 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Acceptance Score: A Holistic Measure for Biometric Quantification
Feb 17, 2026Quantifying biometric characteristics within hand gestures involve derivation of fitness scores from a gesture and identity aware feature space. However, evaluating the quality of these scores remains an open question. Existing biometric capacity estimation literature relies upon error rates. But these rates do not indicate goodness of scores. Thus, in this manuscript we present an exhaustive set of evaluation measures. We firstly identify ranking order and relevance of output scores as the primary basis for evaluation. In particular, we consider both rank deviation as well as rewards for: (i) higher scores of high ranked gestures and (ii) lower scores of low ranked gestures. We also compensate for correspondence between trends of output and ground truth scores. Finally, we account for disentanglement between identity features of gestures as a discounting factor. Integrating these elements with adequate weighting, we formulate advanced acceptance score as a holistic evaluation measure. To assess effectivity of the proposed we perform in-depth experimentation over three datasets with five state-of-the-art (SOTA) models. Results show that the optimal score selected with our measure is more appropriate than existing other measures. Also, our proposed measure depicts correlation with existing measures. This further validates its reliability. We have made our \href{https://github.com/AmanVerma2307/MeasureSuite}{code} public.
On Characterizing the Evolution of Embedding Space of Neural Networks using Algebraic Topology
Nov 09, 2023We study how the topology of feature embedding space changes as it passes through the layers of a well-trained deep neural network (DNN) through Betti numbers. Motivated by existing studies using simplicial complexes on shallow fully connected networks (FCN), we present an extended analysis using Cubical homology instead, with a variety of popular deep architectures and real image datasets. We demonstrate that as depth increases, a topologically complicated dataset is transformed into a simple one, resulting in Betti numbers attaining their lowest possible value. The rate of decay in topological complexity (as a metric) helps quantify the impact of architectural choices on the generalization ability. Interestingly from a representation learning perspective, we highlight several invariances such as topological invariance of (1) an architecture on similar datasets; (2) embedding space of a dataset for architectures of variable depth; (3) embedding space to input resolution/size, and (4) data sub-sampling. In order to further demonstrate the link between expressivity \& the generalization capability of a network, we consider the task of ranking pre-trained models for downstream classification task (transfer learning). Compared to existing approaches, the proposed metric has a better correlation to the actually achievable accuracy via fine-tuning the pre-trained model.
Softmax Gradient Tampering: Decoupling the Backward Pass for Improved Fitting
Nov 24, 2021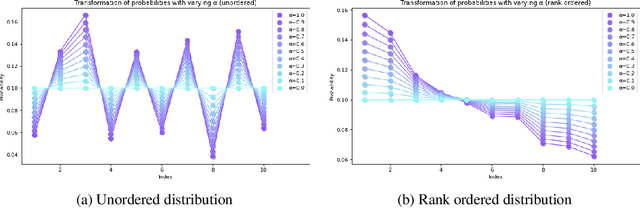
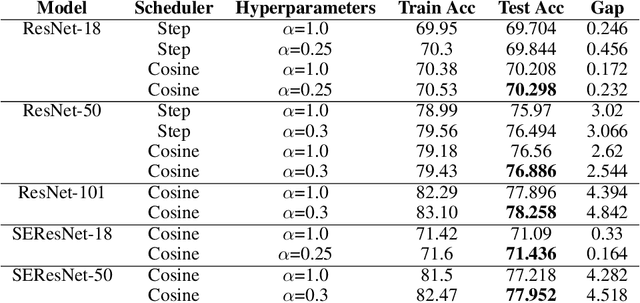
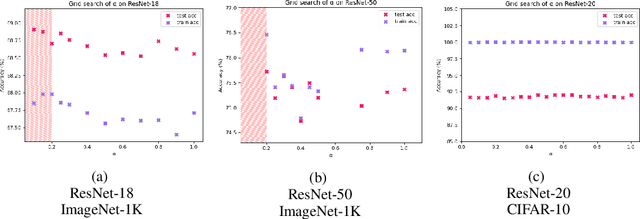

We introduce Softmax Gradient Tampering, a technique for modifying the gradients in the backward pass of neural networks in order to enhance their accuracy. Our approach transforms the predicted probability values using a power-based probability transformation and then recomputes the gradients in the backward pass. This modification results in a smoother gradient profile, which we demonstrate empirically and theoretically. We do a grid search for the transform parameters on residual networks. We demonstrate that modifying the softmax gradients in ConvNets may result in increased training accuracy, thus increasing the fit across the training data and maximally utilizing the learning capacity of neural networks. We get better test metrics and lower generalization gaps when combined with regularization techniques such as label smoothing. Softmax gradient tampering improves ResNet-50's test accuracy by $0.52\%$ over the baseline on the ImageNet dataset. Our approach is very generic and may be used across a wide range of different network architectures and datasets.
