 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSASMU: boost the performance of generalized recognition model using synthetic face dataset
Jun 02, 2023


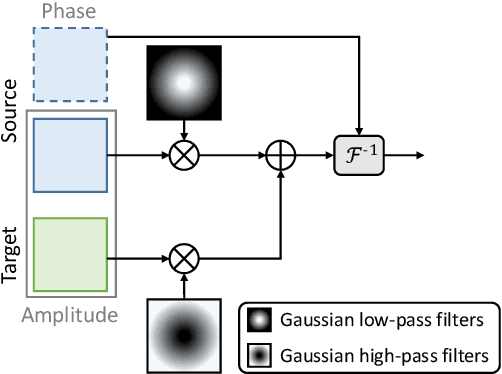
Nowadays, deploying a robust face recognition product becomes easy with the development of face recognition techniques for decades. Not only profile image verification but also the state-of-the-art method can handle the in-the-wild image almost perfectly. However, the concern of privacy issues raise rapidly since mainstream research results are powered by tons of web-crawled data, which faces the privacy invasion issue. The community tries to escape this predicament completely by training the face recognition model with synthetic data but faces severe domain gap issues, which still need to access real images and identity labels to fine-tune the model. In this paper, we propose SASMU, a simple, novel, and effective method for face recognition using a synthetic dataset. Our proposed method consists of spatial data augmentation (SA) and spectrum mixup (SMU). We first analyze the existing synthetic datasets for developing a face recognition system. Then, we reveal that heavy data augmentation is helpful for boosting performance when using synthetic data. By analyzing the previous frequency mixup studies, we proposed a novel method for domain generalization. Extensive experimental results have demonstrated the effectiveness of SASMU, achieving state-of-the-art performance on several common benchmarks, such as LFW, AgeDB-30, CA-LFW, CFP-FP, and CP-LFW.
Facial Image Reconstruction from Functional Magnetic Resonance Imaging via GAN Inversion with Improved Attribute Consistency
Jul 03, 2022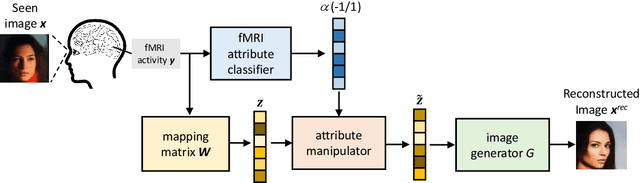


Neuroscience studies have revealed that the brain encodes visual content and embeds information in neural activity. Recently, deep learning techniques have facilitated attempts to address visual reconstructions by mapping brain activity to image stimuli using generative adversarial networks (GANs). However, none of these studies have considered the semantic meaning of latent code in image space. Omitting semantic information could potentially limit the performance. In this study, we propose a new framework to reconstruct facial images from functional Magnetic Resonance Imaging (fMRI) data. With this framework, the GAN inversion is first applied to train an image encoder to extract latent codes in image space, which are then bridged to fMRI data using linear transformation. Following the attributes identified from fMRI data using an attribute classifier, the direction in which to manipulate attributes is decided and the attribute manipulator adjusts the latent code to improve the consistency between the seen image and the reconstructed image. Our experimental results suggest that the proposed framework accomplishes two goals: (1) reconstructing clear facial images from fMRI data and (2) maintaining the consistency of semantic characteristics.
