 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFTS: A Framework to Find a Faithful TimeSieve
May 30, 2024
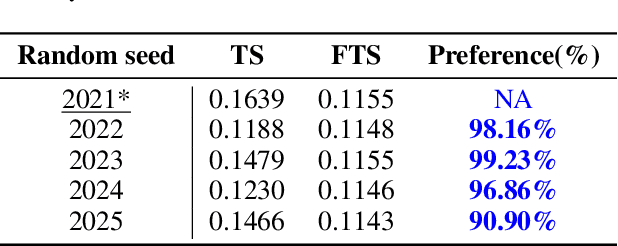
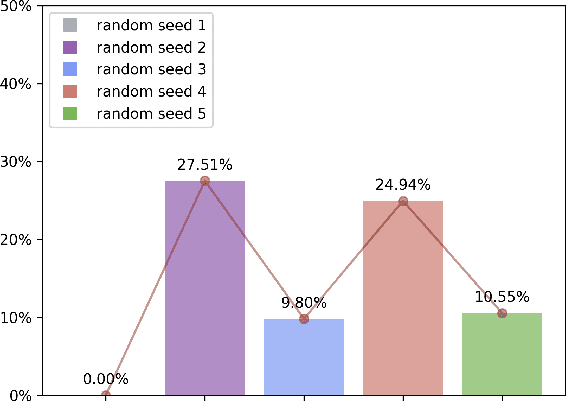
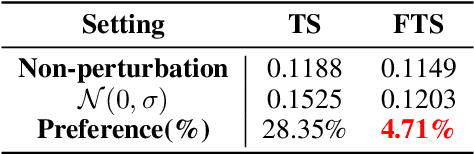
The field of time series forecasting has garnered significant attention in recent years, prompting the development of advanced models like TimeSieve, which demonstrates impressive performance. However, an analysis reveals certain unfaithfulness issues, including high sensitivity to random seeds and minute input noise perturbations. Recognizing these challenges, we embark on a quest to define the concept of \textbf{\underline{F}aithful \underline{T}ime\underline{S}ieve \underline{(FTS)}}, a model that consistently delivers reliable and robust predictions. To address these issues, we propose a novel framework aimed at identifying and rectifying unfaithfulness in TimeSieve. Our framework is designed to enhance the model's stability and resilience, ensuring that its outputs are less susceptible to the aforementioned factors. Experimentation validates the effectiveness of our proposed framework, demonstrating improved faithfulness in the model's behavior. Looking forward, we plan to expand our experimental scope to further validate and optimize our algorithm, ensuring comprehensive faithfulness across a wide range of scenarios. Ultimately, we aspire to make this framework can be applied to enhance the faithfulness of not just TimeSieve but also other state-of-the-art temporal methods, thereby contributing to the reliability and robustness of temporal modeling as a whole.
Magic-Me: Identity-Specific Video Customized Diffusion
Feb 14, 2024



Creating content for a specific identity (ID) has shown significant interest in the field of generative models. In the field of text-to-image generation (T2I), subject-driven content generation has achieved great progress with the ID in the images controllable. However, extending it to video generation is not well explored. In this work, we propose a simple yet effective subject identity controllable video generation framework, termed Video Custom Diffusion (VCD). With a specified subject ID defined by a few images, VCD reinforces the identity information extraction and injects frame-wise correlation at the initialization stage for stable video outputs with identity preserved to a large extent. To achieve this, we propose three novel components that are essential for high-quality ID preservation: 1) an ID module trained with the cropped identity by prompt-to-segmentation to disentangle the ID information and the background noise for more accurate ID token learning; 2) a text-to-video (T2V) VCD module with 3D Gaussian Noise Prior for better inter-frame consistency and 3) video-to-video (V2V) Face VCD and Tiled VCD modules to deblur the face and upscale the video for higher resolution. Despite its simplicity, we conducted extensive experiments to verify that VCD is able to generate stable and high-quality videos with better ID over the selected strong baselines. Besides, due to the transferability of the ID module, VCD is also working well with finetuned text-to-image models available publically, further improving its usability. The codes are available at https://github.com/Zhen-Dong/Magic-Me.
