 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLADIMO: Face Morph Generation through Biometric Template Inversion with Latent Diffusion
Oct 10, 2024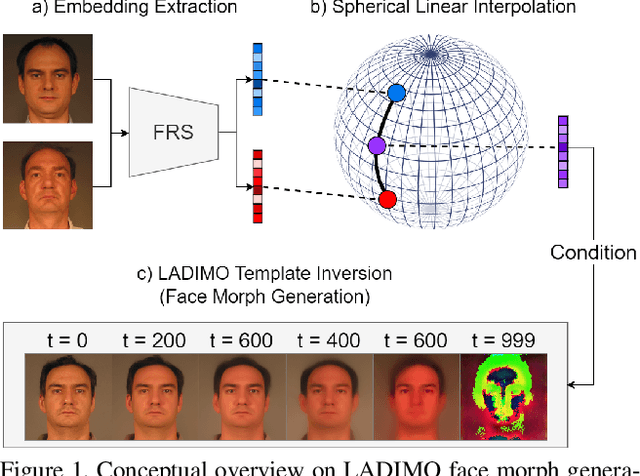

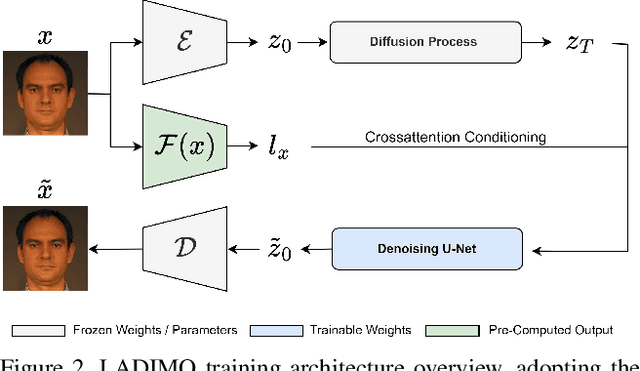

Face morphing attacks pose a severe security threat to face recognition systems, enabling the morphed face image to be verified against multiple identities. To detect such manipulated images, the development of new face morphing methods becomes essential to increase the diversity of training datasets used for face morph detection. In this study, we present a representation-level face morphing approach, namely LADIMO, that performs morphing on two face recognition embeddings. Specifically, we train a Latent Diffusion Model to invert a biometric template - thus reconstructing the face image from an FRS latent representation. Our subsequent vulnerability analysis demonstrates the high morph attack potential in comparison to MIPGAN-II, an established GAN-based face morphing approach. Finally, we exploit the stochastic LADMIO model design in combination with our identity conditioning mechanism to create unlimited morphing attacks from a single face morph image pair. We show that each face morph variant has an individual attack success rate, enabling us to maximize the morph attack potential by applying a simple re-sampling strategy. Code and pre-trained models available here: https://github.com/dasec/LADIMO
Efficient Expression Neutrality Estimation with Application to Face Recognition Utility Prediction
Feb 08, 2024