Self-Supervised Robustifying Guidance for Monocular 3D Face Reconstruction
Dec 29, 2021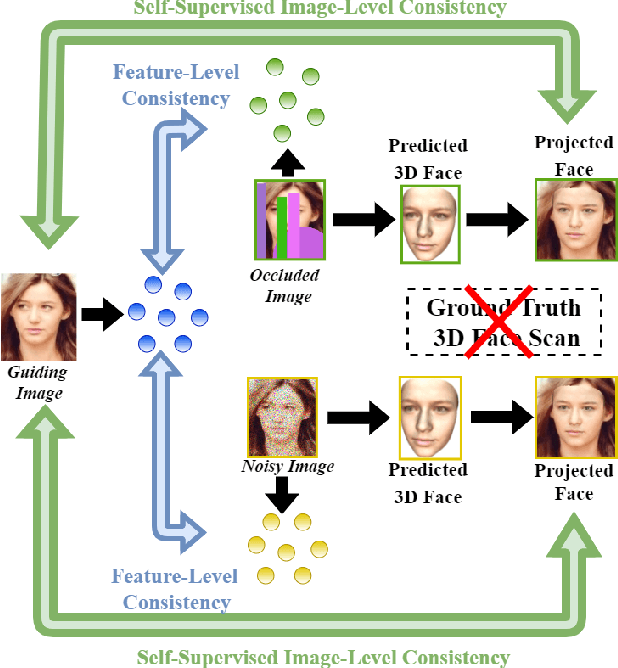
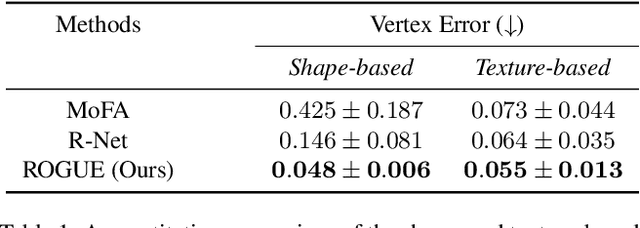
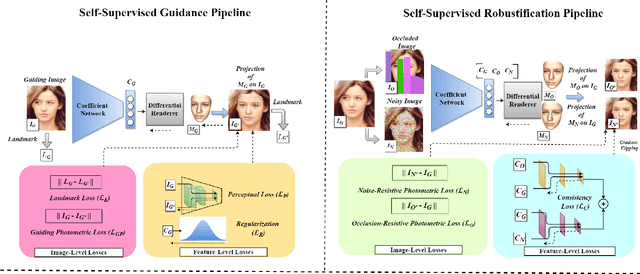
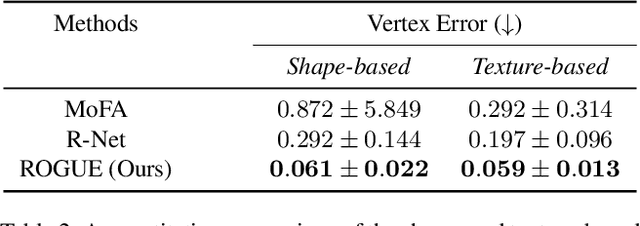
Despite the recent developments in 3D Face Reconstruction from occluded and noisy face images, the performance is still unsatisfactory. One of the main challenges is to handle moderate to heavy occlusions in the face images. In addition, the noise in the face images inhibits the correct capture of facial attributes, thus needing to be reliably addressed. Moreover, most existing methods rely on additional dependencies, posing numerous constraints over the training procedure. Therefore, we propose a Self-Supervised RObustifying GUidancE (ROGUE) framework to obtain robustness against occlusions and noise in the face images. The proposed network contains 1) the Guidance Pipeline to obtain the 3D face coefficients for the clean faces, and 2) the Robustification Pipeline to acquire the consistency between the estimated coefficients for occluded or noisy images and the clean counterpart. The proposed image- and feature-level loss functions aid the ROGUE learning process without posing additional dependencies. On the three variations of the test dataset of CelebA: rational occlusions, delusional occlusions, and noisy face images, our method outperforms the current state-of-the-art method by large margins (e.g., for the shape-based 3D vertex errors, a reduction from 0.146 to 0.048 for rational occlusions, from 0.292 to 0.061 for delusional occlusions and from 0.269 to 0.053 for the noise in the face images), demonstrating the effectiveness of the proposed approach.
