 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuRep: Dual-Mode Speech Representation Learning via ASR-Aware Distillation
May 26, 2025Recent advancements in speech encoders have drawn attention due to their integration with Large Language Models for various speech tasks. While most research has focused on either causal or full-context speech encoders, there's limited exploration to effectively handle both streaming and non-streaming applications, while achieving state-of-the-art performance. We introduce DuRep, a Dual-mode Speech Representation learning setup, which enables a single speech encoder to function efficiently in both offline and online modes without additional parameters or mode-specific adjustments, across downstream tasks. DuRep-200M, our 200M parameter dual-mode encoder, achieves 12% and 11.6% improvements in streaming and non-streaming modes, over baseline encoders on Multilingual ASR. Scaling this approach to 2B parameters, DuRep-2B sets new performance benchmarks across ASR and non-ASR tasks. Our analysis reveals interesting trade-offs between acoustic and semantic information across encoder layers.
Multi-Modal Pre-Training for Automated Speech Recognition
Oct 12, 2021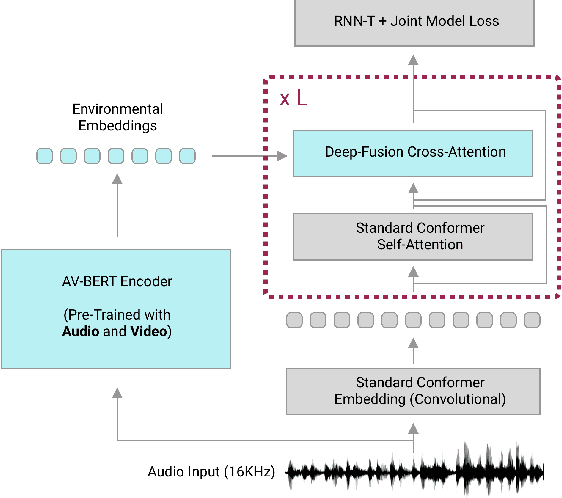
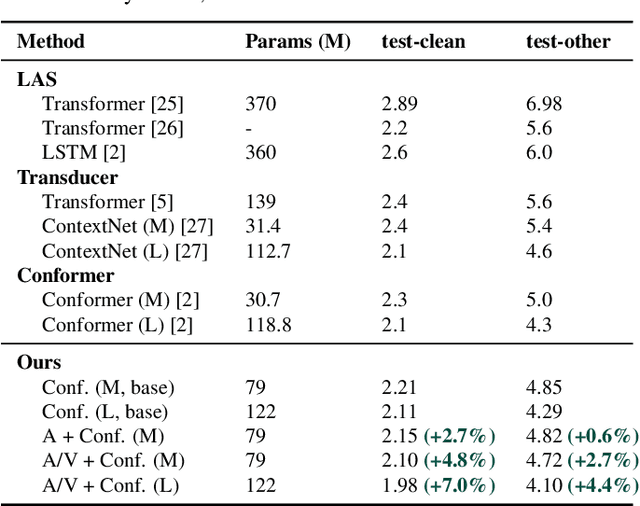
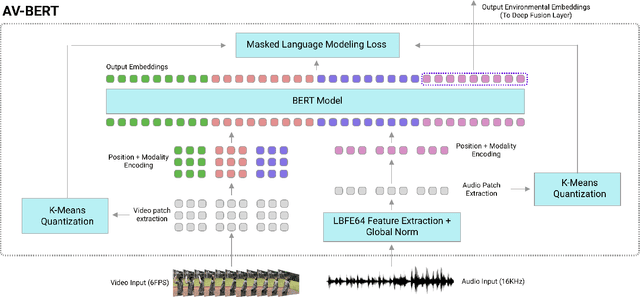
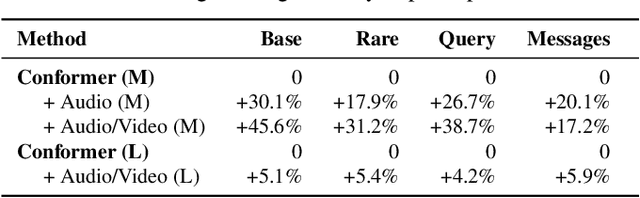
Traditionally, research in automated speech recognition has focused on local-first encoding of audio representations to predict the spoken phonemes in an utterance. Unfortunately, approaches relying on such hyper-local information tend to be vulnerable to both local-level corruption (such as audio-frame drops, or loud noises) and global-level noise (such as environmental noise, or background noise) that has not been seen during training. In this work, we introduce a novel approach which leverages a self-supervised learning technique based on masked language modeling to compute a global, multi-modal encoding of the environment in which the utterance occurs. We then use a new deep-fusion framework to integrate this global context into a traditional ASR method, and demonstrate that the resulting method can outperform baseline methods by up to 7% on Librispeech; gains on internal datasets range from 6% (on larger models) to 45% (on smaller models).
