 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2024 NASA SUITS Report: LLM-Driven Immersive Augmented Reality User Interface for Robotics and Space Exploration
Jul 01, 2025As modern computing advances, new interaction paradigms have emerged, particularly in Augmented Reality (AR), which overlays virtual interfaces onto physical objects. This evolution poses challenges in machine perception, especially for tasks like 3D object pose estimation in complex, dynamic environments. Our project addresses critical issues in human-robot interaction within mobile AR, focusing on non-intrusive, spatially aware interfaces. We present URSA, an LLM-driven immersive AR system developed for NASA's 2023-2024 SUITS challenge, targeting future spaceflight needs such as the Artemis missions. URSA integrates three core technologies: a head-mounted AR device (e.g., HoloLens) for intuitive visual feedback, voice control powered by large language models for hands-free interaction, and robot tracking algorithms that enable accurate 3D localization in dynamic settings. To enhance precision, we leverage digital twin localization technologies, using datasets like DTTD-Mobile and specialized hardware such as the ZED2 camera for real-world tracking under noise and occlusion. Our system enables real-time robot control and monitoring via an AR interface, even in the absence of ground-truth sensors--vital for hazardous or remote operations. Key contributions include: (1) a non-intrusive AR interface with LLM-based voice input; (2) a ZED2-based dataset tailored for non-rigid robotic bodies; (3) a Local Mission Control Console (LMCC) for mission visualization; (4) a transformer-based 6DoF pose estimator (DTTDNet) optimized for depth fusion and real-time tracking; and (5) end-to-end integration for astronaut mission support. This work advances digital twin applications in robotics, offering scalable solutions for both aerospace and industrial domains.
Towards Subcentimeter Accuracy Digital-Twin Tracking via An RGBD-based Transformer Model and A Comprehensive Mobile Dataset
Sep 24, 2023The potential of digital twin technology, involving the creation of precise digital replicas of physical objects, to reshape AR experiences in 3D object tracking and localization scenarios is significant. However, enabling 3D object tracking with subcentimeter accuracy in dynamic mobile AR environments remains a formidable challenge. These scenarios often require a more robust pose estimator capable of handling the inherent sensor-level measurement noise. In this paper, recognizing the absence of comprehensive solutions in existing literature, we build upon our previous work, the Digital Twin Tracking Dataset (DTTD), to address these challenges in mobile AR settings. Specifically, we propose a transformer-based 6DoF pose estimator designed to withstand the challenges posed by noisy depth data. Simultaneously, we introduce a novel RGBD dataset captured using a cutting-edge mobile sensor, the iPhone 14 Pro, expanding the applicability of our approach to iPhone sensor data. Through extensive experimentation and in-depth analysis, we illustrate the effectiveness of our methods in the face of significant depth data errors, surpassing the performance of existing baselines. Code will be made publicly available.
Digital Twin Tracking Dataset : A New RGB+Depth 3D Dataset for Longer-Range Object Tracking Applications
Feb 12, 2023


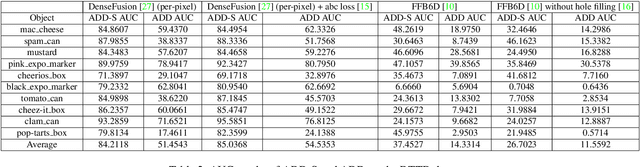
Digital twin is a problem of augmenting real objects with their digital counterparts. It can underpin a wide range of applications in augmented reality (AR), autonomy, and UI/UX. A critical component in a good digital twin system is real-time, accurate 3D object tracking. Most existing works solve 3D object tracking through the lens of robotic grasping, employ older generations of depth sensors, and measure performance metrics that may not apply to other digital twin applications such as in AR. In this work, we create a novel RGB-D dataset, called Digital-Twin Tracking Dataset (DTTD), to enable further research of the problem and extend potential solutions towards longer ranges and mm localization accuracy. To reduce point cloud noise from the input source, we select the latest Microsoft Azure Kinect as the state-of-the-art time-of-flight (ToF) camera. In total, 103 scenes of 10 common off-the-shelf objects with rich textures are recorded, with each frame annotated with a per-pixel semantic segmentation and ground-truth object poses provided by a commercial motion capturing system. Through experiments, we demonstrate that DTTD can help researchers develop future object tracking methods and analyze new challenges. We provide the dataset, data generation, annotation, and model evaluation pipeline as open source code at: https://github.com/augcog/DTTDv1.