MS-SincResNet: Joint learning of 1D and 2D kernels using multi-scale SincNet and ResNet for music genre classification
Sep 18, 2021
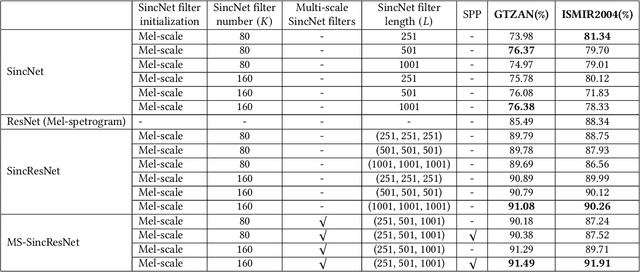
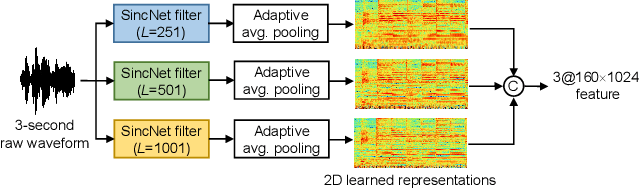
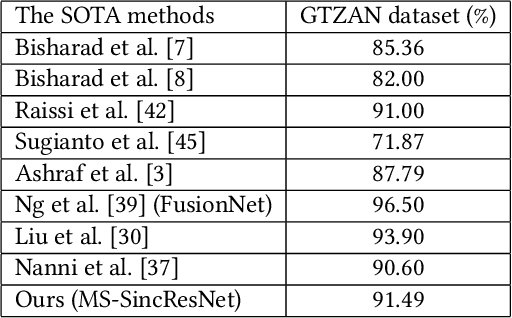
In this study, we proposed a new end-to-end convolutional neural network, called MS-SincResNet, for music genre classification. MS-SincResNet appends 1D multi-scale SincNet (MS-SincNet) to 2D ResNet as the first convolutional layer in an attempt to jointly learn 1D kernels and 2D kernels during the training stage. First, an input music signal is divided into a number of fixed-duration (3 seconds in this study) music clips, and the raw waveform of each music clip is fed into 1D MS-SincNet filter learning module to obtain three-channel 2D representations. The learned representations carry rich timbral, harmonic, and percussive characteristics comparing with spectrograms, harmonic spectrograms, percussive spectrograms and Mel-spectrograms. ResNet is then used to extract discriminative embeddings from these 2D representations. The spatial pyramid pooling (SPP) module is further used to enhance the feature discriminability, in terms of both time and frequency aspects, to obtain the classification label of each music clip. Finally, the voting strategy is applied to summarize the classification results from all 3-second music clips. In our experimental results, we demonstrate that the proposed MS-SincResNet outperforms the baseline SincNet and many well-known hand-crafted features. Considering individual 2D representation, MS-SincResNet also yields competitive results with the state-of-the-art methods on the GTZAN dataset and the ISMIR2004 dataset. The code is available at https://github.com/PeiChunChang/MS-SincResNet
Learning Facial Representations from the Cycle-consistency of Face