The recognition performance of biometric systems strongly depends on the quality of the compared biometric samples. Motivated by the goal of establishing a common understanding of face image quality and enabling system interoperability, the committee draft of ISO/IEC 29794-5 introduces expression neutrality as one of many component quality elements affecting recognition performance. In this study, we train classifiers to assess facial expression neutrality using seven datasets. We conduct extensive performance benchmarking to evaluate their classification and face recognition utility prediction abilities. Our experiments reveal significant differences in how each classifier distinguishes "neutral" from "non-neutral" expressions. While Random Forests and AdaBoost classifiers are most suitable for distinguishing neutral from non-neutral facial expressions with high accuracy, they underperform compared to Support Vector Machines in predicting face recognition utility.
EGAIN: Extended GAn INversion
Dec 22, 2023Generative Adversarial Networks (GANs) have witnessed significant advances in recent years, generating increasingly higher quality images, which are non-distinguishable from real ones. Recent GANs have proven to encode features in a disentangled latent space, enabling precise control over various semantic attributes of the generated facial images such as pose, illumination, or gender. GAN inversion, which is projecting images into the latent space of a GAN, opens the door for the manipulation of facial semantics of real face images. This is useful for numerous applications such as evaluating the performance of face recognition systems. In this work, EGAIN, an architecture for constructing GAN inversion models, is presented. This architecture explicitly addresses some of the shortcomings in previous GAN inversion models. A specific model with the same name, egain, based on this architecture is also proposed, demonstrating superior reconstruction quality over state-of-the-art models, and illustrating the validity of the EGAIN architecture.
NeutrEx: A 3D Quality Component Measure on Facial Expression Neutrality
Aug 19, 2023Accurate face recognition systems are increasingly important in sensitive applications like border control or migration management. Therefore, it becomes crucial to quantify the quality of facial images to ensure that low-quality images are not affecting recognition accuracy. In this context, the current draft of ISO/IEC 29794-5 introduces the concept of component quality to estimate how single factors of variation affect recognition outcomes. In this study, we propose a quality measure (NeutrEx) based on the accumulated distances of a 3D face reconstruction to a neutral expression anchor. Our evaluations demonstrate the superiority of our proposed method compared to baseline approaches obtained by training Support Vector Machines on face embeddings extracted from a pre-trained Convolutional Neural Network for facial expression classification. Furthermore, we highlight the explainable nature of our NeutrEx measures by computing per-vertex distances to unveil the most impactful face regions and allow operators to give actionable feedback to subjects.
Pose Impact Estimation on Face Recognition using 3D-Aware Synthetic Data with Application to Quality Assessment
Mar 01, 2023Evaluating the quality of facial images is essential for operating face recognition systems with sufficient accuracy. The recent advances in face quality standardisation (ISO/IEC WD 29794-5) recommend the usage of component quality measures for breaking down face quality into its individual factors, hence providing valuable feedback for operators to re-capture low-quality images. In light of recent advances in 3D-aware generative adversarial networks, we propose a novel dataset, "Syn-YawPitch", comprising 1,000 identities with varying yaw-pitch angle combinations. Utilizing this dataset, we demonstrate that pitch angles beyond 30 degrees have a significant impact on the biometric performance of current face recognition systems. Furthermore, we propose a lightweight and efficient pose quality predictor that adheres to the standards of ISO/IEC WD 29794-5 and is freely available for use at https://github.com/datasciencegrimmer/Syn-YawPitch/.
Synthetic Data in Human Analysis: A Survey
Aug 19, 2022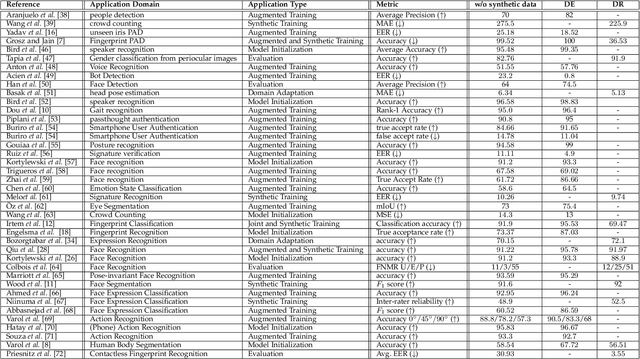



Deep neural networks have become prevalent in human analysis, boosting the performance of applications, such as biometric recognition, action recognition, as well as person re-identification. However, the performance of such networks scales with the available training data. In human analysis, the demand for large-scale datasets poses a severe challenge, as data collection is tedious, time-expensive, costly and must comply with data protection laws. Current research investigates the generation of \textit{synthetic data} as an efficient and privacy-ensuring alternative to collecting real data in the field. This survey introduces the basic definitions and methodologies, essential when generating and employing synthetic data for human analysis. We conduct a survey that summarises current state-of-the-art methods and the main benefits of using synthetic data. We also provide an overview of publicly available synthetic datasets and generation models. Finally, we discuss limitations, as well as open research problems in this field. This survey is intended for researchers and practitioners in the field of human analysis.
Time flies by: Analyzing the Impact of Face Ageing on the Recognition Performance with Synthetic Data
Aug 17, 2022



