 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepetitionCurse: Measuring and Understanding Router Imbalance in Mixture-of-Experts LLMs under DoS Stress
Dec 30, 2025Mixture-of-Experts architectures have become the standard for scaling large language models due to their superior parameter efficiency. To accommodate the growing number of experts in practice, modern inference systems commonly adopt expert parallelism to distribute experts across devices. However, the absence of explicit load balancing constraints during inference allows adversarial inputs to trigger severe routing concentration. We demonstrate that out-of-distribution prompts can manipulate the routing strategy such that all tokens are consistently routed to the same set of top-$k$ experts, which creates computational bottlenecks on certain devices while forcing others to idle. This converts an efficiency mechanism into a denial-of-service attack vector, leading to violations of service-level agreements for time to first token. We propose RepetitionCurse, a low-cost black-box strategy to exploit this vulnerability. By identifying a universal flaw in MoE router behavior, RepetitionCurse constructs adversarial prompts using simple repetitive token patterns in a model-agnostic manner. On widely deployed MoE models like Mixtral-8x7B, our method increases end-to-end inference latency by 3.063x, degrading service availability significantly.
APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models
Feb 21, 2024Large Language Models (LLMs) have greatly advanced the natural language processing paradigm. However, the high computational load and huge model sizes pose a grand challenge for deployment on edge devices. To this end, we propose APTQ (Attention-aware Post-Training Mixed-Precision Quantization) for LLMs, which considers not only the second-order information of each layer's weights, but also, for the first time, the nonlinear effect of attention outputs on the entire model. We leverage the Hessian trace as a sensitivity metric for mixed-precision quantization, ensuring an informed precision reduction that retains model performance. Experiments show APTQ surpasses previous quantization methods, achieving an average of 4 bit width a 5.22 perplexity nearly equivalent to full precision in the C4 dataset. In addition, APTQ attains state-of-the-art zero-shot accuracy of 68.24\% and 70.48\% at an average bitwidth of 3.8 in LLaMa-7B and LLaMa-13B, respectively, demonstrating its effectiveness to produce high-quality quantized LLMs.
Adaptive Speech Quality Aware Complex Neural Network for Acoustic Echo Cancellation with Supervised Contrastive Learning
Nov 09, 2022

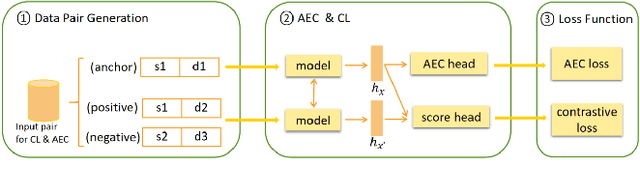

Acoustic echo cancellation (AEC) is designed to remove echoes, reverberation, and unwanted added sounds from the microphone signal while maintaining the quality of the near-end speaker's speech. This paper proposes adaptive speech quality complex neural networks to focus on specific tasks for real-time acoustic echo cancellation. In specific, we propose a complex modularize neural network with different stages to focus on feature extraction, acoustic separation, and mask optimization receptively. Furthermore, we adopt the contrastive learning framework and novel speech quality aware loss functions to further improve the performance. The model is trained with 72 hours for pre-training and then 72 hours for fine-tuning. The proposed model outperforms the state-of-the-art performance.
TAPL: Dynamic Part-based Visual Tracking via Attention-guided Part Localization
Oct 25, 2021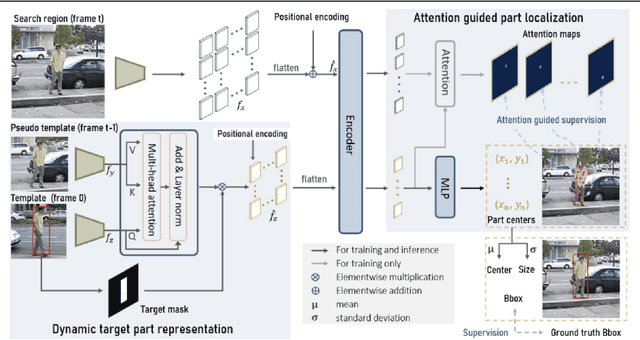



Holistic object representation-based trackers suffer from performance drop under large appearance change such as deformation and occlusion. In this work, we propose a dynamic part-based tracker and constantly update the target part representation to adapt to object appearance change. Moreover, we design an attention-guided part localization network to directly predict the target part locations, and determine the final bounding box with the distribution of target parts. Our proposed tracker achieves promising results on various benchmarks: VOT2018, OTB100 and GOT-10k
Supervised Contrastive Learning for Accented Speech Recognition
Jul 02, 2021
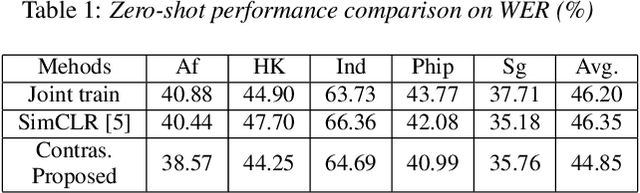