Aug 07, 2021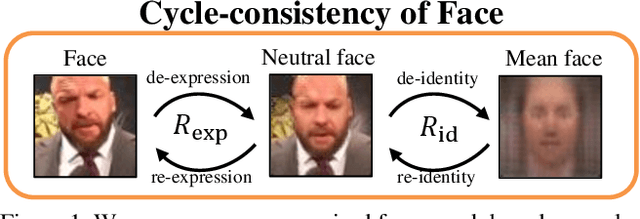
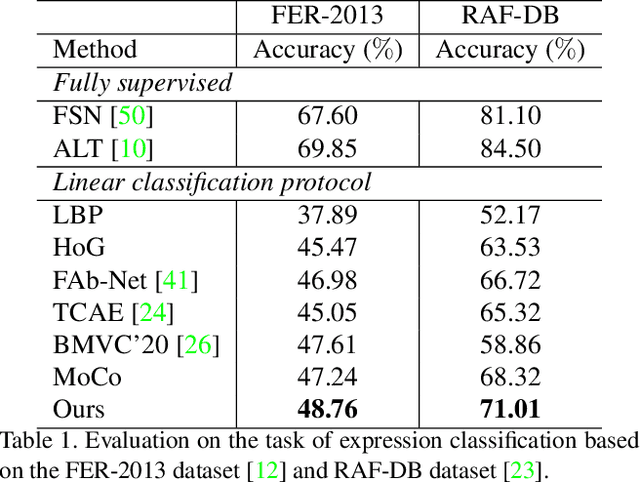
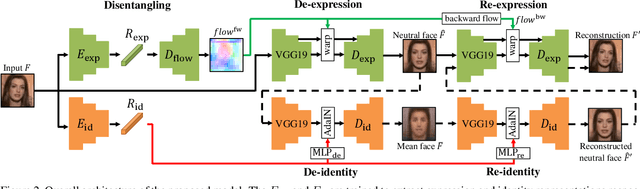
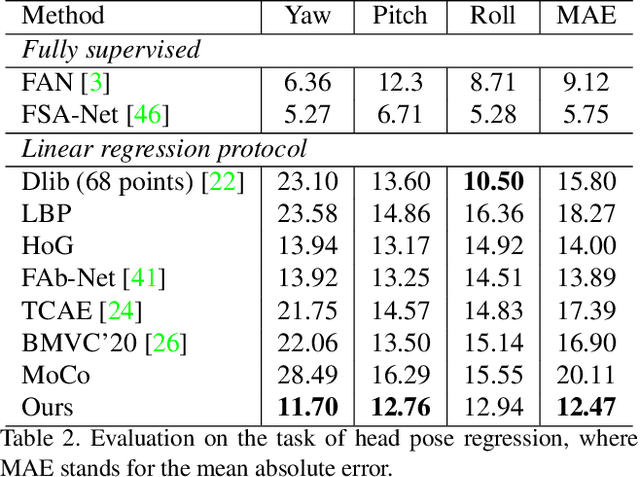
Faces manifest large variations in many aspects, such as identity, expression, pose, and face styling. Therefore, it is a great challenge to disentangle and extract these characteristics from facial images, especially in an unsupervised manner. In this work, we introduce cycle-consistency in facial characteristics as free supervisory signal to learn facial representations from unlabeled facial images. The learning is realized by superimposing the facial motion cycle-consistency and identity cycle-consistency constraints. The main idea of the facial motion cycle-consistency is that, given a face with expression, we can perform de-expression to a neutral face via the removal of facial motion and further perform re-expression to reconstruct back to the original face. The main idea of the identity cycle-consistency is to exploit both de-identity into mean face by depriving the given neutral face of its identity via feature re-normalization and re-identity into neutral face by adding the personal attributes to the mean face. At training time, our model learns to disentangle two distinct facial representations to be useful for performing cycle-consistent face reconstruction. At test time, we use the linear protocol scheme for evaluating facial representations on various tasks, including facial expression recognition and head pose regression. We also can directly apply the learnt facial representations to person recognition, frontalization and image-to-image translation. Our experiments show that the results of our approach is competitive with those of existing methods, demonstrating the rich and unique information embedded in the disentangled representations. Code is available at https://github.com/JiaRenChang/FaceCycle .
