 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRC-RL: A Novel Visual Feature Representation Architecture for Unsupervised Reinforcement Learning
Jan 31, 2023This paper addresses the problem of visual feature representation learning with an aim to improve the performance of end-to-end reinforcement learning (RL) models. Specifically, a novel architecture is proposed that uses a heterogeneous loss function, called CRC loss, to learn improved visual features which can then be used for policy learning in RL. The CRC-loss function is a combination of three individual loss functions, namely, contrastive, reconstruction and consistency loss. The feature representation is learned in parallel to the policy learning while sharing the weight updates through a Siamese Twin encoder model. This encoder model is augmented with a decoder network and a feature projection network to facilitate computation of the above loss components. Through empirical analysis involving latent feature visualization, an attempt is made to provide an insight into the role played by this loss function in learning new action-dependent features and how they are linked to the complexity of the problems being solved. The proposed architecture, called CRC-RL, is shown to outperform the existing state-of-the-art methods on the challenging Deep mind control suite environments by a significant margin thereby creating a new benchmark in this field.
Error Correction in ASR using Sequence-to-Sequence Models
Feb 02, 2022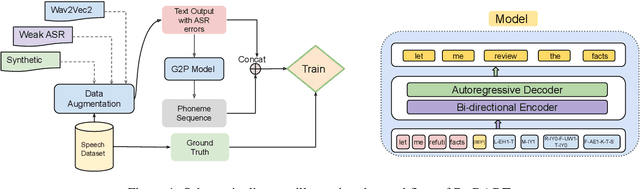
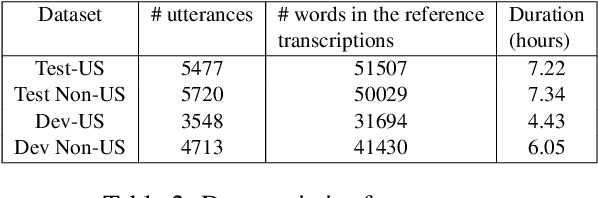


Post-editing in Automatic Speech Recognition (ASR) entails automatically correcting common and systematic errors produced by the ASR system. The outputs of an ASR system are largely prone to phonetic and spelling errors. In this paper, we propose to use a powerful pre-trained sequence-to-sequence model, BART, further adaptively trained to serve as a denoising model, to correct errors of such types. The adaptive training is performed on an augmented dataset obtained by synthetically inducing errors as well as by incorporating actual errors from an existing ASR system. We also propose a simple approach to rescore the outputs using word level alignments. Experimental results on accented speech data demonstrate that our strategy effectively rectifies a significant number of ASR errors and produces improved WER results when compared against a competitive baseline.
A Method for Handling Multi-class Imbalanced Data by Geometry based Information Sampling and Class Prioritized Synthetic Data Generation
Oct 11, 2020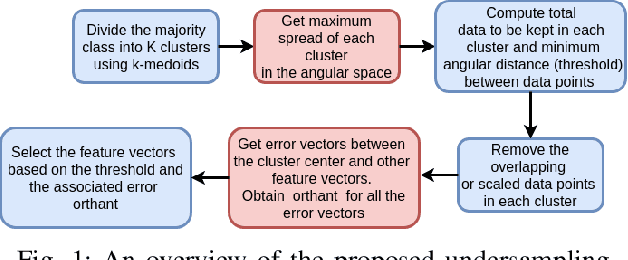
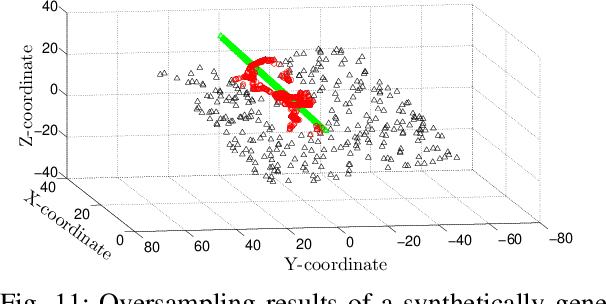
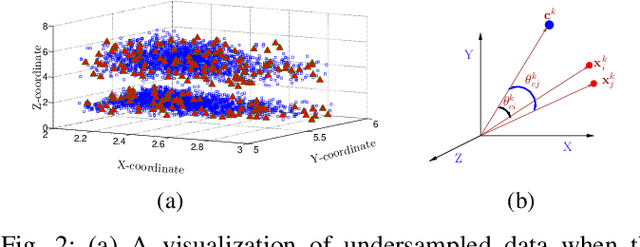