Mutual Scene Synthesis for Mixed Reality Telepresence
Apr 01, 2022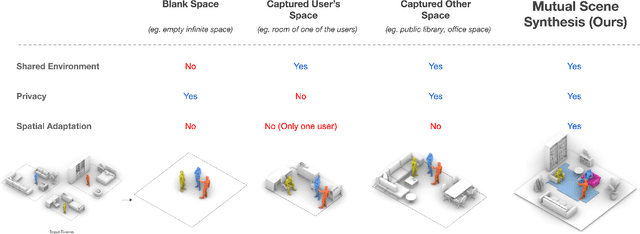
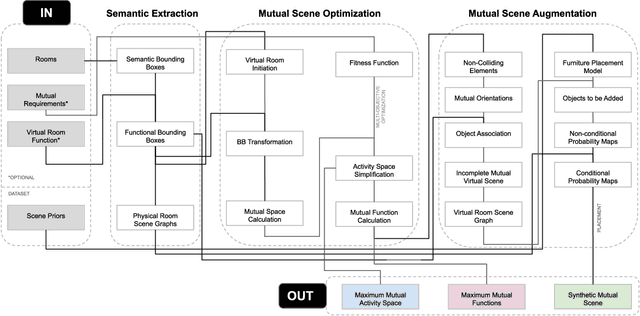
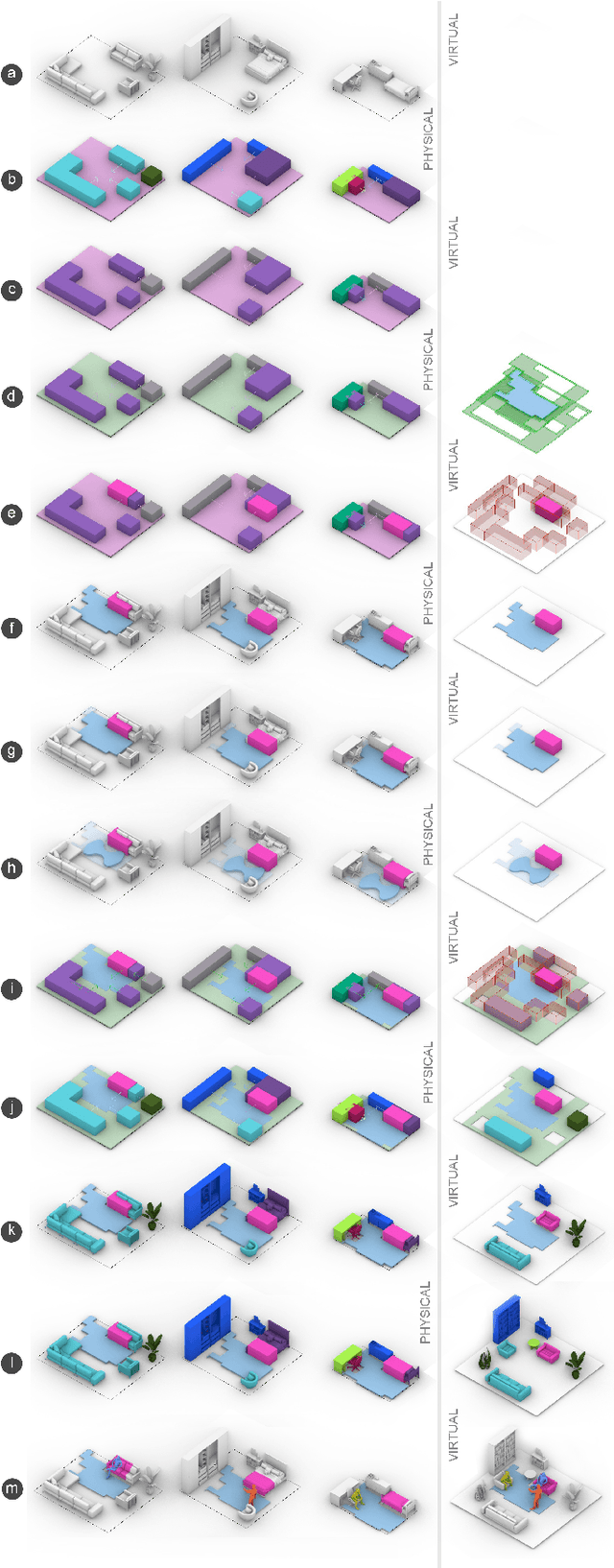
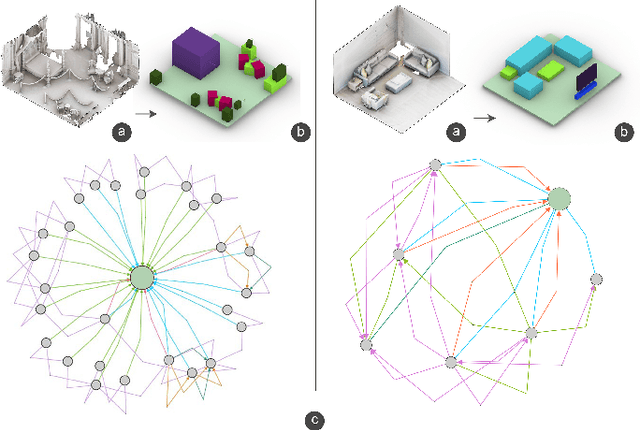
Remote telepresence via next-generation mixed reality platforms can provide higher levels of immersion for computer-mediated communications, allowing participants to engage in a wide spectrum of activities, previously not possible in 2D screen-based communication methods. However, as mixed reality experiences are limited to the local physical surrounding of each user, finding a common virtual ground where users can freely move and interact with each other is challenging. In this paper, we propose a novel mutual scene synthesis method that takes the participants' spaces as input, and generates a virtual synthetic scene that corresponds to the functional features of all participants' local spaces. Our method combines a mutual function optimization module with a deep-learning conditional scene augmentation process to generate a scene mutually and physically accessible to all participants of a mixed reality telepresence scenario. The synthesized scene can hold mutual walkable, sittable and workable functions, all corresponding to physical objects in the users' real environments. We perform experiments using the MatterPort3D