Parallel Residual Bi-Fusion Feature Pyramid Network for Accurate Single-Shot Object Detection
Dec 03, 2020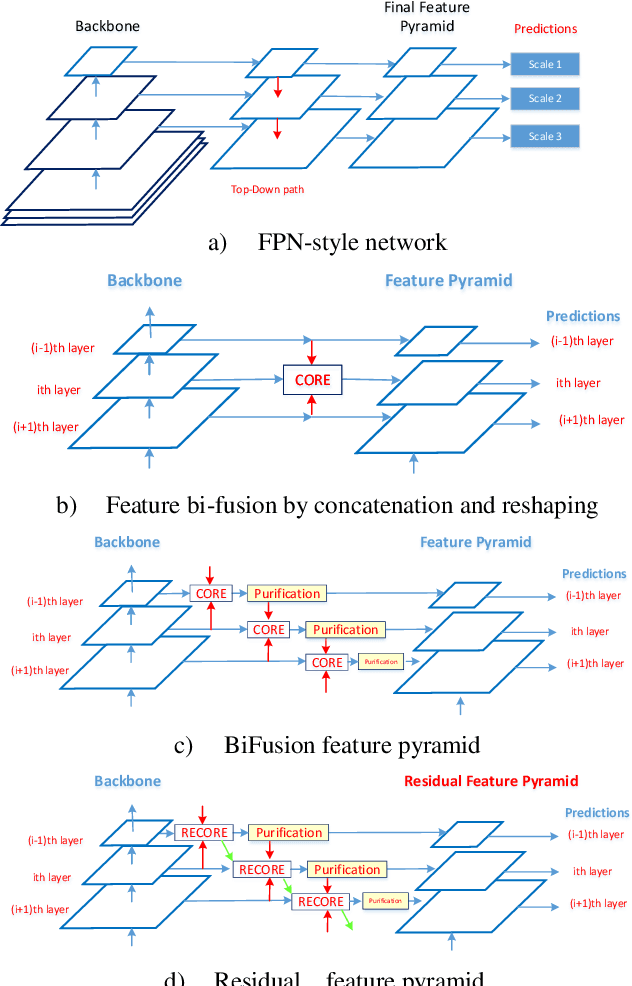
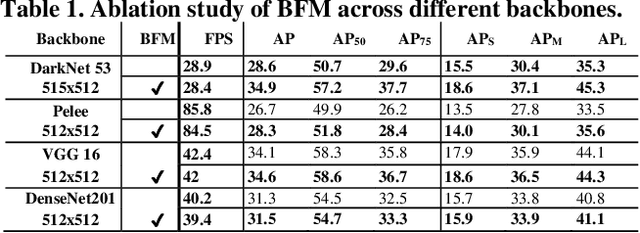

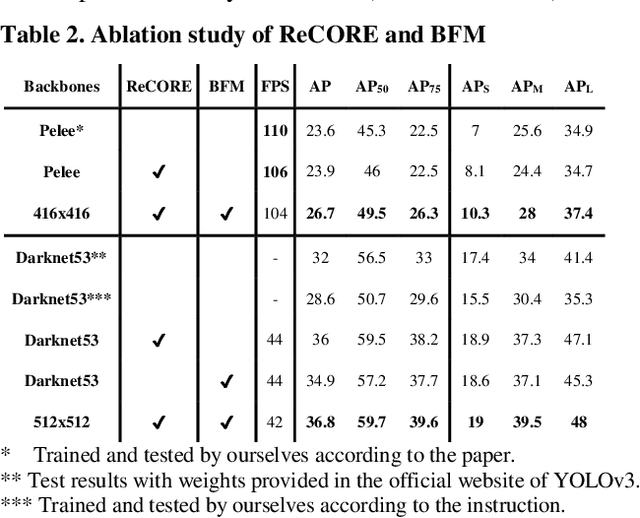
We propose the Parallel Residual Bi-Fusion Feature Pyramid Network (PRB-FPN) for fast and accurate single-shot object detection. Feature Pyramid (FP) is widely used in recent visual detection, however the top-down pathway of FP cannot preserve accurate localization due to pooling shifting. The advantage of FP is weaken as deeper backbones with more layers are used. To address this issue, we propose a new parallel FP structure with bi-directional (top-down and bottom-up) fusion and associated improvements to retain high-quality features for accurate localization. Our method is particularly suitable for detecting small objects. We provide the following design improvements: (1) A parallel bifusion FP structure with a Bottom-up Fusion Module (BFM) to detect both small and large objects at once with high accuracy. (2) A COncatenation and RE-organization (CORE) module provides a bottom-up pathway for feature fusion, which leads to the bi-directional fusion FP that can recover lost information from lower-layer feature maps. (3) The CORE feature is further purified to retain richer contextual information. Such purification is performed with CORE in a few iterations in both top-down and bottom-up pathways. (4) The adding of a residual design to CORE leads to a new Re-CORE module that enables easy training and integration with a wide range of (deeper or lighter) backbones. The proposed network achieves state-of-the-art performance on UAVDT17 and MS COCO datasets.
