 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Urban Ecologies: Automated Building Archetype Generation through Self-Supervised Learning for Energy Modeling
Apr 11, 2024As the global population and urbanization expand, the building sector has emerged as the predominant energy consumer and carbon emission contributor. The need for innovative Urban Building Energy Modeling grows, yet existing building archetypes often fail to capture the unique attributes of local buildings and the nuanced distinctions between different cities, jeopardizing the precision of energy modeling. This paper presents an alternative tool employing self-supervised learning to distill complex geometric data into representative, locale-specific archetypes. This study attempts to foster a new paradigm of interaction with built environments, incorporating local parameters to conduct bespoke energy simulations at the community level. The catered archetypes can augment the precision and applicability of energy consumption modeling at different scales across diverse building inventories. This tool provides a potential solution that encourages the exploration of emerging local ecologies. By integrating building envelope characteristics and cultural granularity into the building archetype generation process, we seek a future where architecture and urban design are intricately interwoven with the energy sector in shaping our built environments.
MARL: Multi-scale Archetype Representation Learning for Urban Building Energy Modeling
Sep 29, 2023Building archetypes, representative models of building stock, are crucial for precise energy simulations in Urban Building Energy Modeling. The current widely adopted building archetypes are developed on a nationwide scale, potentially neglecting the impact of local buildings' geometric specificities. We present Multi-scale Archetype Representation Learning (MARL), an approach that leverages representation learning to extract geometric features from a specific building stock. Built upon VQ-AE, MARL encodes building footprints and purifies geometric information into latent vectors constrained by multiple architectural downstream tasks. These tailored representations are proven valuable for further clustering and building