 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Deep Neural Networks to Detect Repeatable 2D Features Using Large Amounts of 3D World Capture Data
Dec 09, 2019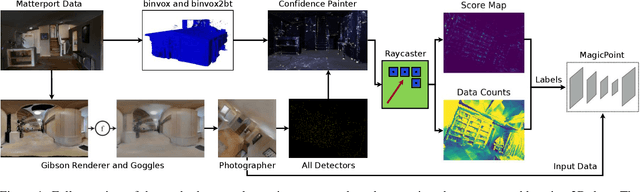



Image space feature detection is the act of selecting points or parts of an image that are easy to distinguish from the surrounding image region. By combining a repeatable point detection with a descriptor, parts of an image can be matched with one another, which is useful in applications like estimating pose from camera input or rectifying images. Recently, precise indoor tracking has started to become important for Augmented and Virtual reality as it is necessary to allow positioning of a headset in 3D space without the need for external tracking devices. Several modern feature detectors use homographies to simulate different viewpoints, not only to train feature detection and description, but test them as well. The problem is that, often, views of indoor spaces contain high depth disparity. This makes the approximation that a homography applied to an image represents a viewpoint change inaccurate. We claim that in order to train detectors to work well in indoor environments, they must be robust to this type of geometry, and repeatable under true viewpoint change instead of homographies. Here we focus on the problem of detecting repeatable feature locations under true viewpoint change. To this end, we generate labeled 2D images from a photo-realistic 3D dataset. These images are used for training a neural network based feature detector. We further present an algorithm for automatically generating labels of repeatable 2D features, and present a fast, easy to use test algorithm for evaluating a detector in an 3D environment.
Improving Usability, Efficiency, and Safety of UAV Path Planning through a Virtual Reality Interface
Apr 18, 2019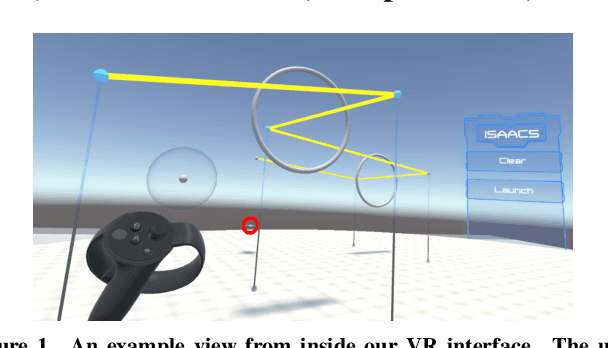
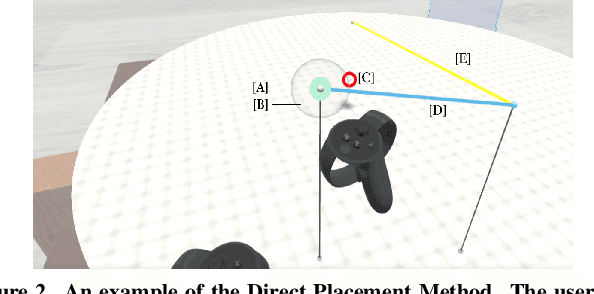
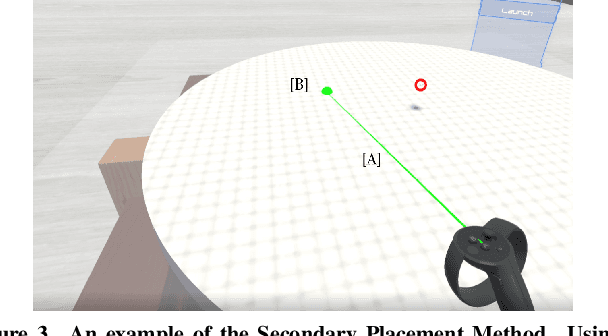
As the capability and complexity of UAVs continue to increase, the human-robot interface community has a responsibility to design better ways of specifying the complex 3D flight paths necessary for instructing them. Immersive interfaces, such as those afforded by virtual reality (VR), have several unique traits which may improve the user's ability to perceive and specify 3D information. These traits include stereoscopic depth cues which induce a sense of physical space as well as six degrees of freedom (DoF) natural head-pose and gesture interactions. This work introduces an open-source platform for 3D aerial path planning in VR and compares it to existing UAV piloting interfaces. Our study has found statistically significant improvements in safety and subjective usability over a manual control interface, while achieving a statistically significant efficiency improvement over a 2D touchscreen interface. The results illustrate that immersive interfaces provide a viable alternative to touchscreen interfaces for UAV path planning.