Pyramid Stereo Matching Network
Mar 23, 2018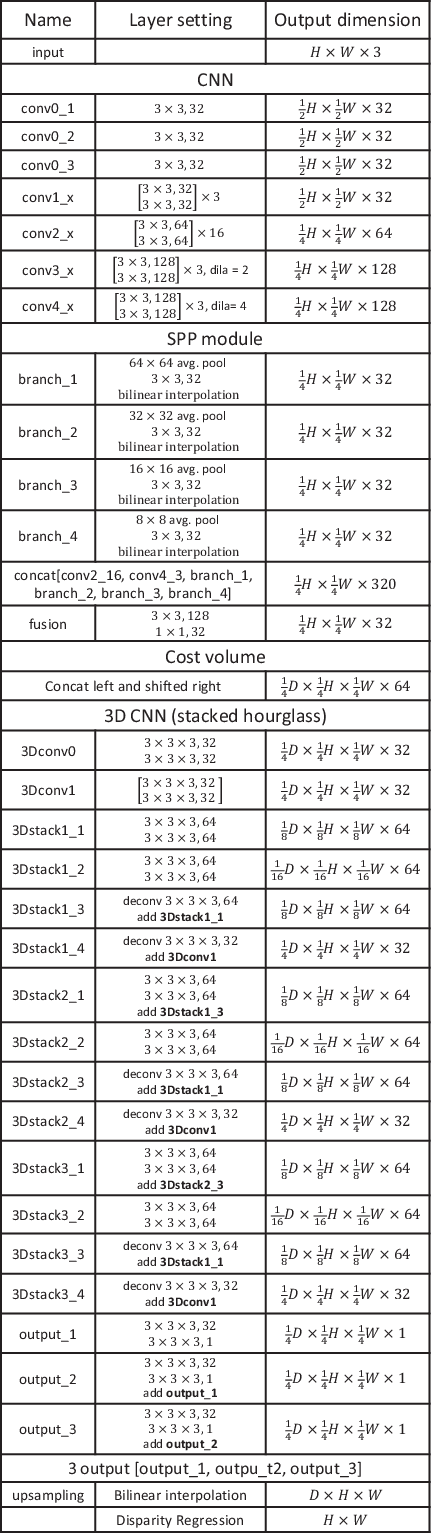
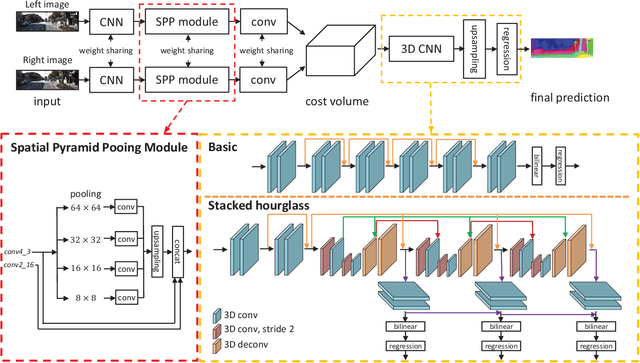
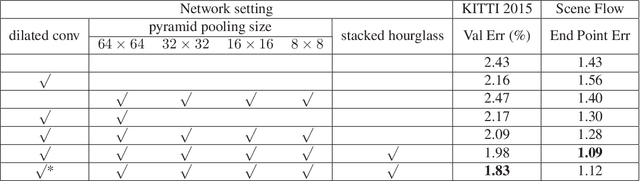
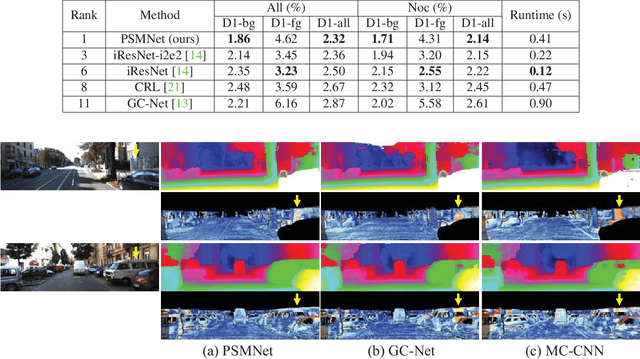
Recent work has shown that depth estimation from a stereo pair of images can be formulated as a supervised learning task to be resolved with convolutional neural networks (CNNs). However, current architectures rely on patch-based Siamese networks, lacking the means to exploit context information for finding correspondence in illposed regions. To tackle this problem, we propose PSMNet, a pyramid stereo matching network consisting of two main modules: spatial pyramid pooling and 3D CNN. The spatial pyramid pooling module takes advantage of the capacity of global context information by aggregating context in different scales and locations to form a cost volume. The 3D CNN learns to regularize cost volume using stacked multiple hourglass networks in conjunction with intermediate supervision. The proposed approach was evaluated on several benchmark datasets. Our method ranked first in the KITTI 2012 and 2015 leaderboards before March 18, 2018. The codes of PSMNet are available at: https://github.com/JiaRenChang/PSMNet.