This paper looks into the problem of handling imbalanced data in a multi-label classification problem. The problem is solved by proposing two novel methods that primarily exploit the geometric relationship between the feature vectors. The first one is an undersampling algorithm that uses angle between feature vectors to select more informative samples while rejecting the less informative ones. A suitable criterion is proposed to define the informativeness of a given sample. The second one is an oversampling algorithm that uses a generative algorithm to create new synthetic data that respects all class boundaries. This is achieved by finding \emph{no man's land} based on Euclidean distance between the feature vectors. The efficacy of the proposed methods is analyzed by solving a generic multi-class recognition problem based on mixture of Gaussians. The superiority of the proposed algorithms is established through comparison with other state-of-the-art methods, including SMOTE and ADASYN, over ten different publicly available datasets exhibiting high-to-extreme data imbalance. These two methods are combined into a single data processing framework and is labeled as ``GICaPS'' to highlight the role of geometry-based information (GI) sampling and Class-Prioritized Synthesis (CaPS) in dealing with multi-class data imbalance problem, thereby making a novel contribution in this field.
Design and Development of an automated Robotic Pick & Stow System for an e-Commerce Warehouse
Mar 07, 2017
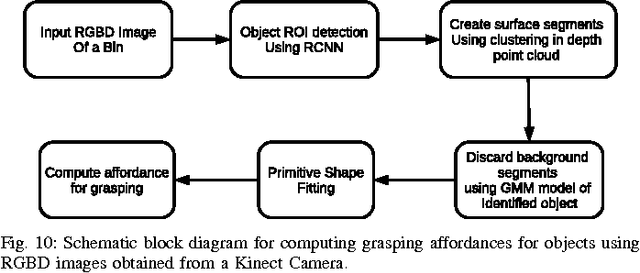
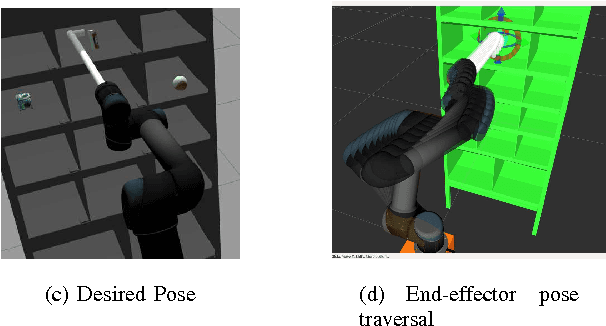
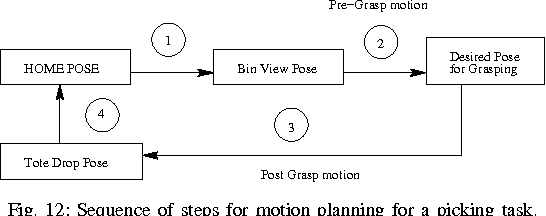
In this paper, we provide details of a robotic system that can automate the task of picking and stowing objects from and to a rack in an e-commerce fulfillment warehouse. The system primarily comprises of four main modules: (1) Perception module responsible for recognizing query objects and localizing them in the 3-dimensional robot workspace; (2) Planning module generates necessary paths that the robot end- effector has to take for reaching the objects in the rack or in the tote; (3) Calibration module that defines the physical workspace for the robot visible through the on-board vision system; and (4) Gripping and suction system for picking and stowing different kinds of objects. The perception module uses a faster region-based Convolutional Neural Network (R-CNN) to recognize objects. We designed a novel two finger gripper that incorporates pneumatic valve based suction effect to enhance its ability to pick different kinds of objects. The system was developed by IITK-TCS team for participation in the Amazon Picking Challenge 2016 event. The team secured a fifth place in the stowing task in the event. The purpose of this article is to share our experiences with students and practicing engineers and enable them to build similar systems. The overall efficacy of the system is demonstrated through several simulation as well as real-world experiments with actual robots.