 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswer-checking in Context: A Multi-modal FullyAttention Network for Visual Question Answering
Oct 17, 2020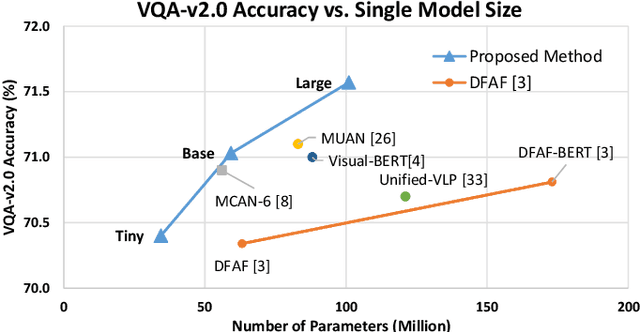
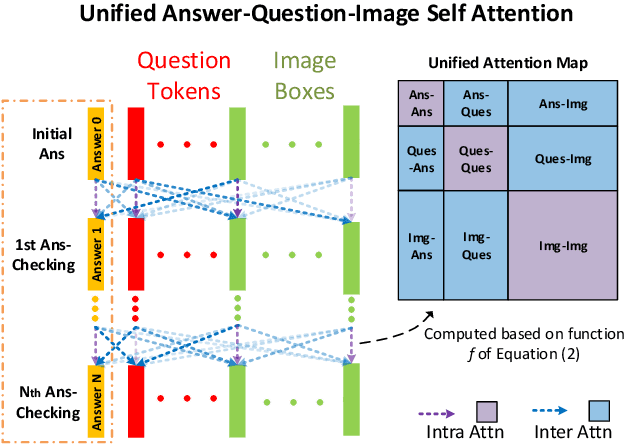
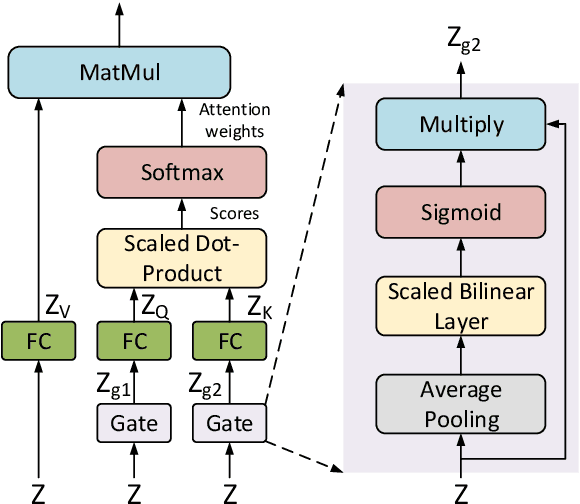
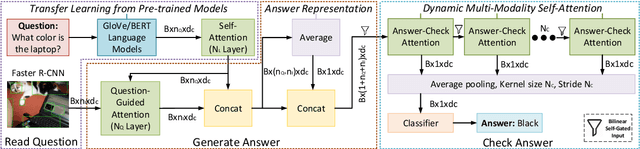
Visual Question Answering (VQA) is challenging due to the complex cross-modal relations. It has received extensive attention from the research community. From the human perspective, to answer a visual question, one needs to read the question and then refer to the image to generate an answer. This answer will then be checked against the question and image again for the final confirmation. In this paper, we mimic this process and propose a fully attention based VQA architecture. Moreover, an answer-checking module is proposed to perform a unified attention on the jointly answer, question and image representation to update the answer. This mimics the human answer checking process to consider the answer in the context. With answer-checking modules and transferred BERT layers, our model achieves the state-of-the-art accuracy 71.57\% using fewer parameters on VQA-v2.0 test-standard split.