Deep Competitive Pathway Networks
Sep 29, 2017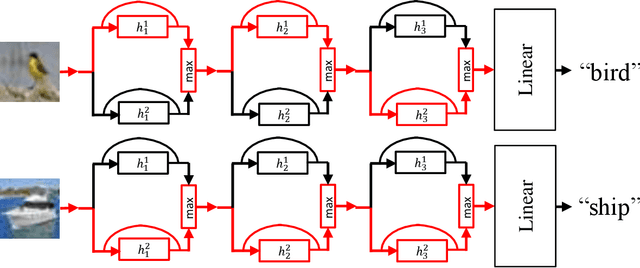
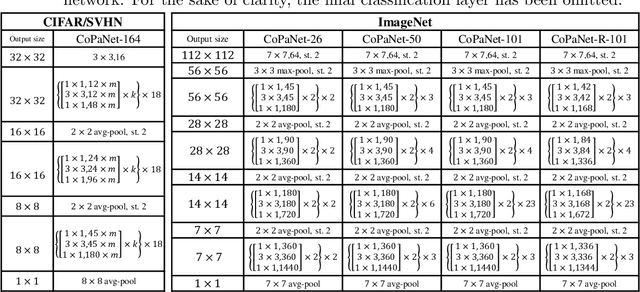
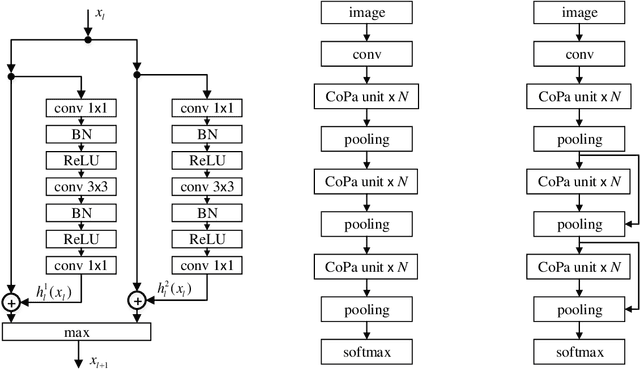
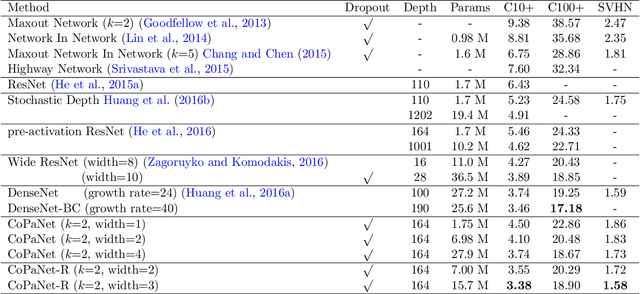
In the design of deep neural architectures, recent studies have demonstrated the benefits of grouping subnetworks into a larger network. For examples, the Inception architecture integrates multi-scale subnetworks and the residual network can be regarded that a residual unit combines a residual subnetwork with an identity shortcut. In this work, we embrace this observation and propose the Competitive Pathway Network (CoPaNet). The CoPaNet comprises a stack of competitive pathway units and each unit contains multiple parallel residual-type subnetworks followed by a max operation for feature competition. This mechanism enhances the model capability by learning a variety of features in subnetworks. The proposed strategy explicitly shows that the features propagate through pathways in various routing patterns, which is referred to as pathway encoding of category information. Moreover, the cross-block shortcut can be added to the CoPaNet to encourage feature reuse. We evaluated the proposed CoPaNet on four object recognition benchmarks: CIFAR-10, CIFAR-100, SVHN, and ImageNet. CoPaNet obtained the state-of-the-art or comparable results using similar amounts of parameters. The code of CoPaNet is available at: https://github.com/JiaRenChang/CoPaNet.
