 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEM-MIAs: Enhancing Membership Inference Attacks in Large Language Models through Ensemble Modeling
Dec 23, 2024

With the widespread application of large language models (LLM), concerns about the privacy leakage of model training data have increasingly become a focus. Membership Inference Attacks (MIAs) have emerged as a critical tool for evaluating the privacy risks associated with these models. Although existing attack methods, such as LOSS, Reference-based, min-k, and zlib, perform well in certain scenarios, their effectiveness on large pre-trained language models often approaches random guessing, particularly in the context of large-scale datasets and single-epoch training. To address this issue, this paper proposes a novel ensemble attack method that integrates several existing MIAs techniques (LOSS, Reference-based, min-k, zlib) into an XGBoost-based model to enhance overall attack performance (EM-MIAs). Experimental results demonstrate that the ensemble model significantly improves both AUC-ROC and accuracy compared to individual attack methods across various large language models and datasets. This indicates that by combining the strengths of different methods, we can more effectively identify members of the model's training data, thereby providing a more robust tool for evaluating the privacy risks of LLM. This study offers new directions for further research in the field of LLM privacy protection and underscores the necessity of developing more powerful privacy auditing methods.
Layer Importance and Hallucination Analysis in Large Language Models via Enhanced Activation Variance-Sparsity
Nov 15, 2024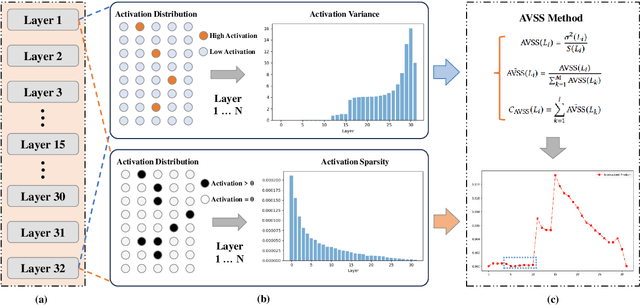
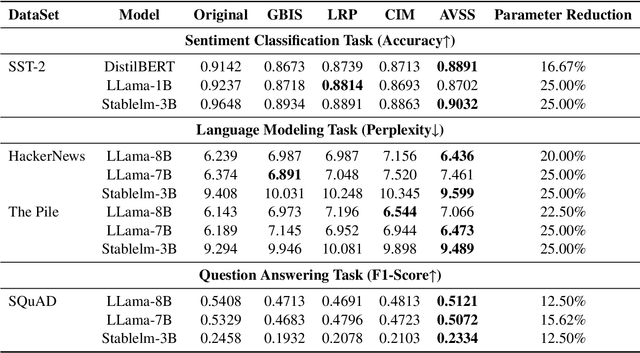
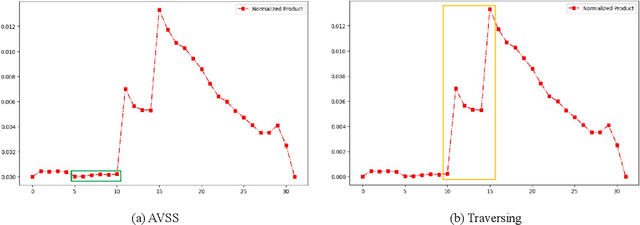
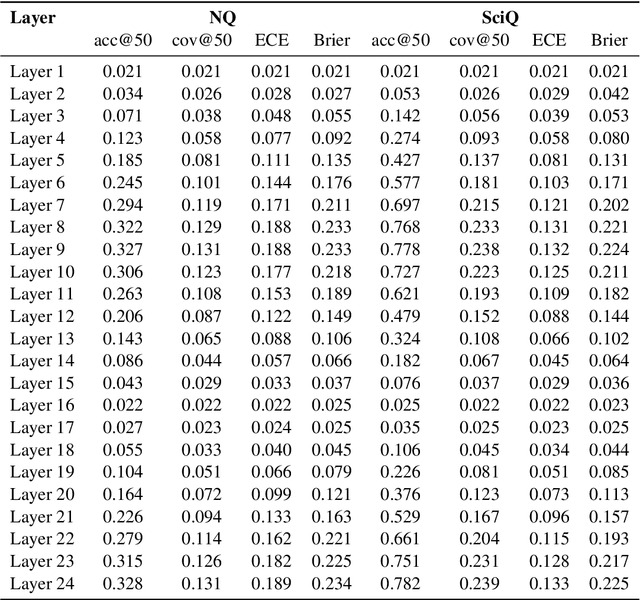
Evaluating the importance of different layers in large language models (LLMs) is crucial for optimizing model performance and interpretability. This paper first explores layer importance using the Activation Variance-Sparsity Score (AVSS), which combines normalized activation variance and sparsity to quantify each layer's contribution to overall model performance. By ranking layers based on AVSS and pruning the least impactful 25\%, our experiments on tasks such as question answering, language modeling, and sentiment classification show that over 90\% of the original performance is retained, highlighting potential redundancies in LLM architectures. Building on AVSS, we propose an enhanced version tailored to assess hallucination propensity across layers (EAVSS). This improved approach introduces Hallucination-Specific Activation Variance (HSAV) and Hallucination-Specific Sparsity (HSS) metrics, allowing precise identification of hallucination-prone layers. By incorporating contrastive learning on these layers, we effectively mitigate hallucination generation, contributing to more robust and efficient LLMs(The maximum performance improvement is 12\%). Our results on the NQ, SciQ, TriviaQA, TruthfulQA, and WikiQA datasets demonstrate the efficacy of this method, offering a comprehensive framework for both layer importance evaluation and hallucination mitigation in LLMs.