energy modeling. The advantages of our algorithm are its adaptability with respect to the different building footprint sizes, the ability for automatic generation across multi-scale regions, and the preservation of geometric features across neighborhoods and local ecologies. In our study spanning five regions in LA County, we show MARL surpasses both conventional and VQ-AE extracted archetypes in performance. Results demonstrate that geometric feature embeddings significantly improve the accuracy and reliability of energy consumption estimates. Code, dataset and trained models are publicly available: https://github.com/ZixunHuang1997/MARL-BuildingEnergyEstimation
Mutual Scene Synthesis for Mixed Reality Telepresence
Apr 01, 2022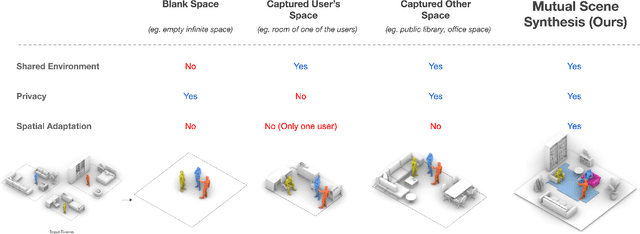
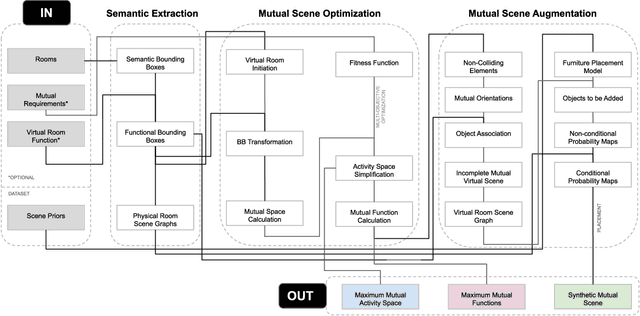
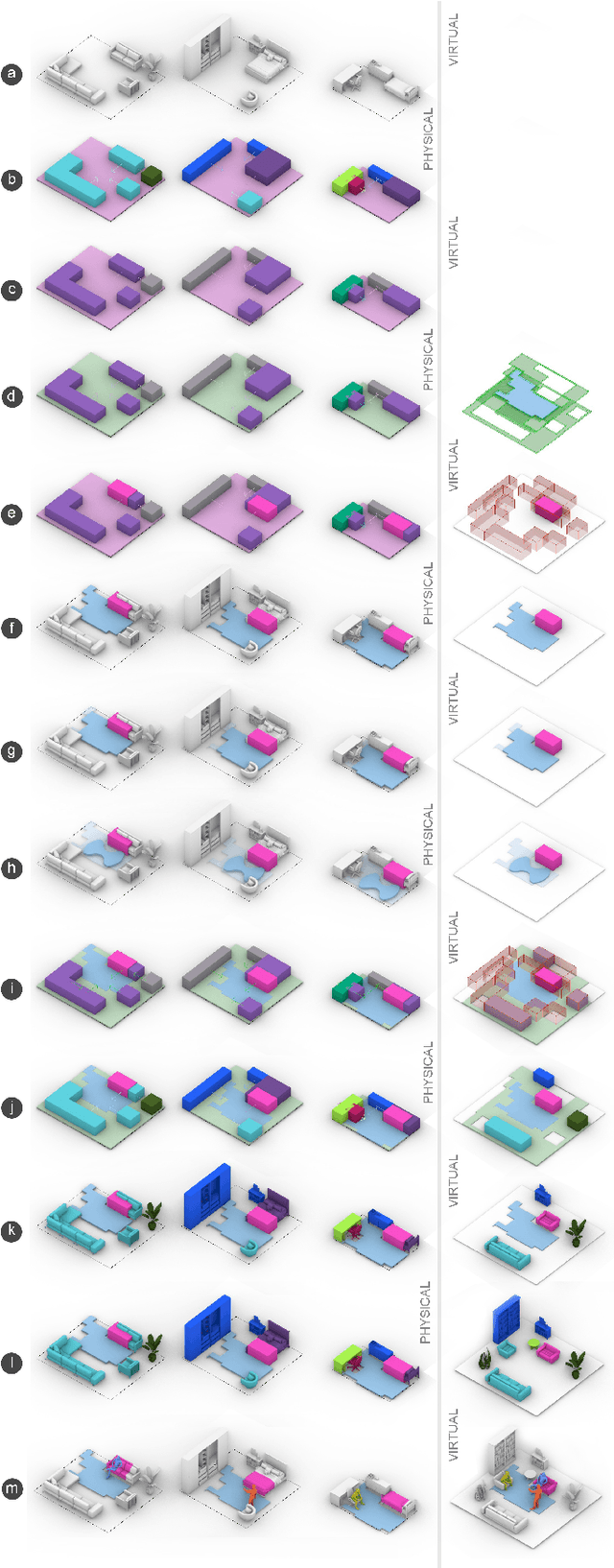
Remote telepresence via next-generation mixed reality platforms can provide higher levels of immersion for computer-mediated communications, allowing participants to engage in a wide spectrum of activities, previously not possible in 2D screen-based communication methods. However, as mixed reality experiences are limited to the local physical surrounding of each user, finding a common virtual ground where users can freely move and interact with each other is challenging. In this paper, we propose a novel mutual scene synthesis method that takes the participants' spaces as input, and generates a virtual synthetic scene that corresponds to the functional features of all participants' local spaces. Our method combines a mutual function optimization module with a deep-learning conditional scene augmentation process to generate a scene mutually and physically accessible to all participants of a mixed reality telepresence scenario. The synthesized scene can hold mutual walkable, sittable and workable functions, all corresponding to physical objects in the users' real environments. We perform experiments using the MatterPort3D dataset and conduct comparative user studies to evaluate the effectiveness of our system. Our results show that our proposed approach can be a promising research direction for facilitating contextualized telepresence systems for next-generation spatial computing platforms.