Knowledge Distillation and Data Selection for Semi-Supervised Learning in CTC Acoustic Models
Aug 10, 2020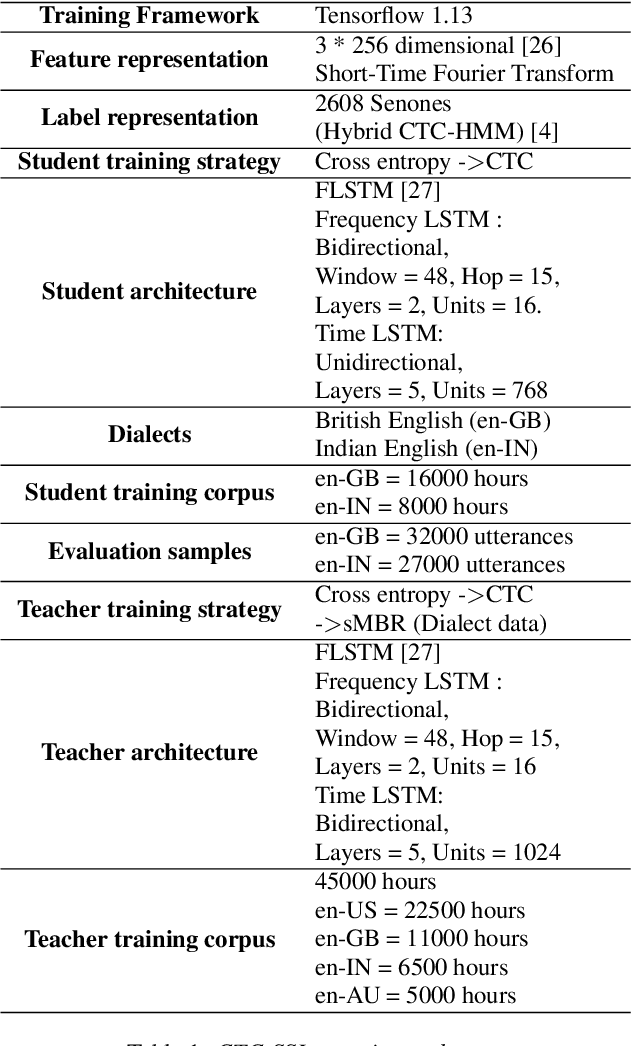
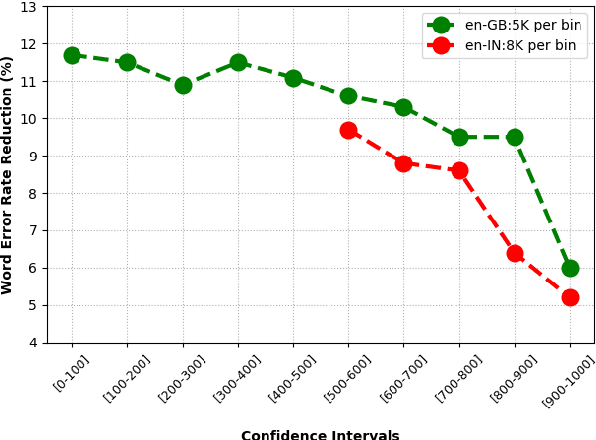
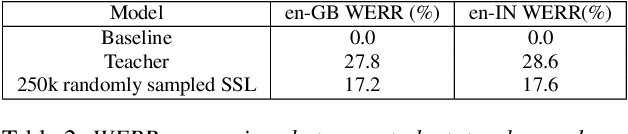
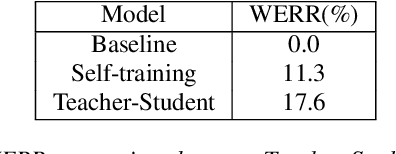
Semi-supervised learning (SSL) is an active area of research which aims to utilize unlabelled data in order to improve the accuracy of speech recognition systems. The current study proposes a methodology for integration of two key ideas: 1) SSL using connectionist temporal classification (CTC) objective and teacher-student based learning 2) Designing effective data-selection mechanisms for leveraging unlabelled data to boost performance of student models. Our aim is to establish the importance of good criteria in selecting samples from a large pool of unlabelled data based on attributes like confidence measure, speaker and content variability. The question we try to answer is: Is it possible to design a data selection mechanism which reduces dependence on a large set of randomly selected unlabelled samples without compromising on Word Error Rate (WER)? We perform empirical investigations of different data selection methods to answer this question and quantify the effect of different sampling strategies. On a semi-supervised ASR setting with 40000 hours of carefully selected unlabelled data, our CTC-SSL approach gives 17% relative WER improvement over a baseline CTC system trained with labelled data. It also achieves on-par performance with CTC-SSL system trained on order of magnitude larger unlabeled data based on random sampling.