dataset and conduct comparative user studies to evaluate the effectiveness of our system. Our results show that our proposed approach can be a promising research direction for facilitating contextualized telepresence systems for next-generation spatial computing platforms.
Contextual Scene Augmentation and Synthesis via GSACNet
Mar 29, 2021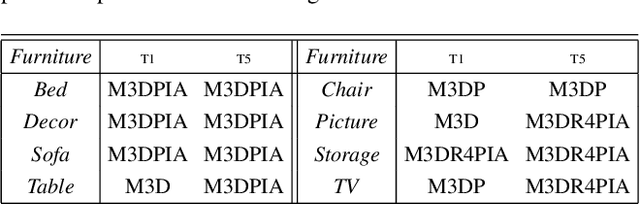
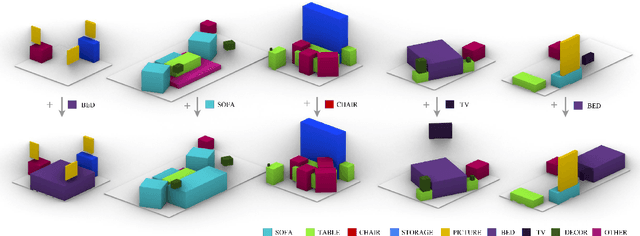
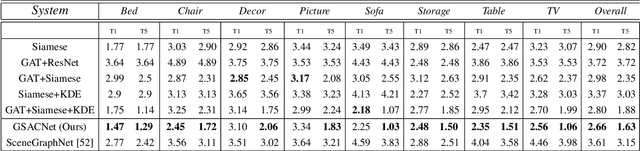
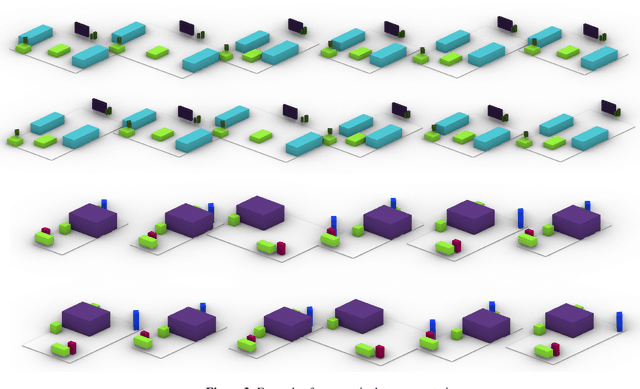
Indoor scene augmentation has become an emerging topic in the field of computer vision and graphics with applications in augmented and virtual reality. However, current state-of-the-art systems using deep neural networks require large datasets for training. In this paper we introduce GSACNet, a contextual scene augmentation system that can be trained with limited scene priors. GSACNet utilizes a novel parametric data augmentation method combined with a Graph Attention and Siamese network architecture followed by an Autoencoder network to facilitate training with small datasets. We show the effectiveness of our proposed system by conducting ablation and comparative studies with alternative systems on the Matterport3D dataset. Our results indicate that our scene augmentation outperforms prior art in scene synthesis with limited scene priors available.