Contextual Scene Augmentation and Synthesis via GSACNet
Mar 29, 2021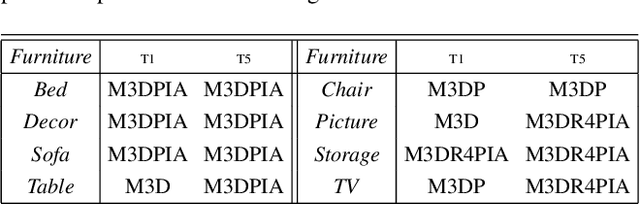
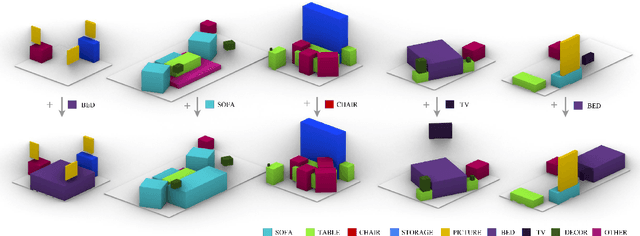
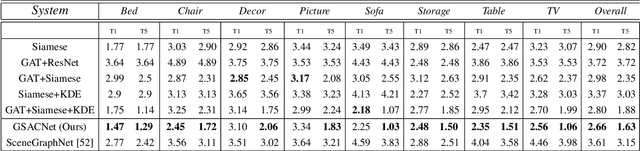
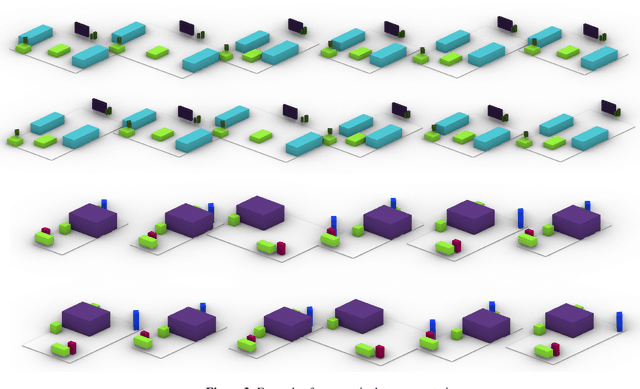
Indoor scene augmentation has become an emerging topic in the field of computer vision and graphics with applications in augmented and virtual reality. However, current state-of-the-art systems using deep neural networks require large datasets for training. In this paper we introduce GSACNet, a contextual scene augmentation system that can be trained with limited scene priors. GSACNet utilizes a novel parametric data augmentation method combined with a Graph Attention and Siamese network architecture followed by an Autoencoder network to facilitate training with small datasets. We show the effectiveness of our proposed system by conducting ablation and comparative studies with alternative systems on the Matterport3D dataset. Our results indicate that our scene augmentation outperforms prior art in scene synthesis with limited scene priors available.
GenScan: A Generative Method for Populating Parametric 3D Scan Datasets
Dec 07, 2020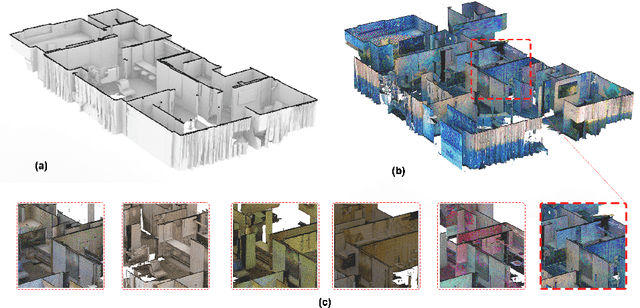
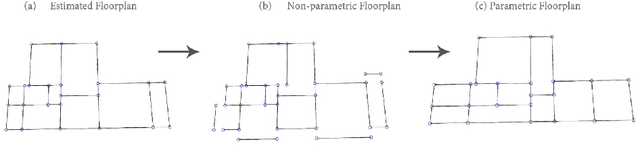


The availability of rich 3D datasets corresponding to the geometrical complexity of the built environments is considered an ongoing challenge for 3D deep learning methodologies. To address this challenge, we introduce GenScan, a generative system that populates synthetic 3D scan datasets in a parametric fashion. The system takes an existing captured 3D scan as an input and outputs alternative variations of the building layout including walls, doors, and furniture with corresponding textures. GenScan is a fully automated system that can also be manually controlled by a user through an assigned user interface. Our proposed system utilizes a combination of a hybrid deep neural network and a parametrizer module to extract and transform elements of a given 3D scan. GenScan takes advantage of style transfer techniques to generate new textures for the generated scenes. We believe our system would facilitate data augmentation to expand the currently limited 3D geometry datasets commonly used in 3D computer vision, generative design, and general 3D deep learning tasks.
