 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumMUSS: Human Motion Understanding using State Space Models
Apr 16, 2024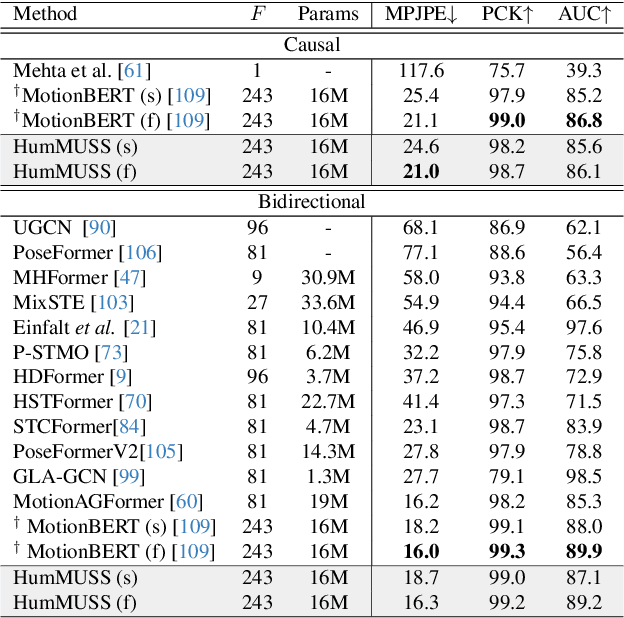
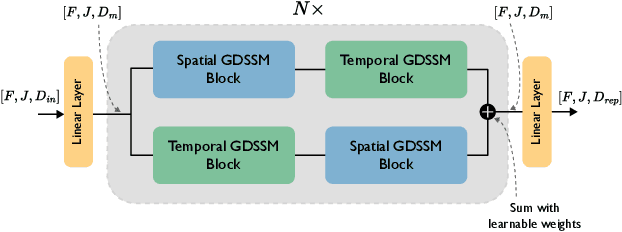
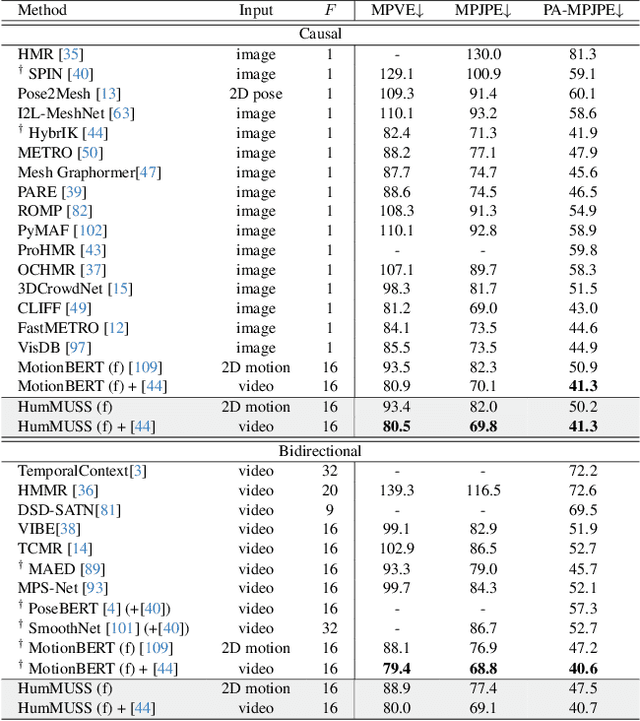
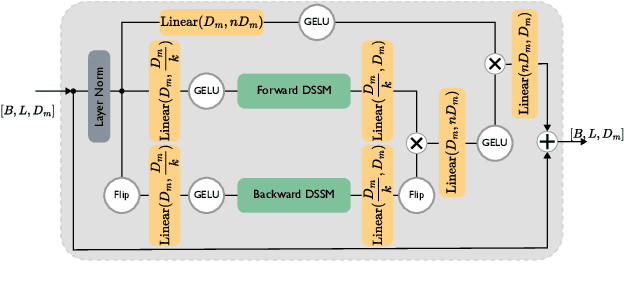
Understanding human motion from video is essential for a range of applications, including pose estimation, mesh recovery and action recognition. While state-of-the-art methods predominantly rely on transformer-based architectures, these approaches have limitations in practical scenarios. Transformers are slower when sequentially predicting on a continuous stream of frames in real-time, and do not generalize to new frame rates. In light of these constraints, we propose a novel attention-free spatiotemporal model for human motion understanding building upon recent advancements in state space models. Our model not only matches the performance of transformer-based models in various motion understanding tasks but also brings added benefits like adaptability to different video frame rates and enhanced training speed when working with longer sequence of keypoints. Moreover, the proposed model supports both offline and real-time applications. For real-time sequential prediction, our model is both memory efficient and several times faster than transformer-based approaches while maintaining their high accuracy.