Neural network based speech recognition systems suffer from performance degradation due to accented speech, especially unfamiliar accents. In this paper, we study the supervised contrastive learning framework for accented speech recognition. To build different views (similar "positive" data samples) for contrastive learning, three data augmentation techniques including noise injection, spectrogram augmentation and TTS-same-sentence generation are further investigated. From the experiments on the Common Voice dataset, we have shown that contrastive learning helps to build data-augmentation invariant and pronunciation invariant representations, which significantly outperforms traditional joint training methods in both zero-shot and full-shot settings. Experiments show that contrastive learning can improve accuracy by 3.66% (zero-shot) and 3.78% (full-shot) on average, comparing to the joint training method.
Learning to Compensate: A Deep Neural Network Framework for 5G Power Amplifier Compensation
Jun 15, 2021
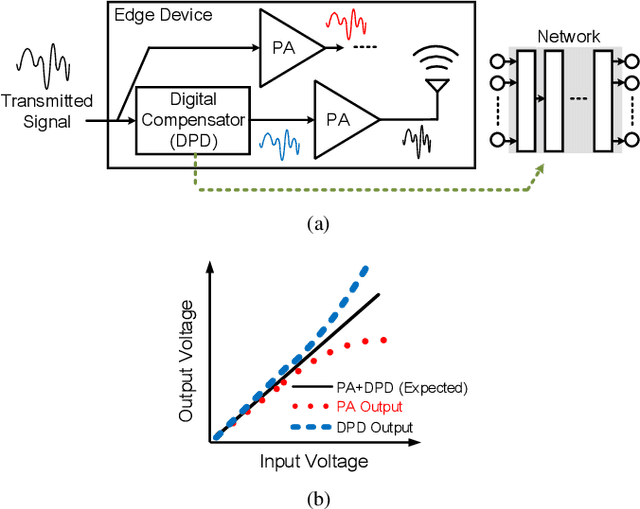