Learning Transferable Kinematic Dictionary for 3D Human Pose and Shape Reconstruction
Apr 21, 2021
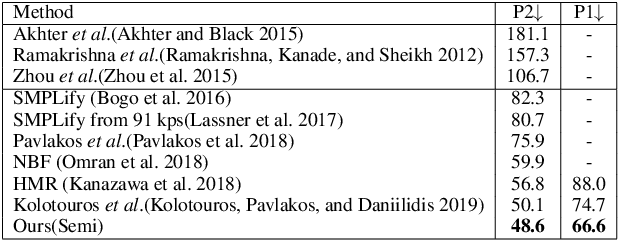


Estimating 3D human pose and shape from a single image is highly under-constrained. To address this ambiguity, we propose a novel prior, namely kinematic dictionary, which explicitly regularizes the solution space of relative 3D rotations of human joints in the kinematic tree. Integrated with a statistical human model and a deep neural network, our method achieves end-to-end 3D reconstruction without the need of using any shape annotations during the training of neural networks. The kinematic dictionary bridges the gap between in-the-wild images and 3D datasets, and thus facilitates end-to-end training across all types of datasets. The proposed method achieves competitive results on large-scale datasets including Human3.6M, MPI-INF-3DHP, and LSP, while running in real-time given the human bounding boxes.
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control
Apr 05, 2021
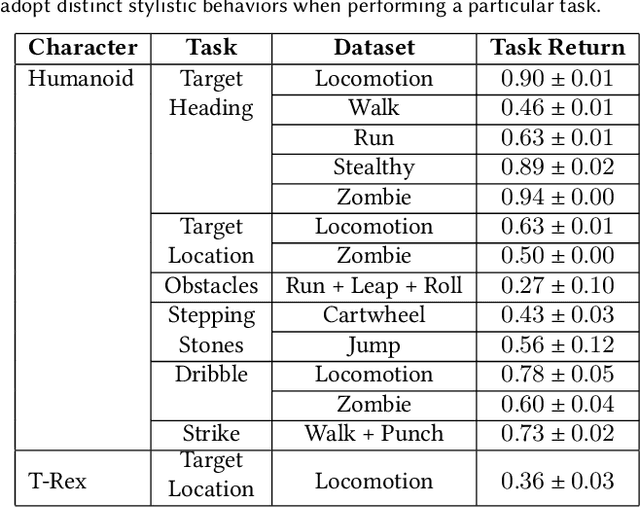


Synthesizing graceful and life-like behaviors for physically simulated characters has been a fundamental challenge in computer animation. Data-driven methods that leverage motion tracking are a prominent class of techniques for producing high fidelity motions for a wide range of behaviors. However, the effectiveness of these tracking-based methods often hinges on carefully designed objective functions, and when applied to large and diverse motion datasets, these methods require significant additional machinery to select the appropriate motion for the character to track in a given scenario. In this work, we propose to obviate the need to manually design imitation objectives and mechanisms for motion selection by utilizing a fully automated approach based on adversarial imitation learning. High-level task objectives that the character should perform can be specified by relatively simple reward functions, while the low-level style of the character's behaviors can be specified by a dataset of unstructured motion clips, without any explicit clip selection or sequencing. These motion clips are used to train an adversarial motion prior, which specifies style-rewards for training the character through reinforcement learning (RL). The adversarial RL procedure automatically selects which motion to perform, dynamically interpolating and generalizing from the dataset. Our system produces high-quality motions that are comparable to those achieved by state-of-the-art tracking-based techniques, while also being able to easily accommodate large datasets of unstructured motion clips. Composition of disparate skills emerges automatically from the motion prior, without requiring a high-level motion planner or other task-specific annotations of the motion clips. We demonstrate the effectiveness of our framework on a diverse cast of complex simulated characters and a challenging suite of motor control tasks.
