 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration of Non-Deterministic Synthetic Face Datasets Guided by Identity Priors
Paper and Code
Dec 07, 2021


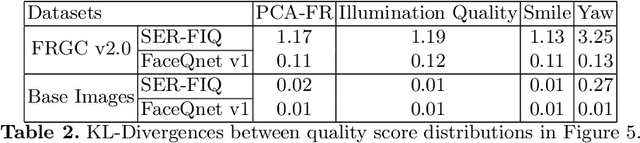
Enabling highly secure applications (such as border crossing) with face recognition requires extensive biometric performance tests through large scale data. However, using real face images raises concerns about privacy as the laws do not allow the images to be used for other purposes than originally intended. Using representative and subsets of face data can also lead to unwanted demographic biases and cause an imbalance in datasets. One possible solution to overcome these issues is to replace real face images with synthetically generated samples. While generating synthetic images has benefited from recent advancements in computer vision, generating multiple samples of the same synthetic identity resembling real-world variations is still unaddressed, i.e., mated samples. This work proposes a non-deterministic method for generating mated face images by exploiting the well-structured latent space of StyleGAN. Mated samples are generated by manipulating latent vectors, and more precisely, we exploit Principal Component Analysis (PCA) to define semantically meaningful directions in the latent space and control the similarity between the original and the mated samples using a pre-trained face recognition system. We create a new dataset of synthetic face images (SymFace) consisting of 77,034 samples including 25,919 synthetic IDs. Through our analysis using well-established face image quality metrics, we demonstrate the differences in the biometric quality of synthetic samples mimicking characteristics of real biometric data. The analysis and results thereof indicate the use of synthetic samples created using the proposed approach as a viable alternative to replacing real biometric data.