DFCANet: Dense Feature Calibration-Attention Guided Network for Cross Domain Iris Presentation Attack Detection
Nov 01, 2021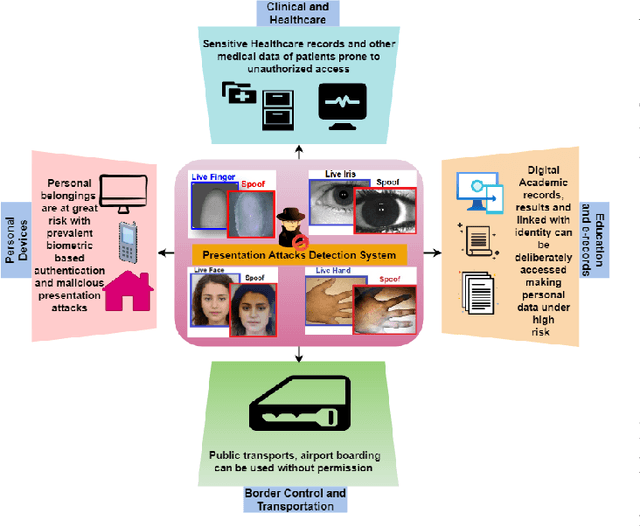
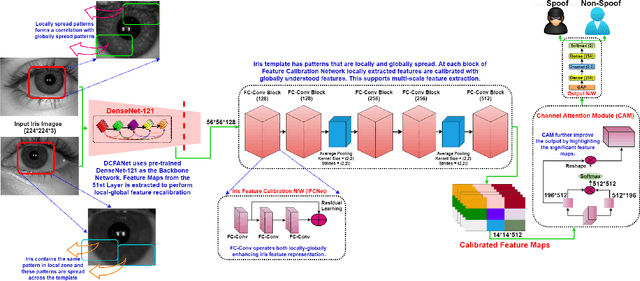
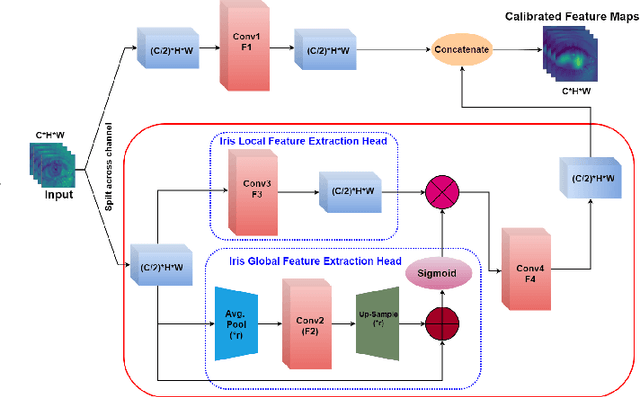
An iris presentation attack detection (IPAD) is essential for securing personal identity is widely used iris recognition systems. However, the existing IPAD algorithms do not generalize well to unseen and cross-domain scenarios because of capture in unconstrained environments and high visual correlation amongst bonafide and attack samples. These similarities in intricate textural and morphological patterns of iris ocular images contribute further to performance degradation. To alleviate these shortcomings, this paper proposes DFCANet: Dense Feature Calibration and Attention Guided Network which calibrates the locally spread iris patterns with the globally located ones. Uplifting advantages from feature calibration convolution and residual learning, DFCANet generates domain-specific iris feature representations. Since some channels in the calibrated feature maps contain more prominent information, we capitalize discriminative feature learning across the channels through the channel attention mechanism. In order to intensify the challenge for our proposed model, we make DFCANet operate over nonsegmented and non-normalized ocular iris images. Extensive experimentation conducted over challenging cross-domain and intra-domain scenarios highlights consistent outperforming results. Compared to state-of-the-art methods, DFCANet achieves significant gains in performance for the benchmark IIITD CLI, IIIT CSD and NDCLD13 databases respectively. Further, a novel incremental learning-based methodology has been introduced so as to overcome disentangled iris-data characteristics and data scarcity. This paper also pursues the challenging scenario that considers soft-lens under the attack category with evaluation performed under various cross-domain protocols. The code will be made publicly available.