Loop Closure Detection with RGB-D Feature Pyramid Siamese Networks
Nov 25, 2018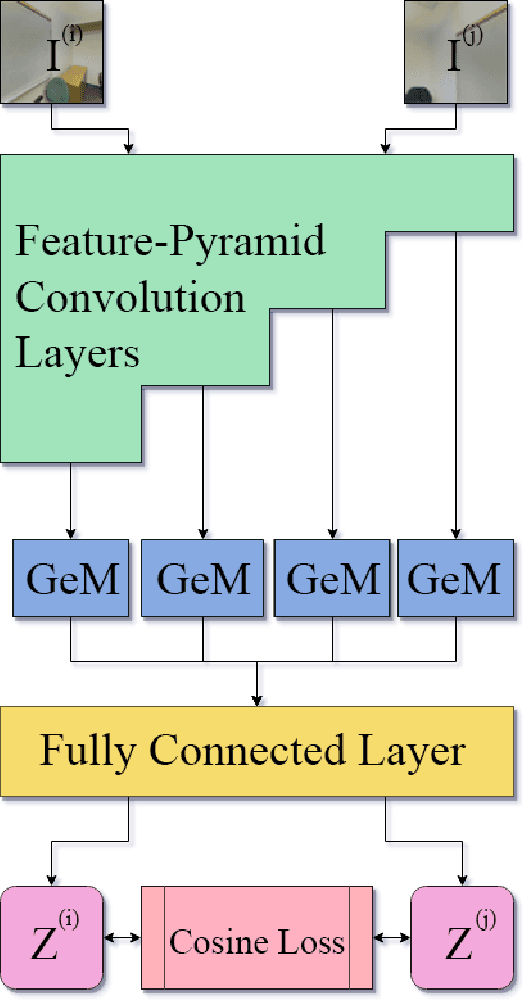



In visual Simultaneous Localization And Mapping (SLAM), detecting loop closures has been an important but difficult task. Currently, most solutions are based on the bag-of-words approach. Yet the possibility of deep neural network application to this task has not been fully explored due to the lack of appropriate architecture design and of sufficient training data. In this paper we demonstrate the applicability of deep neural networks by addressing both issues. Specifically we show that a feature pyramid Siamese neural network can achieve state-of-the-art performance on pairwise loop closure detection. The network is trained and tested on large-scale RGB-D datasets with a novel automatic loop closure labeling algorithm. Each image pair is labelled by how much the images overlap, allowing loop closure to be computed directly rather than by labor intensive manual labeling. We present an algorithm to adopt any large-scale generic RGB-D dataset for use in training deep loop-closure networks. We show for the first time that deep neural networks are capable of detecting loop closures, and we provide a method for generating large-scale datasets for use in evaluating and training loop closure detectors.
Modeling Supervisor Safe Sets for Improving Collaboration in Human-Robot Teams
May 09, 2018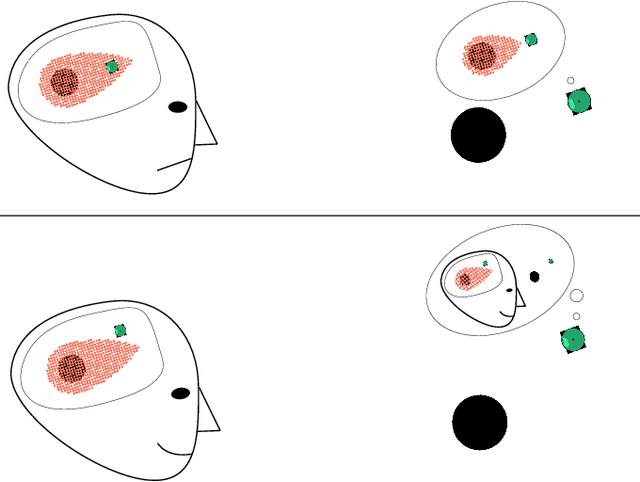
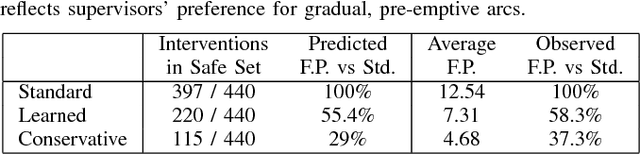
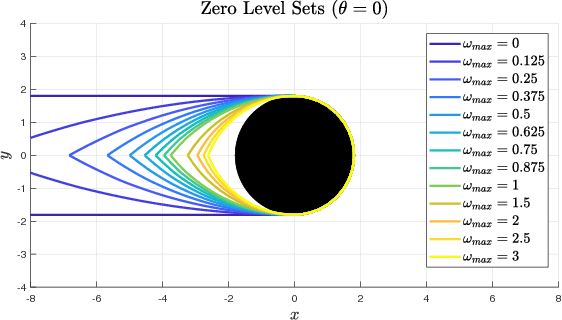
When a human supervisor collaborates with a team of robots, their attention is divided and cognitive resources are at a premium. We aim to optimize the distribution of these resources and the flow of attention. To this end, we propose the model of an idealized supervisor to describe human behavior. Such a supervisor employs a potentially inaccurate internal model of the the robots' dynamics to judge safety. We represent these safety judgements by constructing a safe set from this internal model using reachability theory. When a robot leaves this safe set, the idealized supervisor will intervene to assist, regardless of whether or not the robot remains objectively safe. False positives, where a human supervisor incorrectly judges a robot to be in danger, needlessly consume supervisor attention. In this work, we propose a method that decreases false positives by learning the supervisor's safe set and using that information to govern robot behavior. We prove that robots behaving according to our approach will reduce the occurrence of false positives for our idealized supervisor model. Furthermore, we empirically validate our approach with a user study that demonstrates a significant ($p = 0.0328$) reduction in false positives for our method compared to a baseline safety controller.