SelfPose: 3D Egocentric Pose Estimation from a Headset Mounted Camera
Nov 02, 2020
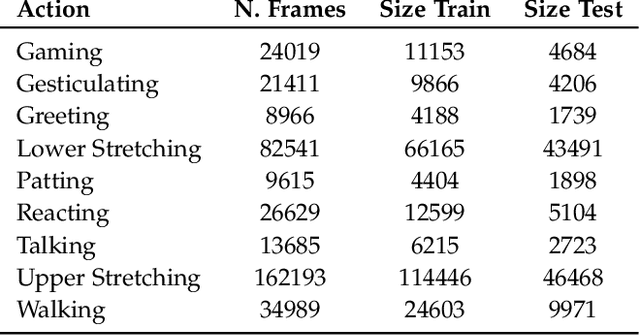


We present a solution to egocentric 3D body pose estimation from monocular images captured from downward looking fish-eye cameras installed on the rim of a head mounted VR device. This unusual viewpoint leads to images with unique visual appearance, with severe self-occlusions and perspective distortions that result in drastic differences in resolution between lower and upper body. We propose an encoder-decoder architecture with a novel multi-branch decoder designed to account for the varying uncertainty in 2D predictions. The quantitative evaluation, on synthetic and real-world datasets, shows that our strategy leads to substantial improvements in accuracy over state of the art egocentric approaches. To tackle the lack of labelled data we also introduced a large photo-realistic synthetic dataset. xR-EgoPose offers high quality renderings of people with diverse skintones, body shapes and clothing, performing a range of actions. Our experiments show that the high variability in our new synthetic training corpus leads to good generalization to real world footage and to state of theart results on real world datasets with ground truth. Moreover, an evaluation on the Human3.6M benchmark shows that the performance of our method is on par with top performing approaches on the more classic problem of 3D human pose from a third person viewpoint.
* 14 pages. arXiv admin note: substantial text overlap with arXiv:1907.10045
xR-EgoPose: Egocentric 3D Human Pose from an HMD Camera
Jul 23, 2019

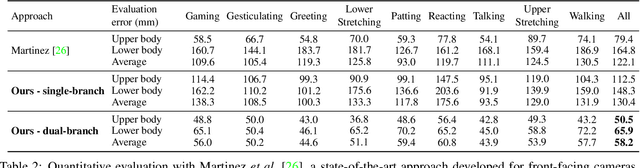

We present a new solution to egocentric 3D body pose estimation from monocular images captured from a downward looking fish-eye camera installed on the rim of a head mounted virtual reality device. This unusual viewpoint, just 2 cm. away from the user's face, leads to images with unique visual appearance, characterized by severe self-occlusions and strong perspective distortions that result in a drastic difference in resolution between lower and upper body. Our contribution is two-fold. Firstly, we propose a new encoder-decoder architecture with a novel dual branch decoder designed specifically to account for the varying uncertainty in the 2D joint locations. Our quantitative evaluation, both on synthetic and real-world datasets, shows that our strategy leads to substantial improvements in accuracy over state of the art egocentric pose estimation approaches. Our second contribution is a new large-scale photorealistic synthetic dataset - xR-EgoPose - offering 383K frames of high quality renderings of people with a diversity of skin tones, body shapes, clothing, in a variety of backgrounds and lighting conditions, performing a range of actions. Our experiments show that the high variability in our new synthetic training corpus leads to good generalization to real world footage and to state of the art results on real world datasets with ground truth. Moreover, an evaluation on the Human3.6M benchmark shows that the performance of our method is on par with top performing approaches on the more classic problem of 3D human pose from a third person viewpoint.