GenScan: A Generative Method for Populating Parametric 3D Scan Datasets
Dec 07, 2020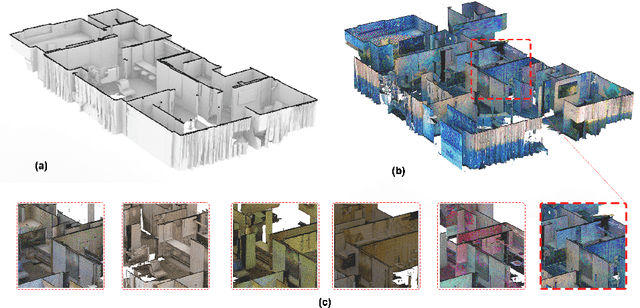
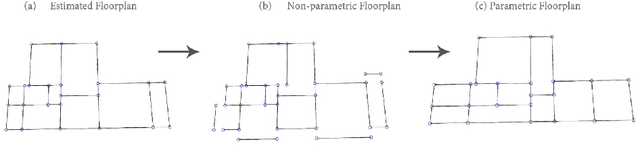


The availability of rich 3D datasets corresponding to the geometrical complexity of the built environments is considered an ongoing challenge for 3D deep learning methodologies. To address this challenge, we introduce GenScan, a generative system that populates synthetic 3D scan datasets in a parametric fashion. The system takes an existing captured 3D scan as an input and outputs alternative variations of the building layout including walls, doors, and furniture with corresponding textures. GenScan is a fully automated system that can also be manually controlled by a user through an assigned user interface. Our proposed system utilizes a combination of a hybrid deep neural network and a parametrizer module to extract and transform elements of a given 3D scan. GenScan takes advantage of style transfer techniques to generate new textures for the generated scenes. We believe our system would facilitate data augmentation to expand the currently limited 3D geometry datasets commonly used in 3D computer vision, generative design, and general 3D deep learning tasks.
SceneGen: Generative Contextual Scene Augmentation using Scene Graph Priors
Sep 30, 2020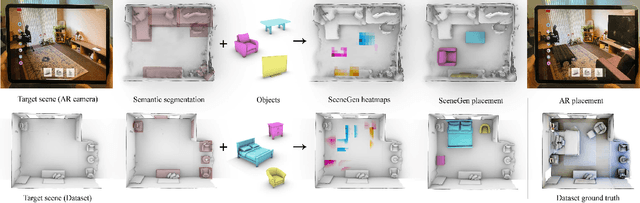


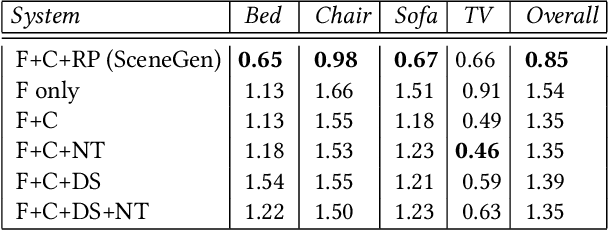
Spatial computing experiences are constrained by the real-world surroundings of the user. In such experiences, augmenting virtual objects to existing scenes require a contextual approach, where geometrical conflicts are avoided, and functional and plausible relationships to other objects are maintained in the target environment. Yet, due to the complexity and diversity of user environments, automatically calculating ideal positions of virtual content that is adaptive to the context of the scene is considered a challenging task. Motivated by this problem, in this paper we introduce SceneGen, a generative contextual augmentation framework that predicts virtual object positions and orientations within existing scenes. SceneGen takes a semantically segmented scene as input, and outputs positional and orientational probability maps for placing virtual content. We formulate a novel spatial Scene Graph representation, which encapsulates explicit topological properties between objects, object groups, and the room. We believe providing explicit and intuitive features plays an important role in informative content creation and user interaction of spatial computing settings, a quality that is not captured in implicit models. We use kernel density estimation (KDE) to build a multivariate conditional knowledge model trained using prior spatial Scene Graphs extracted from real-world 3D scanned data. To further capture orientational properties, we develop a fast pose annotation tool to extend current real-world datasets with orientational labels. Finally, to demonstrate our system in action, we develop an Augmented Reality application, in which objects can be contextually augmented in real-time.