Sensor-invariant Fingerprint ROI Segmentation Using Recurrent Adversarial Learning
Jul 03, 2021
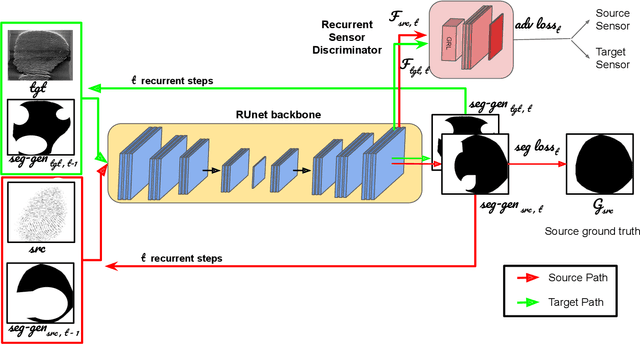

A fingerprint region of interest (roi) segmentation algorithm is designed to separate the foreground fingerprint from the background noise. All the learning based state-of-the-art fingerprint roi segmentation algorithms proposed in the literature are benchmarked on scenarios when both training and testing databases consist of fingerprint images acquired from the same sensors. However, when testing is conducted on a different sensor, the segmentation performance obtained is often unsatisfactory. As a result, every time a new fingerprint sensor is used for testing, the fingerprint roi segmentation model needs to be re-trained with the fingerprint image acquired from the new sensor and its corresponding manually marked ROI. Manually marking fingerprint ROI is expensive because firstly, it is time consuming and more importantly, requires domain expertise. In order to save the human effort in generating annotations required by state-of-the-art, we propose a fingerprint roi segmentation model which aligns the features of fingerprint images derived from the unseen sensor such that they are similar to the ones obtained from the fingerprints whose ground truth roi masks are available for training. Specifically, we propose a recurrent adversarial learning based feature alignment network that helps the fingerprint roi segmentation model to learn sensor-invariant features. Consequently, sensor-invariant features learnt by the proposed roi segmentation model help it to achieve improved segmentation performance on fingerprints acquired from the new sensor. Experiments on publicly available FVC databases demonstrate the efficacy of the proposed work.