The vast progress in synthetic image synthesis enables the generation of facial images in high resolution and photorealism. In biometric applications, the main motivation for using synthetic data is to solve the shortage of publicly-available biometric data while reducing privacy risks when processing such sensitive information. These advantages are exploited in this work by simulating human face ageing with recent face age modification algorithms to generate mated samples, thereby studying the impact of ageing on the performance of an open-source biometric recognition system. Further, a real dataset is used to evaluate the effects of short-term ageing, comparing the biometric performance to the synthetic domain. The main findings indicate that short-term ageing in the range of 1-5 years has only minor effects on the general recognition performance. However, the correct verification of mated faces with long-term age differences beyond 20 years poses still a significant challenge and requires further investigation.
Generation of Non-Deterministic Synthetic Face Datasets Guided by Identity Priors
Dec 07, 2021


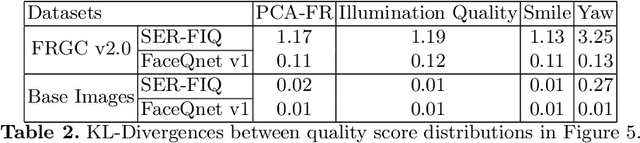
Enabling highly secure applications (such as border crossing) with face recognition requires extensive biometric performance tests through large scale data. However, using real face images raises concerns about privacy as the laws do not allow the images to be used for other purposes than originally intended. Using representative and subsets of face data can also lead to unwanted demographic biases and cause an imbalance in datasets. One possible solution to overcome these issues is to replace real face images with synthetically generated samples. While generating synthetic images has benefited from recent advancements in computer vision, generating multiple samples of the same synthetic identity resembling real-world variations is still unaddressed, i.e., mated samples. This work proposes a non-deterministic method for generating mated face images by exploiting the well-structured latent space of StyleGAN. Mated samples are generated by manipulating latent vectors, and more precisely, we exploit Principal Component Analysis (PCA) to define semantically meaningful directions in the latent space and control the similarity between the original and the mated samples using a pre-trained face recognition system. We create a new dataset of synthetic face images (SymFace) consisting of 77,034 samples including 25,919 synthetic IDs. Through our analysis using well-established face image quality metrics, we demonstrate the differences in the biometric quality of synthetic samples mimicking characteristics of real biometric data. The analysis and results thereof indicate the use of synthetic samples created using the proposed approach as a viable alternative to replacing real biometric data.
On the Applicability of Synthetic Data for Face Recognition
Apr 06, 2021