AVSS: Layer Importance Evaluation in Large Language Models via Activation Variance-Sparsity Analysis
Nov 04, 2024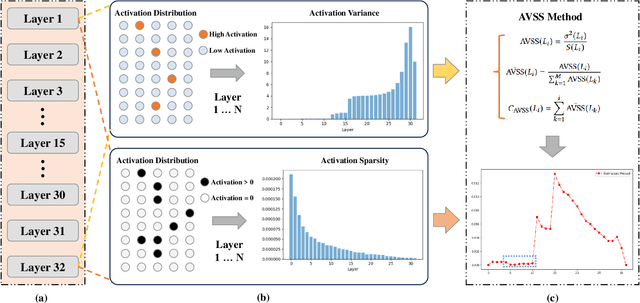
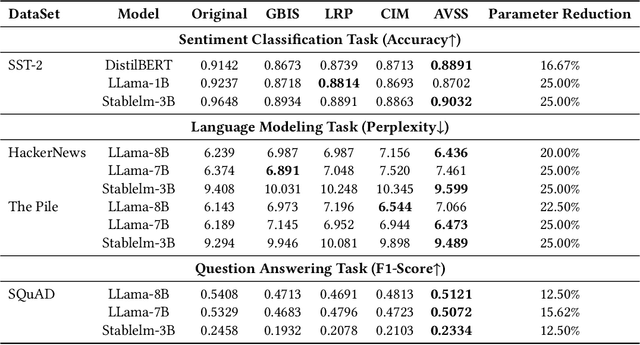
The evaluation of layer importance in deep learning has been an active area of research, with significant implications for model optimization and interpretability. Recently, large language models (LLMs) have gained prominence across various domains, yet limited studies have explored the functional importance and performance contributions of individual layers within LLMs, especially from the perspective of activation distribution. In this work, we propose the Activation Variance-Sparsity Score (AVSS), a novel metric combining normalized activation variance and sparsity to assess each layer's contribution to model performance. By identifying and removing approximately the lowest 25% of layers based on AVSS, we achieve over 90% of original model performance across tasks such as question answering, language modeling, and sentiment classification, indicating that these layers may be non-essential. Our approach provides a systematic method for identifying less critical layers, contributing to efficient large language model architectures.
FTS: A Framework to Find a Faithful TimeSieve
May 30, 2024
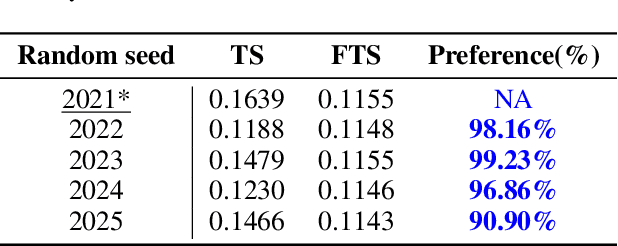
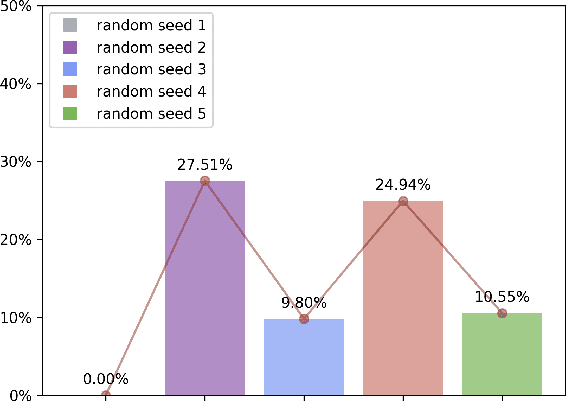
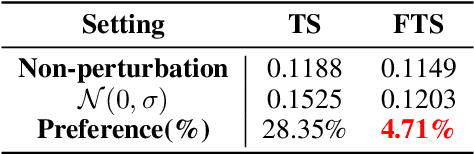
The field of time series forecasting has garnered significant attention in recent years, prompting the development of advanced models like TimeSieve, which demonstrates impressive performance. However, an analysis reveals certain unfaithfulness issues, including high sensitivity to random seeds and minute input noise perturbations. Recognizing these challenges, we embark on a quest to define the concept of \textbf{\underline{F}aithful \underline{T}ime\underline{S}ieve \underline{(FTS)}}, a model that consistently delivers reliable and robust predictions. To address these issues, we propose a novel framework aimed at identifying and rectifying unfaithfulness in TimeSieve. Our framework is designed to enhance the model's stability and resilience, ensuring that its outputs are less susceptible to the aforementioned factors. Experimentation validates the effectiveness of our proposed framework, demonstrating improved faithfulness in the model's behavior. Looking forward, we plan to expand our experimental scope to further validate and optimize our algorithm, ensuring comprehensive faithfulness across a wide range of scenarios. Ultimately, we aspire to make this framework can be applied to enhance the faithfulness of not just TimeSieve but also other state-of-the-art temporal methods, thereby contributing to the reliability and robustness of temporal modeling as a whole.