PaStaNet: Toward Human Activity Knowledge Engine
Apr 21, 2020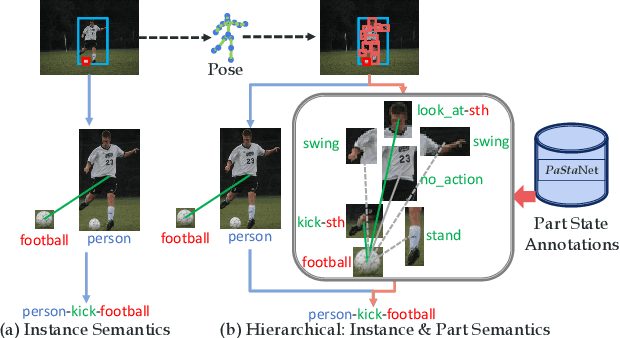
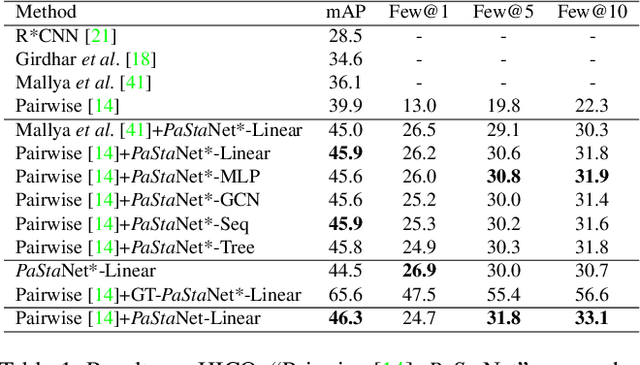

Existing image-based activity understanding methods mainly adopt direct mapping, i.e. from image to activity concepts, which may encounter performance bottleneck since the huge gap. In light of this, we propose a new path: infer human part states first and then reason out the activities based on part-level semantics. Human Body Part States (PaSta) are fine-grained action semantic tokens, e.g. <hand, hold, something>, which can compose the activities and help us step toward human activity knowledge engine. To fully utilize the power of PaSta, we build a large-scale knowledge base PaStaNet, which contains 7M+ PaSta annotations. And two corresponding models are proposed: first, we design a model named Activity2Vec to extract PaSta features, which aim to be general representations for various activities. Second, we use a PaSta-based Reasoning method to infer activities. Promoted by PaStaNet, our method achieves significant improvements, e.g. 6.4 and 13.9 mAP on full and one-shot sets of HICO in supervised learning, and 3.2 and 4.2 mAP on V-COCO and images-based AVA in transfer learning. Code and data are available at http://hake-mvig.cn/.
HAKE: Human Activity Knowledge Engine
May 08, 2019

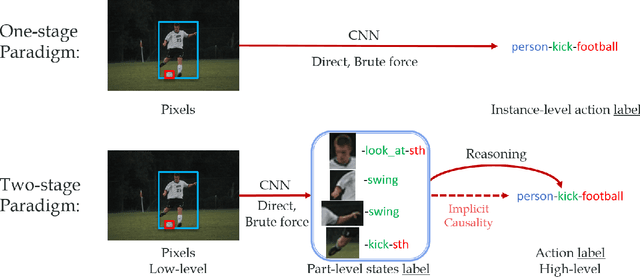

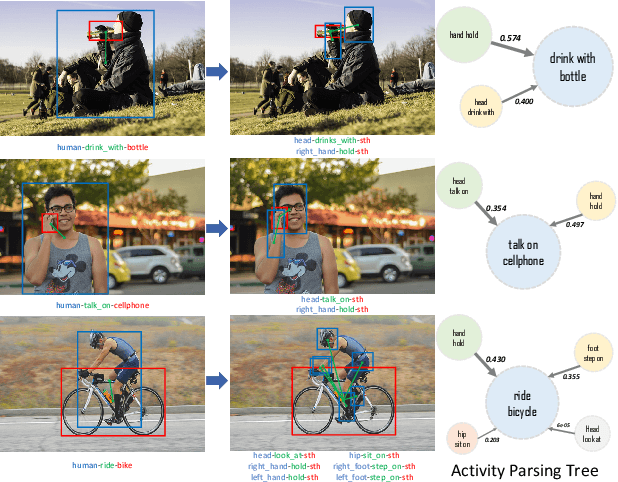
Human activity understanding is crucial for building automatic intelligent system. With the help of deep learning, activity understanding has made huge progress recently. But some challenges such as imbalanced data distribution, action ambiguity, complex visual patterns still remain. To address these and promote the activity understanding, we build a large-scale Human Activity Knowledge Engine (HAKE) based on the human body part states. Upon existing activity datasets, we annotate the part states of all the active persons in all images, thus establish the relationship between instance activity and body part states. Furthermore, we propose a HAKE based part state recognition model with a knowledge extractor named Activity2Vec and a corresponding part state based reasoning network. With HAKE, our method can alleviate the learning difficulty brought by the long-tail data distribution, and bring in interpretability. Now our HAKE has more than 7 M+ part state annotations and is still under construction. We first validate our approach on a part of HAKE in this preliminary paper, where we show 7.2 mAP performance improvement on Human-Object Interaction recognition, and 12.38 mAP improvement on the one-shot subsets.