Batch-normalized Maxout Network in Network
Nov 09, 2015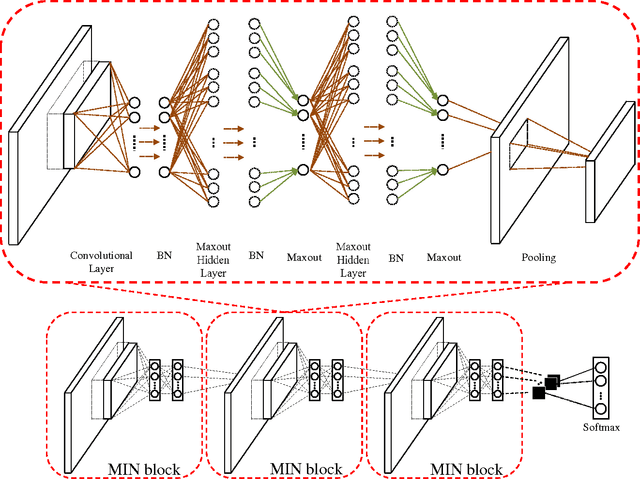
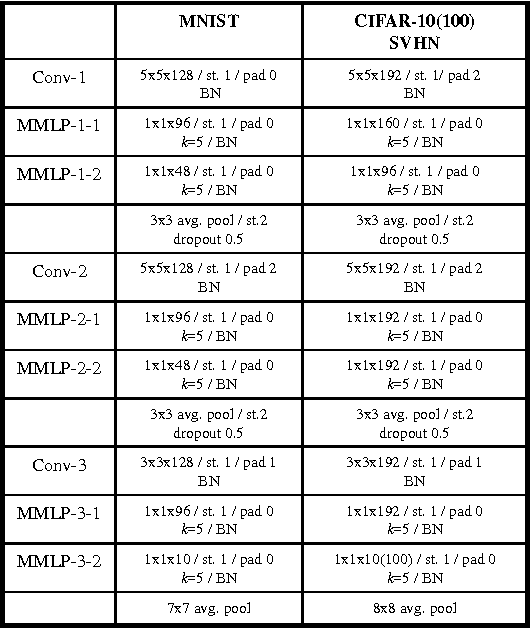

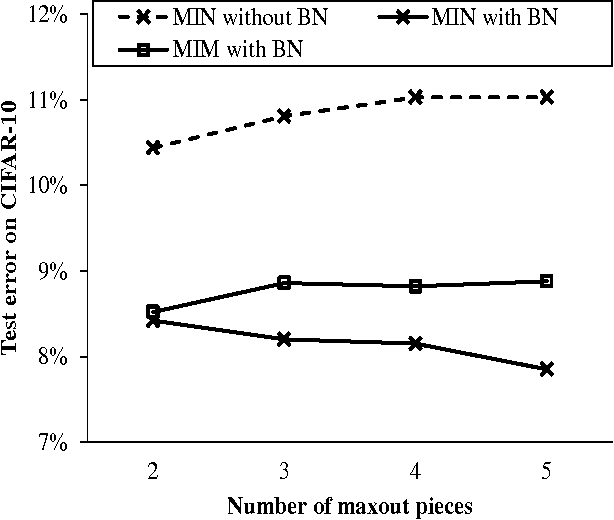
This paper reports a novel deep architecture referred to as Maxout network In Network (MIN), which can enhance model discriminability and facilitate the process of information abstraction within the receptive field. The proposed network adopts the framework of the recently developed Network In Network structure, which slides a universal approximator, multilayer perceptron (MLP) with rectifier units, to exact features. Instead of MLP, we employ maxout MLP to learn a variety of piecewise linear activation functions and to mediate the problem of vanishing gradients that can occur when using rectifier units. Moreover, batch normalization is applied to reduce the saturation of maxout units by pre-conditioning the model and dropout is applied to prevent overfitting. Finally, average pooling is used in all pooling layers to regularize maxout MLP in order to facilitate information abstraction in every receptive field while tolerating the change of object position. Because average pooling preserves all features in the local patch, the proposed MIN model can enforce the suppression of irrelevant information during training. Our experiments demonstrated the state-of-the-art classification performance when the MIN model was applied to MNIST, CIFAR-10, and CIFAR-100 datasets and comparable performance for SVHN dataset.