SceneGen: Generative Contextual Scene Augmentation using Scene Graph Priors
Sep 30, 2020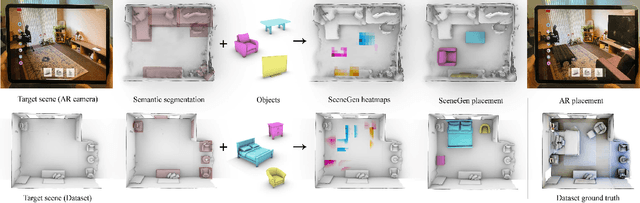


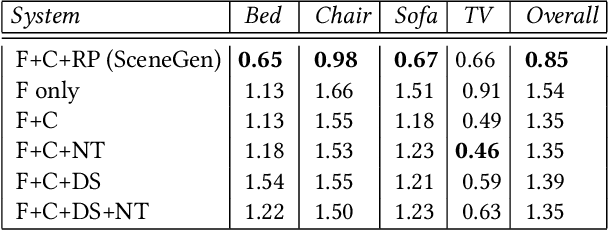
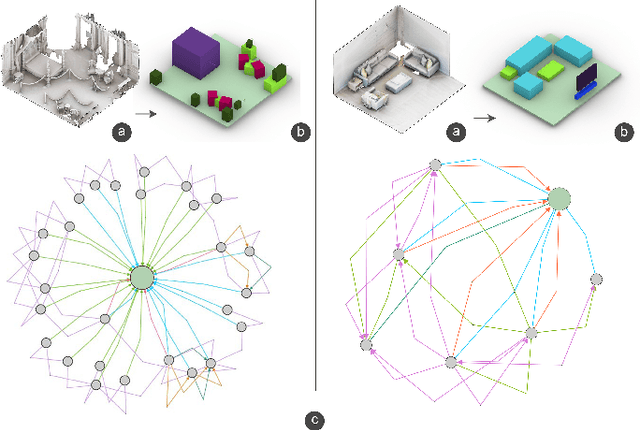
Spatial computing experiences are constrained by the real-world surroundings of the user. In such experiences, augmenting virtual objects to existing scenes require a contextual approach, where geometrical conflicts are avoided, and functional and plausible relationships to other objects are maintained in the target environment. Yet, due to the complexity and diversity of user environments, automatically calculating ideal positions of virtual content that is adaptive to the context of the scene is considered a challenging task. Motivated by this problem, in this paper we introduce SceneGen, a generative contextual augmentation framework that predicts virtual object positions and orientations within existing scenes. SceneGen takes a semantically segmented scene as input, and outputs positional and orientational probability maps for placing virtual content. We formulate a novel spatial Scene Graph representation, which encapsulates explicit topological properties between objects, object groups, and the room. We believe providing explicit and intuitive features plays an important role in informative content creation and user interaction of spatial computing settings, a quality that is not captured in implicit models. We use kernel density estimation (KDE) to build a multivariate conditional knowledge model trained using prior spatial Scene Graphs extracted from real-world 3D scanned