Owing to the complicated characteristics of 5G communication system, designing RF components through mathematical modeling becomes a challenging obstacle. Moreover, such mathematical models need numerous manual adjustments for various specification requirements. In this paper, we present a learning-based framework to model and compensate Power Amplifiers (PAs) in 5G communication. In the proposed framework, Deep Neural Networks (DNNs) are used to learn the characteristics of the PAs, while, correspondent Digital Pre-Distortions (DPDs) are also learned to compensate for the nonlinear and memory effects of PAs. On top of the framework, we further propose two frequency domain losses to guide the learning process to better optimize the target, compared to naive time domain Mean Square Error (MSE). The proposed framework serves as a drop-in replacement for the conventional approach. The proposed approach achieves an average of 56.7% reduction of nonlinear and memory effects, which converts to an average of 16.3% improvement over a carefully-designed mathematical model, and even reaches 34% enhancement in severe distortion scenarios.
Answer-checking in Context: A Multi-modal FullyAttention Network for Visual Question Answering
Oct 17, 2020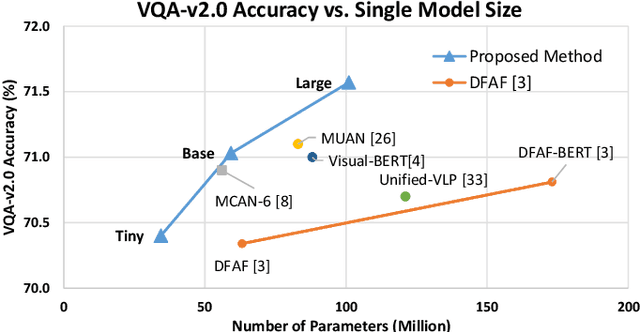
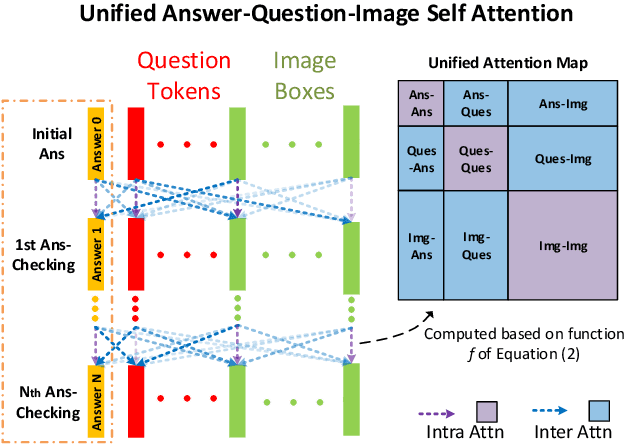
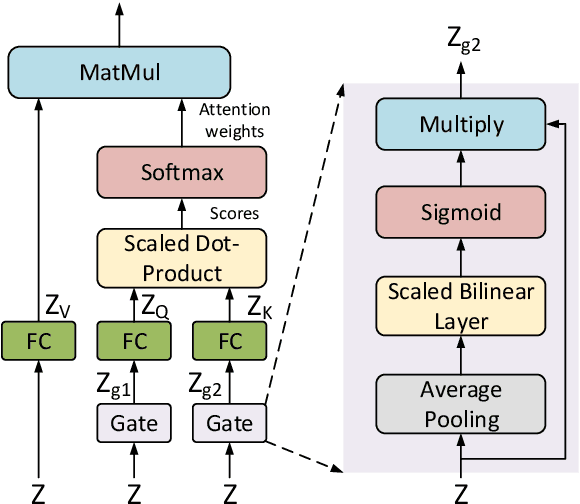
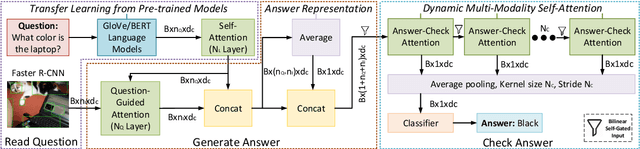
Visual Question Answering (VQA) is challenging due to the complex cross-modal relations. It has received extensive attention from the research community. From the human perspective, to answer a visual question, one needs to read the question and then refer to the image to generate an answer. This answer will then be checked against the question and image again for the final confirmation. In this paper, we mimic this process and propose a fully attention based VQA architecture. Moreover, an answer-checking module is proposed to perform a unified attention on the jointly answer, question and image representation to update the answer. This mimics the human answer checking process to consider the answer in the context. With answer-checking modules and transferred BERT layers, our model achieves the state-of-the-art accuracy 71.57\% using fewer parameters on VQA-v2.0 test-standard split.
Finding the Evidence: Localization-aware Answer Prediction for Text Visual Question Answering
Oct 06, 2020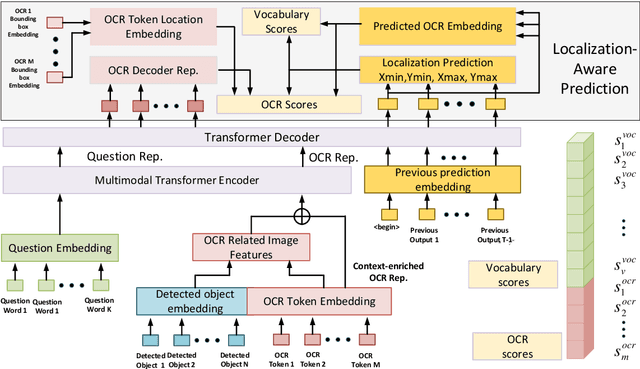
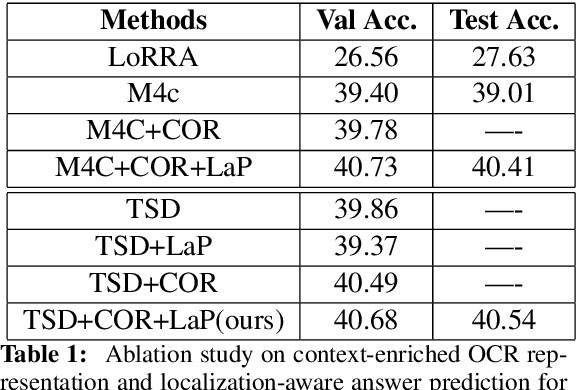


Image text carries essential information to understand the scene and perform reasoning. Text-based visual question answering (text VQA) task focuses on visual questions that require reading text in images. Existing text VQA systems generate an answer by selecting from optical character recognition (OCR) texts or a fixed vocabulary. Positional information of text is underused and there is a lack of evidence for the generated answer. As such, this paper proposes a localization-aware answer prediction network (LaAP-Net) to address this challenge. Our LaAP-Net not only generates the answer to the question but also predicts a bounding box as evidence of the generated answer. Moreover, a context-enriched OCR representation (COR) for multimodal fusion is proposed to facilitate the localization task. Our proposed LaAP-Net outperforms existing approaches on three benchmark datasets for the text VQA task by a noticeable margin.