Extending DeepSDF for automatic 3D shape retrieval and similarity transform estimation
May 05, 2020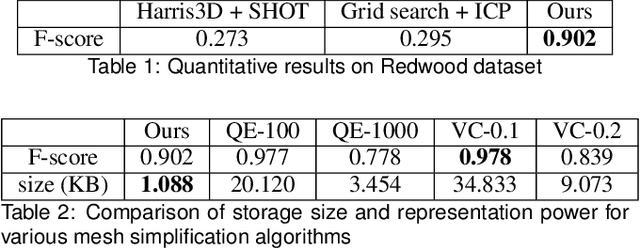
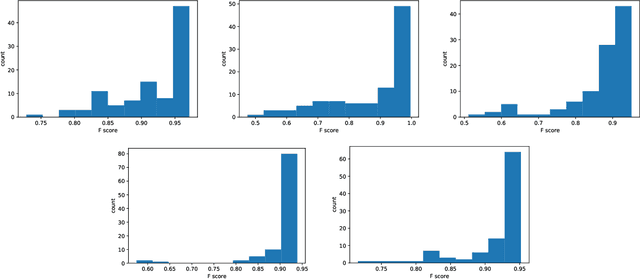
Recent advances in computer graphics and computer vision have allowed for the development of neural network based generative models for 3D shapes based on signed distance functions (SDFs). These models are useful for shape representation, retrieval and completion. However, this approach to shape retrieval and completion has been limited by the need to have query shapes in the same canonical scale and pose as those observed during training, restricting its effectiveness to real world scenes. In this work, we present a formulation that overcomes this issue by jointly estimating the shape and similarity transformation parameters. We conduct experiments to demonstrate the effectiveness of this formulation on synthetic and real datasets and report favorable comparisons to strong baselines. Finally, we also emphasize the viability of this approach as a form of data compression useful in augmented reality scenarios.
