 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Scene Augmentation and Synthesis via GSACNet
Mar 29, 2021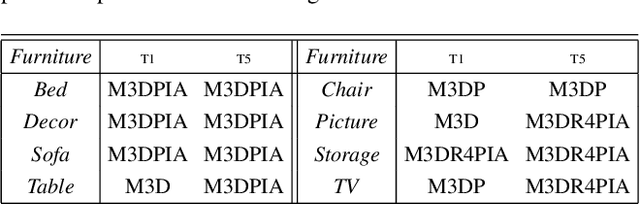
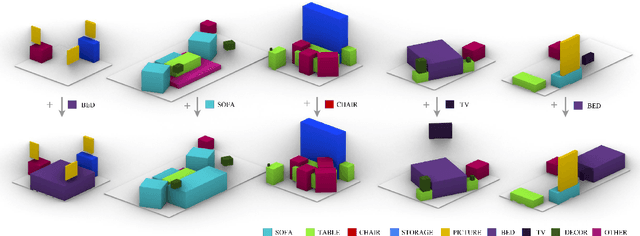
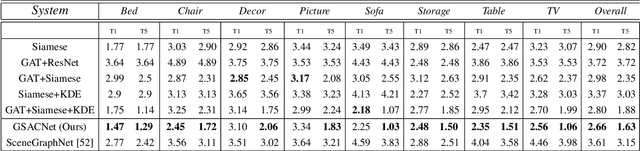
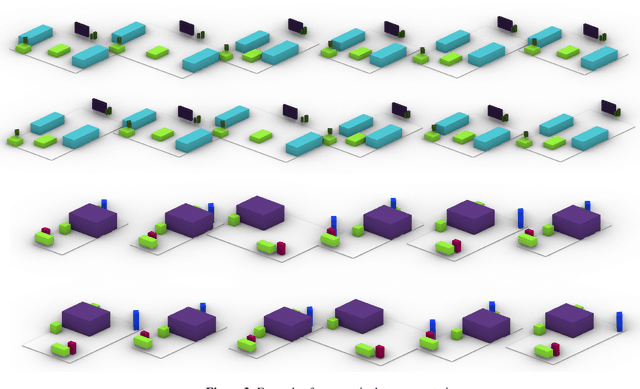
Indoor scene augmentation has become an emerging topic in the field of computer vision and graphics with applications in augmented and virtual reality. However, current state-of-the-art systems using deep neural networks require large datasets for training. In this paper we introduce GSACNet, a contextual scene augmentation system that can be trained with limited scene priors. GSACNet utilizes a novel parametric data augmentation method combined with a Graph Attention and Siamese network architecture followed by an Autoencoder network to facilitate training with small datasets. We show the effectiveness of our proposed system by conducting ablation and comparative studies with alternative systems on the Matterport3D dataset. Our results indicate that our scene augmentation outperforms prior art in scene synthesis with limited scene priors available.