 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Contrastive Learning for Accented Speech Recognition
Paper and Code
Jul 02, 2021
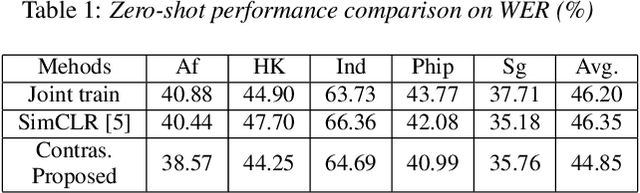


Neural network based speech recognition systems suffer from performance degradation due to accented speech, especially unfamiliar accents. In this paper, we study the supervised contrastive learning framework for accented speech recognition. To build different views (similar "positive" data samples) for contrastive learning, three data augmentation techniques including noise injection, spectrogram augmentation and TTS-same-sentence generation are further investigated. From the experiments on the Common Voice dataset, we have shown that contrastive learning helps to build data-augmentation invariant and pronunciation invariant representations, which significantly outperforms traditional joint training methods in both zero-shot and full-shot settings. Experiments show that contrastive learning can improve accuracy by 3.66% (zero-shot) and 3.78% (full-shot) on average, comparing to the joint training method.