Optimization and Manipulation of Contextual Mutual Spaces for Multi-User Virtual and Augmented Reality Interaction
Oct 14, 2019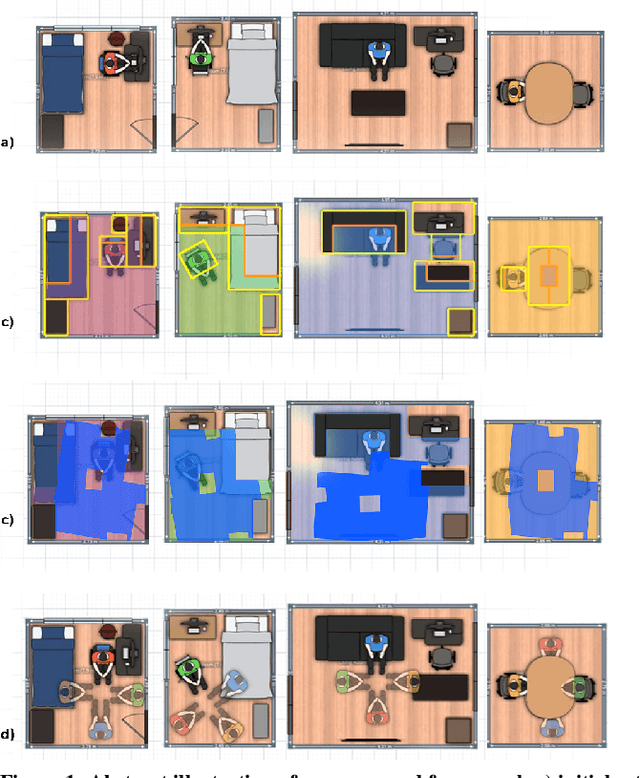
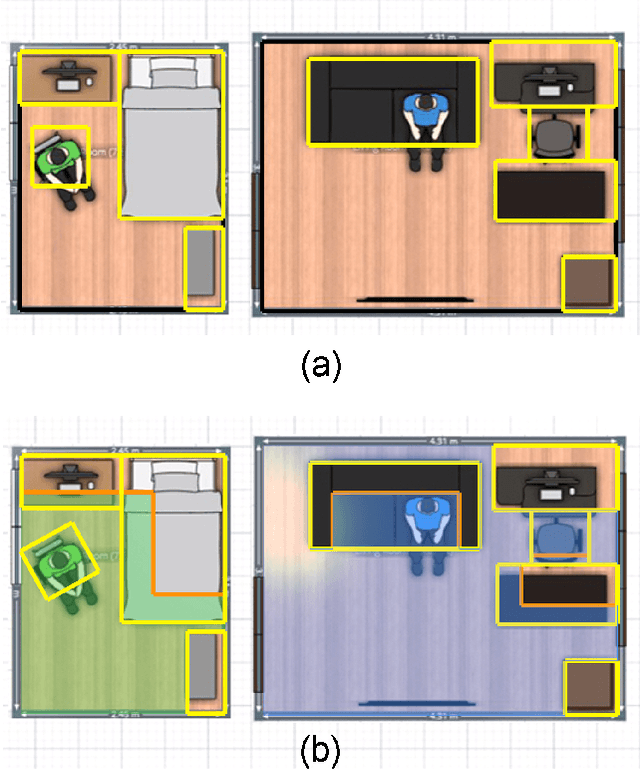

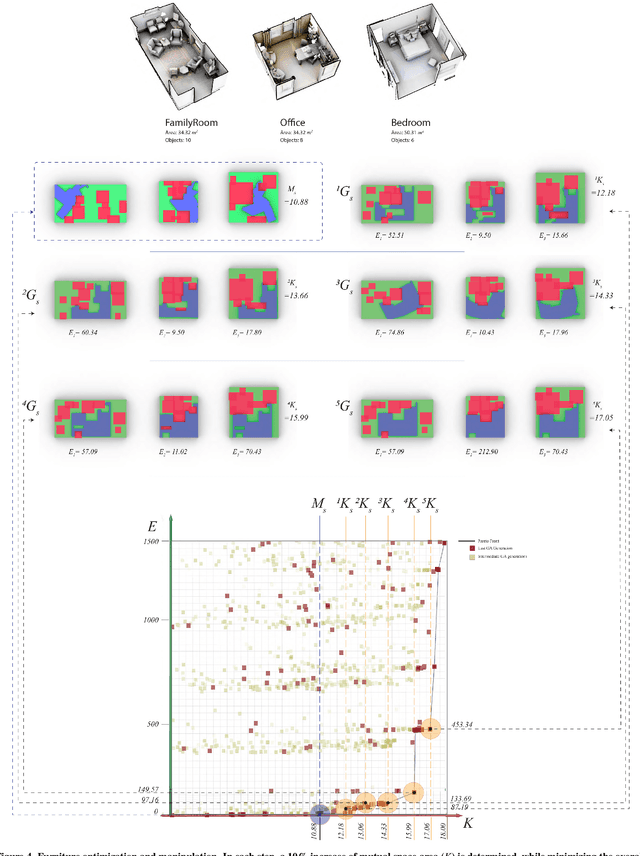
Spatial computing experiences are physically constrained by the geometry and semantics of the local user environment. This limitation is elevated in remote multi-user interaction scenarios, where finding a common virtual ground physically accessible for all participants becomes challenging. Locating a common accessible virtual ground is difficult for the users themselves, particularly if they are not aware of the spatial properties of other participants. In this paper, we introduce a framework to generate an optimal mutual virtual space for a multi-user interaction setting. The framework further recommends the movement of surrounding furniture objects that expand the size of the mutual space with minimal physical effort. Finally, we demonstrate the performance of our solution on real-world datasets and also a real HoloLens application. Results show the proposed algorithm can effectively discover optimal shareable space for multi-user virtual interaction and hence facilitate remote spatial computing communication in various collaborative workflows.
