 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneGen: Generative Contextual Scene Augmentation using Scene Graph Priors
Paper and Code
Sep 30, 2020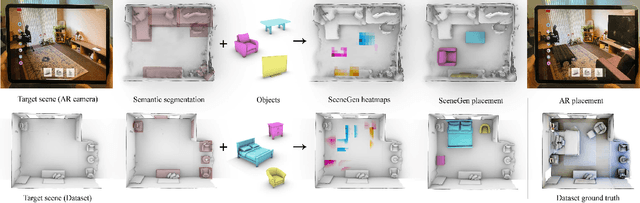


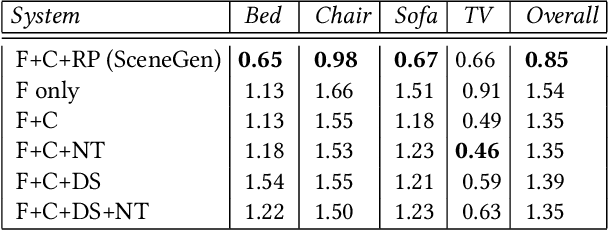
Spatial computing experiences are constrained by the real-world surroundings of the user. In such experiences, augmenting virtual objects to existing scenes require a contextual approach, where geometrical conflicts are avoided, and functional and plausible relationships to other objects are maintained in the target environment. Yet, due to the complexity and diversity of user environments, automatically calculating ideal positions of virtual content that is adaptive to the context of the scene is considered a challenging task. Motivated by this problem, in this paper we introduce SceneGen, a generative contextual augmentation framework that predicts virtual object positions and orientations within existing scenes. SceneGen takes a semantically segmented scene as input, and outputs positional and orientational probability maps for placing virtual content. We formulate a novel spatial Scene Graph representation, which encapsulates explicit topological properties between objects, object groups, and the room. We believe providing explicit and intuitive features plays an important role in informative content creation and user interaction of spatial computing settings, a quality that is not captured in implicit models. We use kernel density estimation (KDE) to build a multivariate conditional knowledge model trained using prior spatial Scene Graphs extracted from real-world 3D scanned data. To further capture orientational properties, we develop a fast pose annotation tool to extend current real-world datasets with orientational labels. Finally, to demonstrate our system in action, we develop an Augmented Reality application, in which objects can be contextually augmented in real-time.