Rethinking Pose in 3D: Multi-stage Refinement and Recovery for Markerless Motion Capture
Aug 04, 2018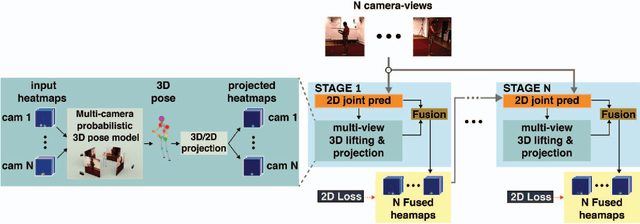
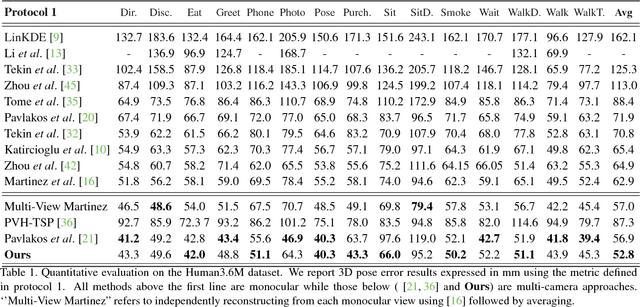
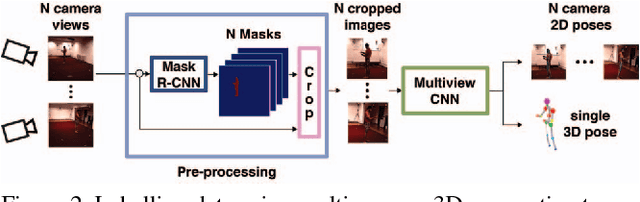

We propose a CNN-based approach for multi-camera markerless motion capture of the human body. Unlike existing methods that first perform pose estimation on individual cameras and generate 3D models as post-processing, our approach makes use of 3D reasoning throughout a multi-stage approach. This novelty allows us to use provisional 3D models of human pose to rethink where the joints should be located in the image and to recover from past mistakes. Our principled refinement of 3D human poses lets us make use of image cues, even from images where we previously misdetected joints, to refine our estimates as part of an end-to-end approach. Finally, we demonstrate how the high-quality output of our multi-camera setup can be used as an additional training source to improve the accuracy of existing single camera models.
Lifting from the Deep: Convolutional 3D Pose Estimation from a Single Image
Oct 11, 2017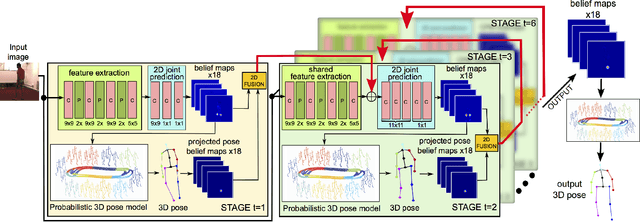
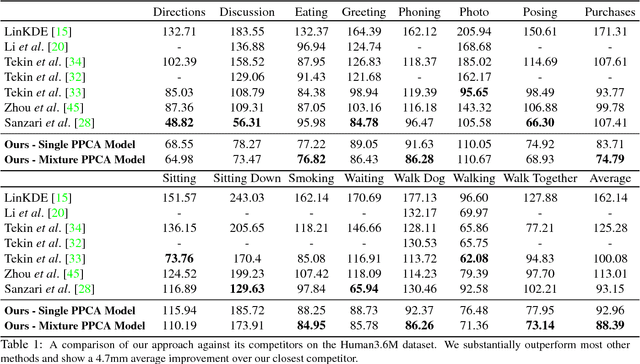
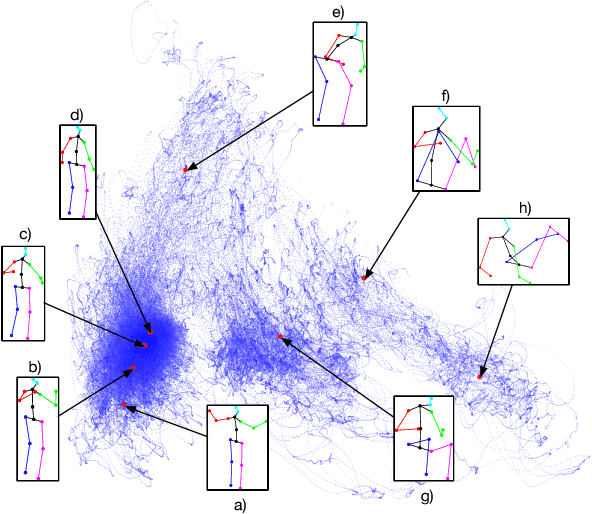
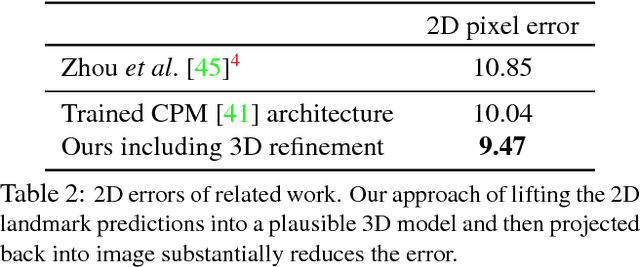
We propose a unified formulation for the problem of 3D human pose estimation from a single raw RGB image that reasons jointly about 2D joint estimation and 3D pose reconstruction to improve both tasks. We take an integrated approach that fuses probabilistic knowledge of 3D human pose with a multi-stage CNN architecture and uses the knowledge of plausible 3D landmark locations to refine the search for better 2D locations. The entire process is trained end-to-end, is extremely efficient and obtains state- of-the-art results on Human3.6M outperforming previous approaches both on 2D and 3D errors.