* IJCNN 2021 (Accepted)
Data Uncertainty Guided Noise-aware Preprocessing Of Fingerprints
Jul 02, 2021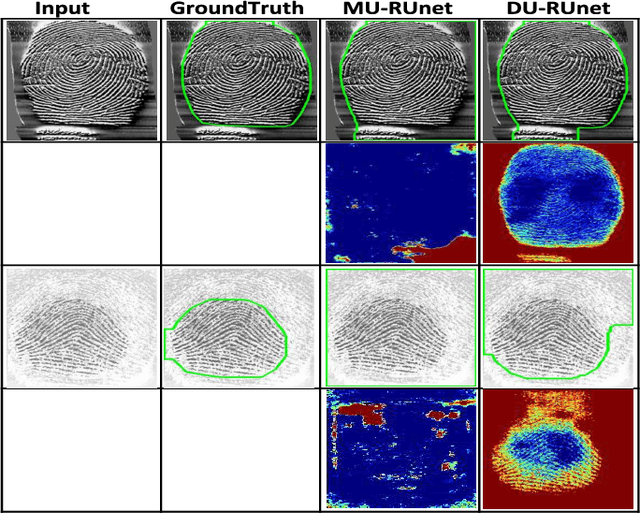
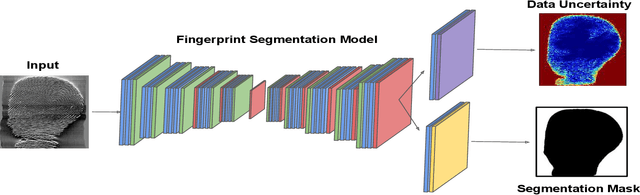
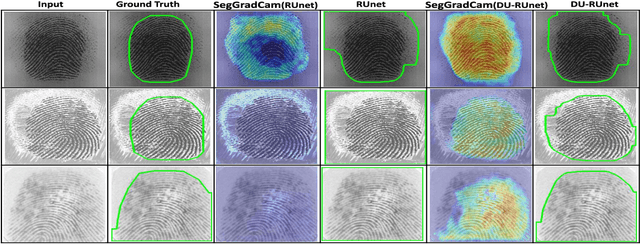

The effectiveness of fingerprint-based authentication systems on good quality fingerprints is established long back. However, the performance of standard fingerprint matching systems on noisy and poor quality fingerprints is far from satisfactory. Towards this, we propose a data uncertainty-based framework which enables the state-of-the-art fingerprint preprocessing models to quantify noise present in the input image and identify fingerprint regions with background noise and poor ridge clarity. Quantification of noise helps the model two folds: firstly, it makes the objective function adaptive to the noise in a particular input fingerprint and consequently, helps to achieve robust performance on noisy and distorted fingerprint regions. Secondly, it provides a noise variance map which indicates noisy pixels in the input fingerprint image. The predicted noise variance map enables the end-users to understand erroneous predictions due to noise present in the input image. Extensive experimental evaluation on 13 publicly available fingerprint databases, across different architectural choices and two fingerprint processing tasks demonstrate effectiveness of the proposed framework.
High Accuracy Classification of Parkinson's Disease through Shape Analysis and Surface Fitting in $^{123}$I-Ioflupane SPECT Imaging