Transferable Interactiveness Prior for Human-Object Interaction Detection
Nov 23, 2018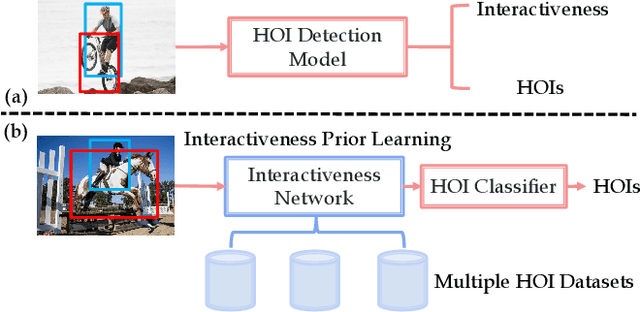
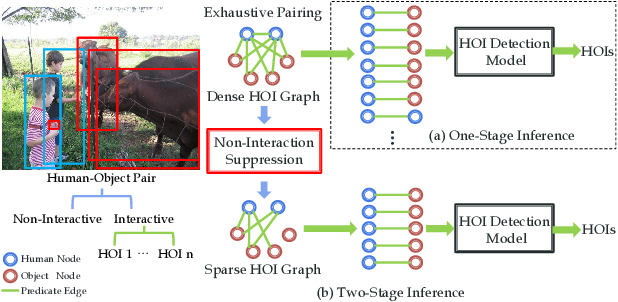
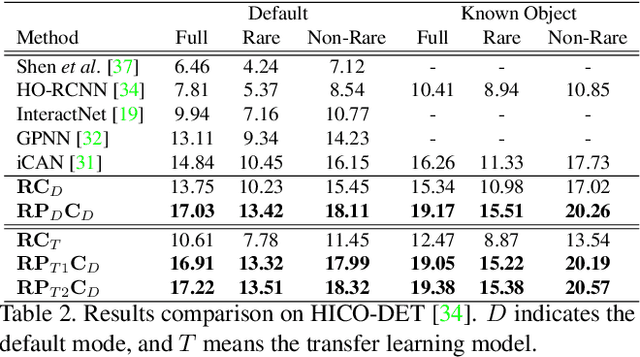
Human-Object Interaction (HOI) Detection is an important problem to understand how humans interact with objects. In this paper, we explore Interactiveness Prior which indicates whether human and object interact with each other or not. We found that interactiveness prior can be learned across HOI datasets, regardless of HOI category settings. Our core idea is to exploit an Interactiveness Network to learn the general interactiveness prior from multiple HOI datasets and perform Non-Interaction Suppression before HOI classification in inference. On account of the generalization of interactiveness prior, interactiveness network is a transferable knowledge learner and can be cooperated with any HOI detection models to achieve desirable results. We extensively evaluate the proposed method on HICO-DET and V-COCO datasets. Our framework outperforms state-of-the-art HOI detection results by a great margin, verifying its efficacy and flexibility. Source codes and models will be made publicly available.