 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Scene Synthesis for Mixed Reality Telepresence
Apr 01, 2022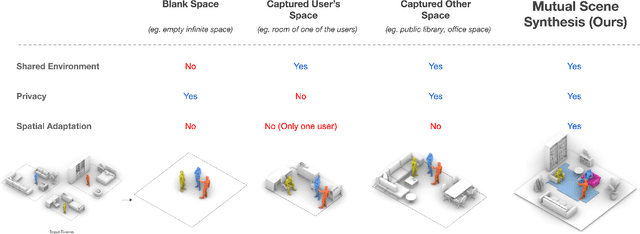
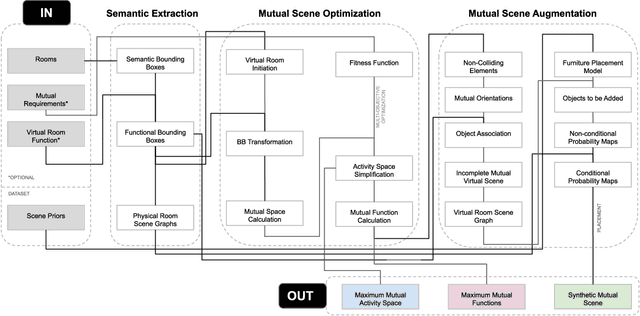
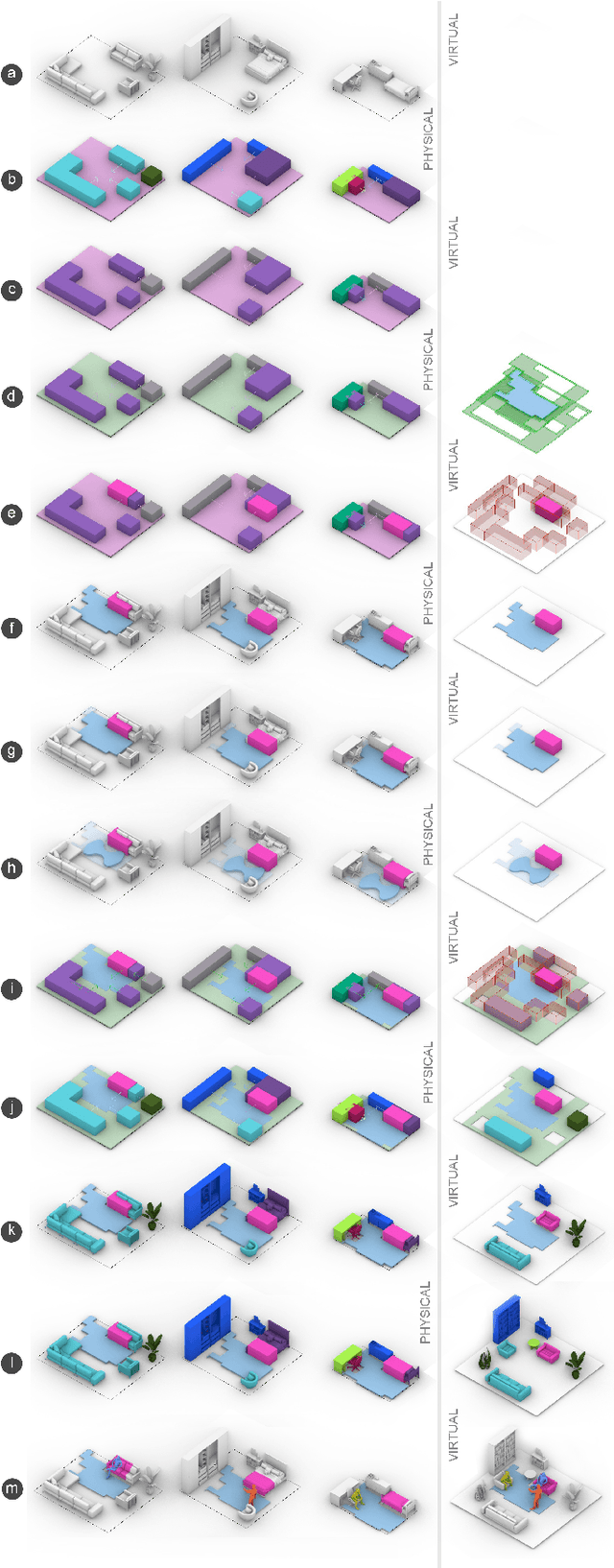
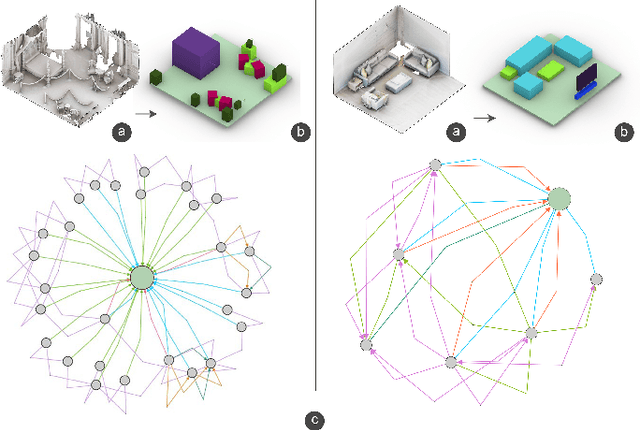
Remote telepresence via next-generation mixed reality platforms can provide higher levels of immersion for computer-mediated communications, allowing participants to engage in a wide spectrum of activities, previously not possible in 2D screen-based communication methods. However, as mixed reality experiences are limited to the local physical surrounding of each user, finding a common virtual ground where users can freely move and interact with each other is challenging. In this paper, we propose a novel mutual scene synthesis method that takes the participants' spaces as input, and generates a virtual synthetic scene that corresponds to the functional features of all participants' local spaces. Our method combines a mutual function optimization module with a deep-learning conditional scene augmentation process to generate a scene mutually and physically accessible to all participants of a mixed reality telepresence scenario. The synthesized scene can hold mutual walkable, sittable and workable functions, all corresponding to physical objects in the users' real environments. We perform experiments using the MatterPort3D dataset and conduct comparative user studies to evaluate the effectiveness of our system. Our results show that our proposed approach can be a promising research direction for facilitating contextualized telepresence systems for next-generation spatial computing platforms.
SelfPose: 3D Egocentric Pose Estimation from a Headset Mounted Camera
Nov 02, 2020