data. To further capture orientational properties, we develop a fast pose annotation tool to extend current real-world datasets with orientational labels. Finally, to demonstrate our system in action, we develop an Augmented Reality application, in which objects can be contextually augmented in real-time.
Optimization and Manipulation of Contextual Mutual Spaces for Multi-User Virtual and Augmented Reality Interaction
Oct 14, 2019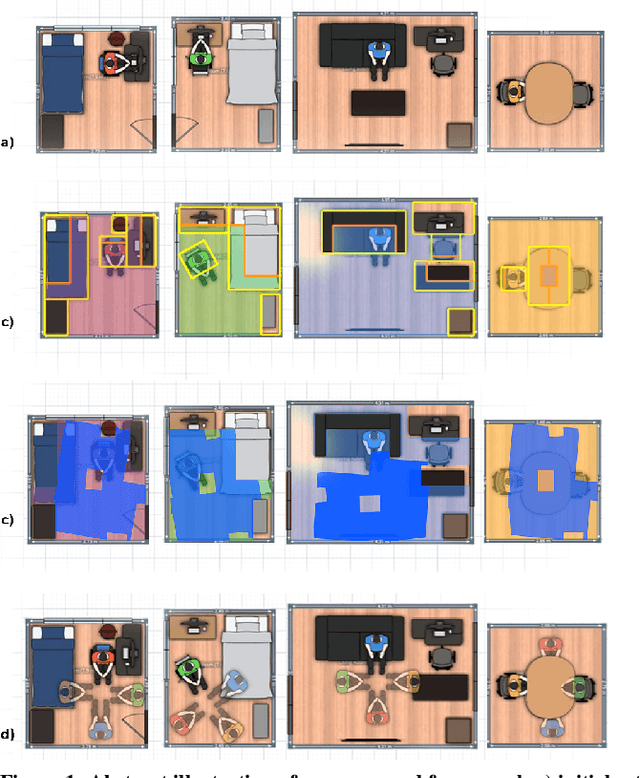
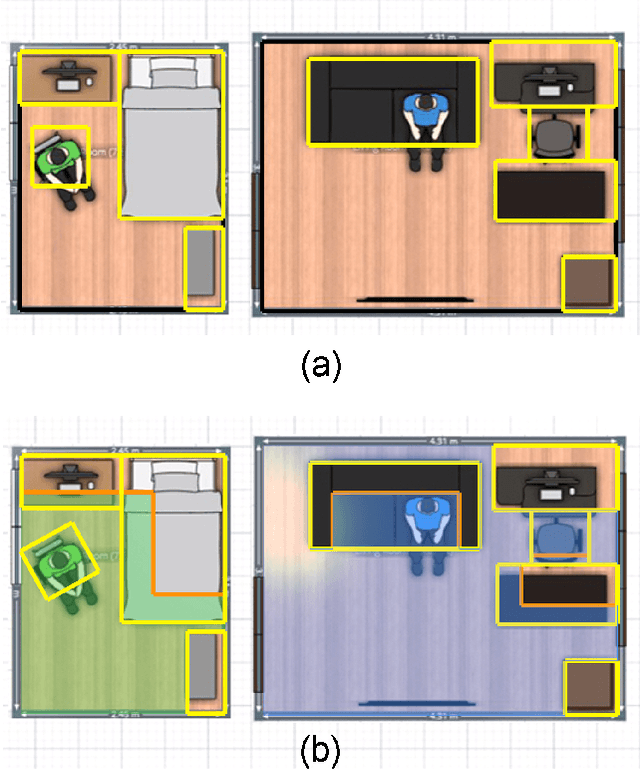

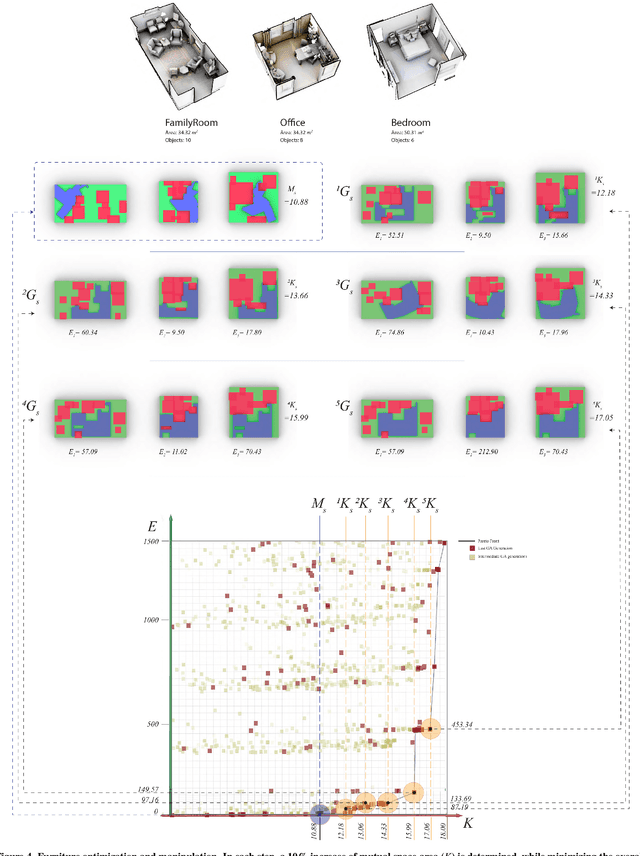
Spatial computing experiences are physically constrained by the geometry and semantics of the local user environment. This limitation is elevated in remote multi-user interaction scenarios, where finding a common virtual ground physically accessible for all participants becomes challenging. Locating a common accessible virtual ground is difficult for the users themselves, particularly if they are not aware of the spatial properties of other participants. In this paper, we introduce a framework to generate an optimal mutual virtual space for a multi-user interaction setting. The framework further recommends the movement of surrounding furniture objects that expand the size of the mutual space with minimal physical effort. Finally, we demonstrate the performance of our solution on real-world datasets and also a real HoloLens application. Results show the proposed algorithm can effectively discover optimal shareable space for multi-user virtual interaction and hence facilitate remote spatial computing communication in various collaborative workflows.