 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Image Reconstruction from Functional Magnetic Resonance Imaging via GAN Inversion with Improved Attribute Consistency
Jul 03, 2022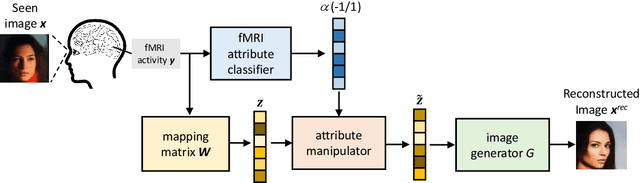

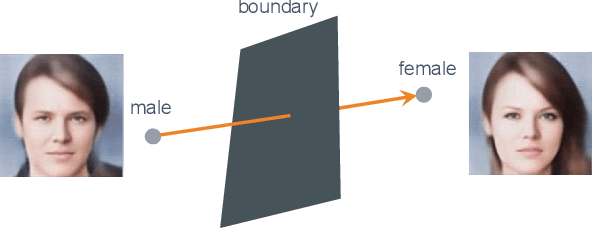

Neuroscience studies have revealed that the brain encodes visual content and embeds information in neural activity. Recently, deep learning techniques have facilitated attempts to address visual reconstructions by mapping brain activity to image stimuli using generative adversarial networks (GANs). However, none of these studies have considered the semantic meaning of latent code in image space. Omitting semantic information could potentially limit the performance. In this study, we propose a new framework to reconstruct facial images from functional Magnetic Resonance Imaging (fMRI) data. With this framework, the GAN inversion is first applied to train an image encoder to extract latent codes in image space, which are then bridged to fMRI data using linear transformation. Following the attributes identified from fMRI data using an attribute classifier, the direction in which to manipulate attributes is decided and the attribute manipulator adjusts the latent code to improve the consistency between the seen image and the reconstructed image. Our experimental results suggest that the proposed framework accomplishes two goals: (1) reconstructing clear facial images from fMRI data and (2) maintaining the consistency of semantic characteristics.
Approach to Predicting News -- A Precise Multi-LSTM Network With BERT
Apr 26, 2022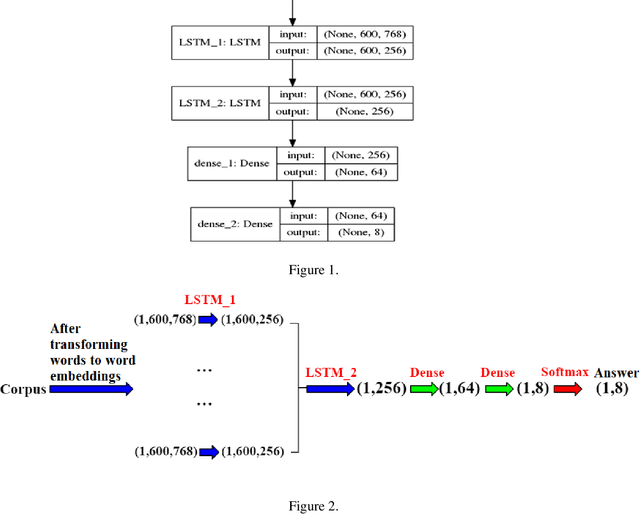
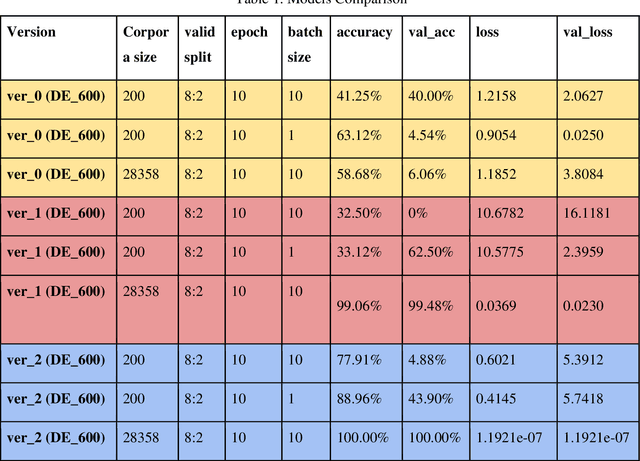
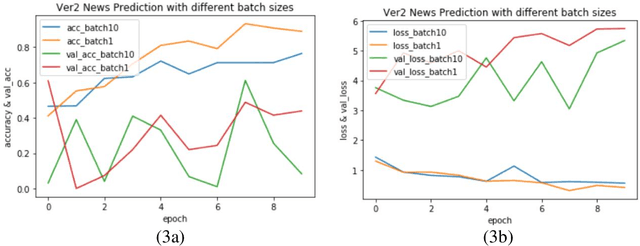
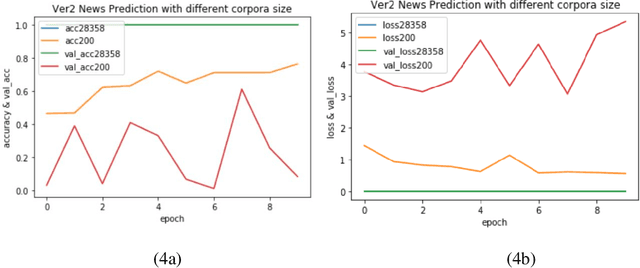
Varieties of Democracy (V-Dem) is a new approach to conceptualizing and measuring democracy and politics. It has information for 200 countries and is one of the biggest databases for political science. According to the V-Dem annual democracy report 2019, Taiwan is one of the two countries that got disseminated false information from foreign governments the most. It also shows that the "made-up news" has caused a great deal of confusion in Taiwanese society and has serious impacts on global stability. Although there are several applications helping distinguish the false information, we found out that the pre-processing of categorizing the news is still done by human labor. However, human labor may cause mistakes and cannot work for a long time. The growing demands for automatic machines in the near decades show that while the machine can do as good as humans or even better, using machines can reduce humans' burden and cut down costs. Therefore, in this work, we build a predictive model to classify the category of news. The corpora we used contains 28358 news and 200 news scraped from the online newspaper Liberty Times Net (LTN) website and includes 8 categories: Technology, Entertainment, Fashion, Politics, Sports, International, Finance, and Health. At first, we use Bidirectional Encoder Representations from Transformers (BERT) for word embeddings which transform each Chinese character into a (1,768) vector. Then, we use a Long Short-Term Memory (LSTM) layer to transform word embeddings into sentence embeddings and add another LSTM layer to transform them into document embeddings. Each document embedding is an input for the final predicting model, which contains two Dense layers and one Activation layer. And each document embedding is transformed into 1 vector with 8 real numbers, then the highest one will correspond to the 8 news categories with up to 99% accuracy.
* Accepted by The 25th International Conference on Information Management & Practice (IMP) 2019