We present a solution to egocentric 3D body pose estimation from monocular images captured from downward looking fish-eye cameras installed on the rim of a head mounted VR device. This unusual viewpoint leads to images with unique visual appearance, with severe self-occlusions and perspective distortions that result in drastic differences in resolution between lower and upper body. We propose an encoder-decoder architecture with a novel multi-branch decoder designed to account for the varying uncertainty in 2D predictions. The quantitative evaluation, on synthetic and real-world datasets, shows that our strategy leads to substantial improvements in accuracy over state of the art egocentric approaches. To tackle the lack of labelled data we also introduced a large photo-realistic synthetic dataset. xR-EgoPose offers high quality renderings of people with diverse skintones, body shapes and clothing, performing a range of actions. Our experiments show that the high variability in our new synthetic training corpus leads to good generalization to real world footage and to state of theart results on real world datasets with ground truth. Moreover, an evaluation on the Human3.6M benchmark shows that the performance of our method is on par with top performing approaches on the more classic problem of 3D human pose from a third person viewpoint.
* 14 pages. arXiv admin note: substantial text overlap with arXiv:1907.10045
xR-EgoPose: Egocentric 3D Human Pose from an HMD Camera
Jul 23, 2019

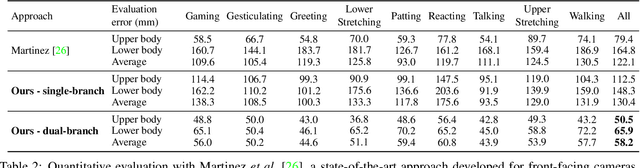

We present a new solution to egocentric 3D body pose estimation from monocular images captured from a downward looking fish-eye camera installed on the rim of a head mounted virtual reality device. This unusual viewpoint, just 2 cm. away from the user's face, leads to images with unique visual appearance, characterized by severe self-occlusions and strong perspective distortions that result in a drastic difference in resolution between lower and upper body. Our contribution is two-fold. Firstly, we propose a new encoder-decoder architecture with a novel dual branch decoder designed specifically to account for the varying uncertainty in the 2D joint locations. Our quantitative evaluation, both on synthetic and real-world datasets, shows that our strategy leads to substantial improvements in accuracy over state of the art egocentric pose estimation approaches. Our second contribution is a new large-scale photorealistic synthetic dataset - xR-EgoPose - offering 383K frames of high quality renderings of people with a diversity of skin tones, body shapes, clothing, in a variety of backgrounds and lighting conditions, performing a range of actions. Our experiments show that the high variability in our new synthetic training corpus leads to good generalization to real world footage and to state of the art results on real world datasets with ground truth. Moreover, an evaluation on the Human3.6M benchmark shows that the performance of our method is on par with top performing approaches on the more classic problem of 3D human pose from a third person viewpoint.