 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Image Land Cover Captioning Dataset for Vision Language Models
May 18, 2025We introduce HyperCap, the first large-scale hyperspectral captioning dataset designed to enhance model performance and effectiveness in remote sensing applications. Unlike traditional hyperspectral imaging (HSI) datasets that focus solely on classification tasks, HyperCap integrates spectral data with pixel-wise textual annotations, enabling deeper semantic understanding of hyperspectral imagery. This dataset enhances model performance in tasks like classification and feature extraction, providing a valuable resource for advanced remote sensing applications. HyperCap is constructed from four benchmark datasets and annotated through a hybrid approach combining automated and manual methods to ensure accuracy and consistency. Empirical evaluations using state-of-the-art encoders and diverse fusion techniques demonstrate significant improvements in classification performance. These results underscore the potential of vision-language learning in HSI and position HyperCap as a foundational dataset for future research in the field.
Leveraging Task-Specific Knowledge from LLM for Semi-Supervised 3D Medical Image Segmentation
Jul 06, 2024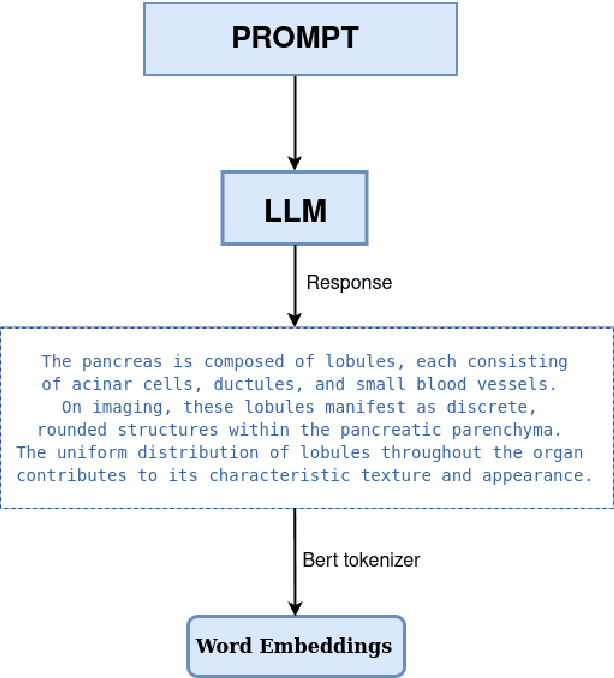
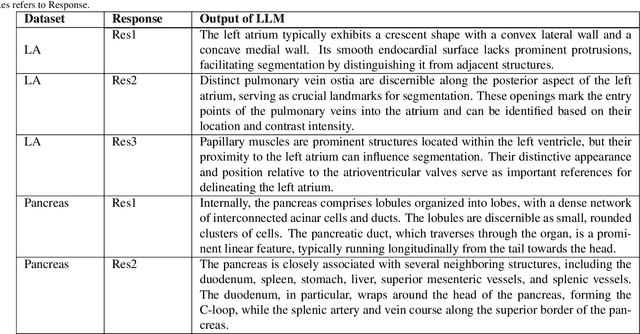
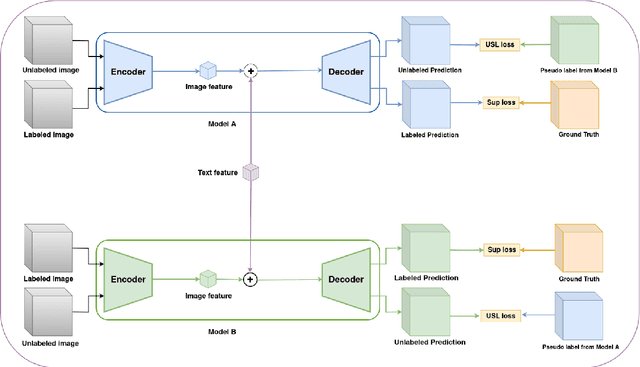
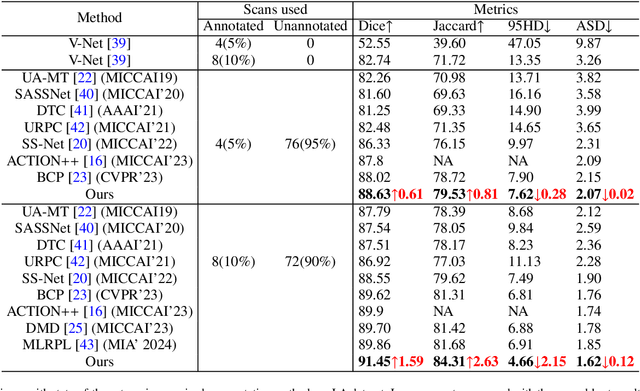
Traditional supervised 3D medical image segmentation models need voxel-level annotations, which require huge human effort, time, and cost. Semi-supervised learning (SSL) addresses this limitation of supervised learning by facilitating learning with a limited annotated and larger amount of unannotated training samples. However, state-of-the-art SSL models still struggle to fully exploit the potential of learning from unannotated samples. To facilitate effective learning from unannotated data, we introduce LLM-SegNet, which exploits a large language model (LLM) to integrate task-specific knowledge into our co-training framework. This knowledge aids the model in comprehensively understanding the features of the region of interest (ROI), ultimately leading to more efficient segmentation. Additionally, to further reduce erroneous segmentation, we propose a Unified Segmentation loss function. This loss function reduces erroneous segmentation by not only prioritizing regions where the model is confident in predicting between foreground or background pixels but also effectively addressing areas where the model lacks high confidence in predictions. Experiments on publicly available Left Atrium, Pancreas-CT, and Brats-19 datasets demonstrate the superior performance of LLM-SegNet compared to the state-of-the-art. Furthermore, we conducted several ablation studies to demonstrate the effectiveness of various modules and loss functions leveraged by LLM-SegNet.