Modeling Supervisor Safe Sets for Improving Collaboration in Human-Robot Teams
May 09, 2018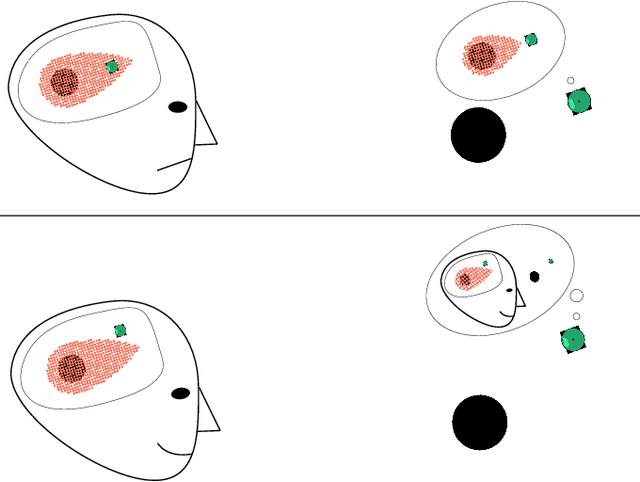
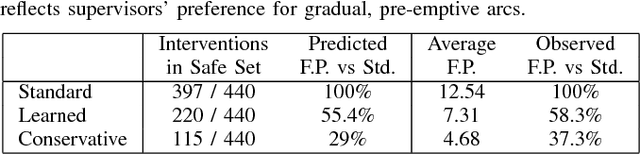
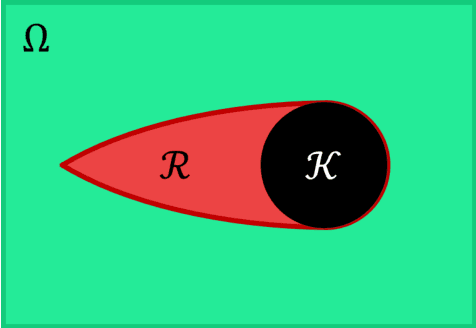
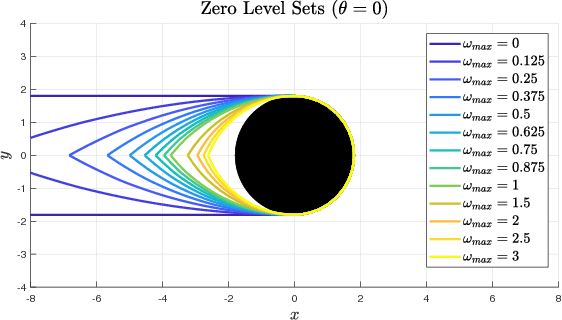
When a human supervisor collaborates with a team of robots, their attention is divided and cognitive resources are at a premium. We aim to optimize the distribution of these resources and the flow of attention. To this end, we propose the model of an idealized supervisor to describe human behavior. Such a supervisor employs a potentially inaccurate internal model of the the robots' dynamics to judge safety. We represent these safety judgements by constructing a safe set from this internal model using reachability theory. When a robot leaves this safe set, the idealized supervisor will intervene to assist, regardless of whether or not the robot remains objectively safe. False positives, where a human supervisor incorrectly judges a robot to be in danger, needlessly consume supervisor attention. In this work, we propose a method that decreases false positives by learning the supervisor's safe set and using that information to govern robot behavior. We prove that robots behaving according to our approach will reduce the occurrence of false positives for our idealized supervisor model. Furthermore, we empirically validate our approach with a user study that demonstrates a significant ($p = 0.0328$) reduction in false positives for our method compared to a baseline safety controller.