formulation that overcomes this issue by jointly estimating the shape and similarity transformation parameters. We conduct experiments to demonstrate the effectiveness of this formulation on synthetic and real datasets and report favorable comparisons to strong baselines. Finally, we also emphasize the viability of this approach as a form of data compression useful in augmented reality scenarios.
People as Sensors: Imputing Maps from Human Actions
Jan 08, 2019

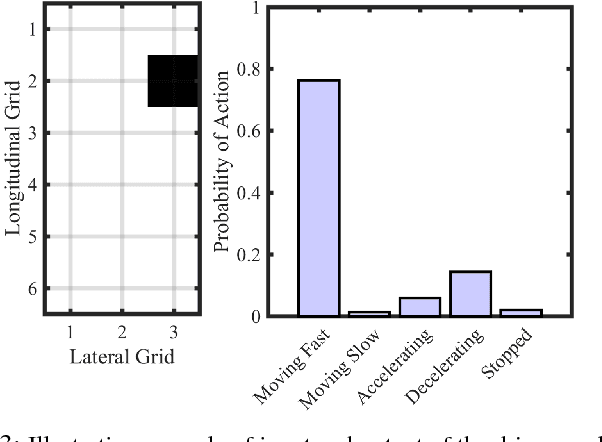
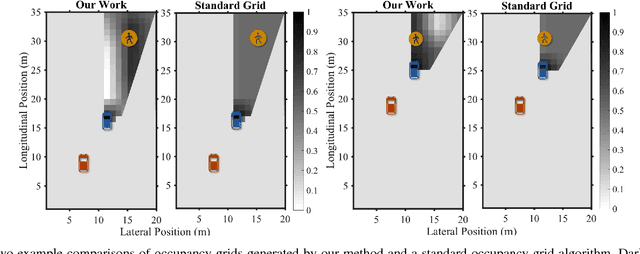
Despite growing attention in autonomy, there are still many open problems, including how autonomous vehicles will interact and communicate with other agents, such as human drivers and pedestrians. Unlike most approaches that focus on pedestrian detection and planning for collision avoidance, this paper considers modeling the interaction between human drivers and pedestrians and how it might influence map estimation, as a proxy for detection. We take a mapping inspired approach and incorporate people as sensors into mapping frameworks. By taking advantage of other agents' actions, we demonstrate how we can impute portions of the map that would otherwise be occluded. We evaluate our framework in human driving experiments and on real-world data, using occupancy grids and landmark-based mapping approaches. Our approach significantly improves overall environment awareness and out-performs standard mapping techniques.