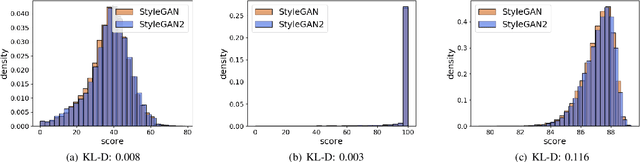
Face verification has come into increasing focus in various applications including the European Entry/Exit System, which integrates face recognition mechanisms. At the same time, the rapid advancement of biometric authentication requires extensive performance tests in order to inhibit the discriminatory treatment of travellers due to their demographic background. However, the use of face images collected as part of border controls is restricted by the European General Data Protection Law to be processed for no other reason than its original purpose. Therefore, this paper investigates the suitability of synthetic face images generated with StyleGAN and StyleGAN2 to compensate for the urgent lack of publicly available large-scale test data. Specifically, two deep learning-based (SER-FIQ, FaceQnet v1) and one standard-based (ISO/IEC TR 29794-5) face image quality assessment algorithm is utilized to compare the applicability of synthetic face images compared to real face images extracted from the FRGC dataset. Finally, based on the analysis of impostor score distributions and utility score distributions, our experiments reveal negligible differences between StyleGAN vs. StyleGAN2, and further also minor discrepancies compared to real face images.
Anomaly Detection with Convolutional Autoencoders for Fingerprint Presentation Attack Detection
Aug 18, 2020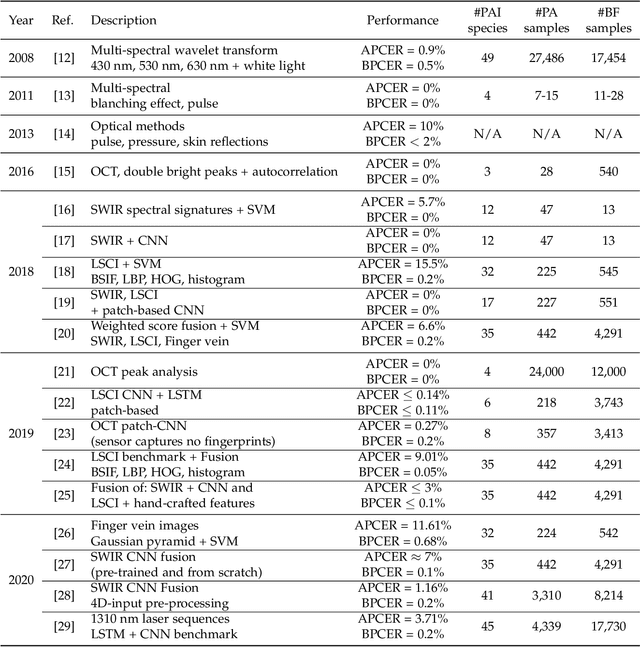
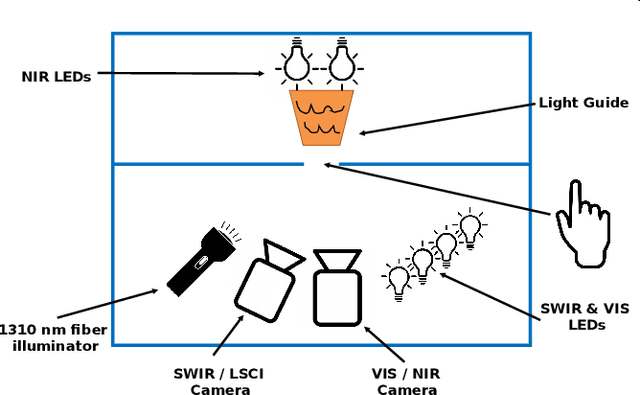
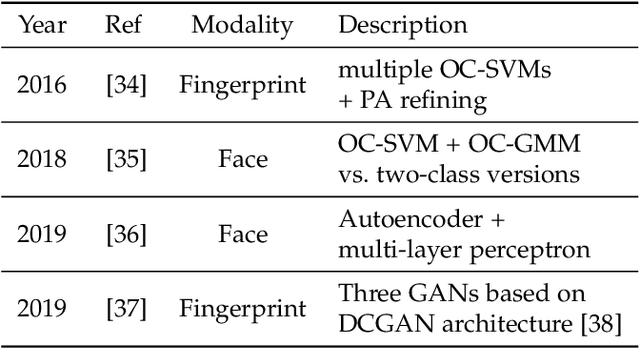

In recent years, the popularity of fingerprint-based biometric authentication systems has significantly increased. However, together with many advantages, biometric systems are still vulnerable to presentation attacks (PAs). In particular, this applies for unsupervised applications, where new attacks unknown to the system operator may occur. Therefore, presentation attack detection (PAD) methods are used to determine whether samples stem from a live subject (bona fide) or from a presentation attack instrument (PAI). In this context, most works are dedicated to solve PAD as a two-class classification problem, which includes training a model on both bona fide and PA samples. In spite of the good detection rates reported, these methods still face difficulties detecting PAIs from unknown materials. To address this issue, we propose a new PAD technique based on autoencoders (AEs) trained only on bona fide samples (i.e. one-class). On the experimental evaluation over a database of 19,711 bona fide and 4,339 PA images, including 45 different PAI species, a detection equal error rate (D-EER) of 2.00% was achieved. Additionally, our best performing AE model is compared to further one-class classifiers (support vector machine, Gaussian mixture model). The results show the effectiveness of the AE model as it significantly outperforms the previously proposed methods.