 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Multi-Modal Pre-Training for Automatic Speech Recognition
Paper and Code
Mar 28, 2024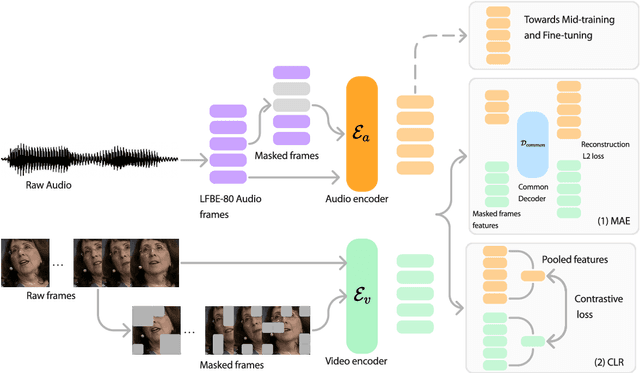
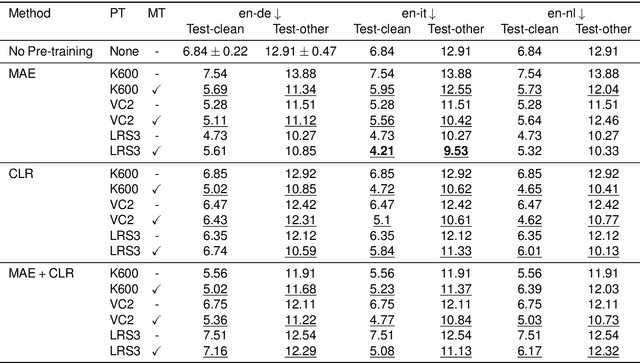
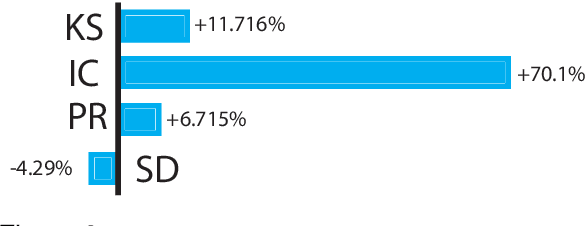
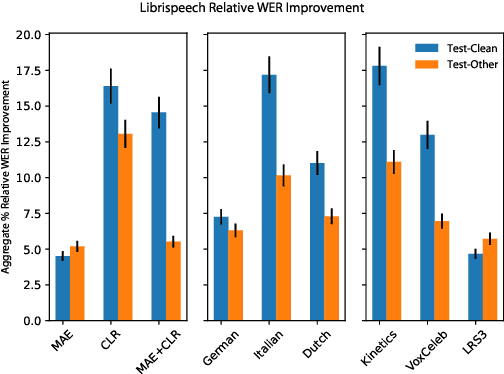
Recent advances in machine learning have demonstrated that multi-modal pre-training can improve automatic speech recognition (ASR) performance compared to randomly initialized models, even when models are fine-tuned on uni-modal tasks. Existing multi-modal pre-training methods for the ASR task have primarily focused on single-stage pre-training where a single unsupervised task is used for pre-training followed by fine-tuning on the downstream task. In this work, we introduce a novel method combining multi-modal and multi-task unsupervised pre-training with a translation-based supervised mid-training approach. We empirically demonstrate that such a multi-stage approach leads to relative word error rate (WER) improvements of up to 38.45% over baselines on both Librispeech and SUPERB. Additionally, we share several important findings for choosing pre-training methods and datasets.