Mar 04, 2017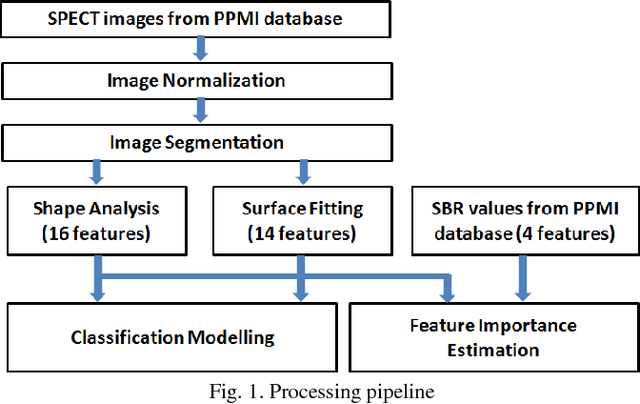
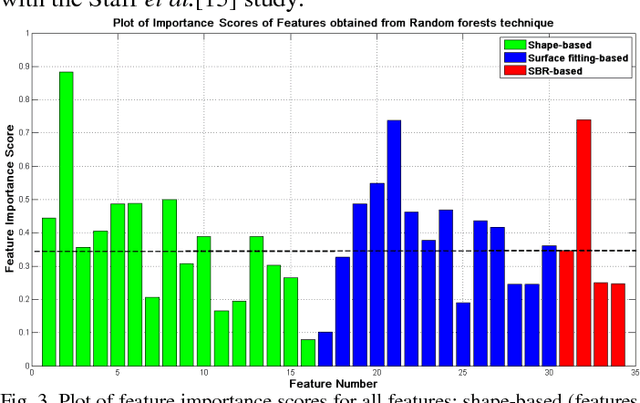
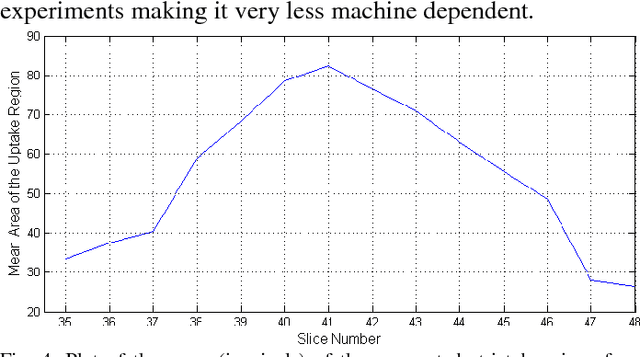
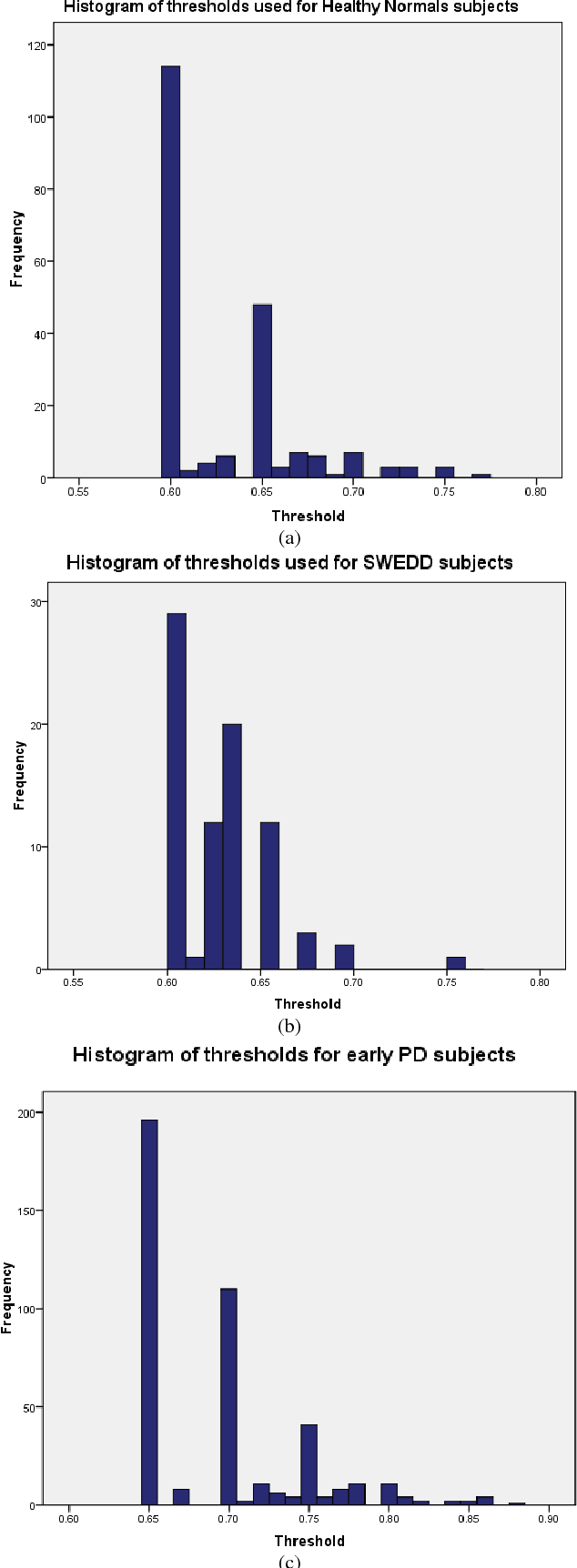
Early and accurate identification of parkinsonian syndromes (PS) involving presynaptic degeneration from non-degenerative variants such as Scans Without Evidence of Dopaminergic Deficit (SWEDD) and tremor disorders, is important for effective patient management as the course, therapy and prognosis differ substantially between the two groups. In this study, we use Single Photon Emission Computed Tomography (SPECT) images from healthy normal, early PD and SWEDD subjects, as obtained from the Parkinson's Progression Markers Initiative (PPMI) database, and process them to compute shape- and surface fitting-based features for the three groups. We use these features to develop and compare various classification models that can discriminate between scans showing dopaminergic deficit, as in PD, from scans without the deficit, as in healthy normal or SWEDD. Along with it, we also compare these features with Striatal Binding Ratio (SBR)-based features, which are well-established and clinically used, by computing a feature importance score using Random forests technique. We observe that the Support Vector Machine (SVM) classifier gave the best performance with an accuracy of 97.29%. These features also showed higher importance than the SBR-based features. We infer from the study that shape analysis and surface fitting are useful and promising methods for extracting discriminatory features that can be used to develop diagnostic models that might have the potential to help clinicians in the diagnostic process.