 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-based Bone Quality Classification Method for Spinal Metastasis
Feb 14, 2024Spinal metastasis is the most common disease in bone metastasis and may cause pain, instability and neurological injuries. Early detection of spinal metastasis is critical for accurate staging and optimal treatment. The diagnosis is usually facilitated with Computed Tomography (CT) scans, which requires considerable efforts from well-trained radiologists. In this paper, we explore a learning-based automatic bone quality classification method for spinal metastasis based on CT images. We simultaneously take the posterolateral spine involvement classification task into account, and employ multi-task learning (MTL) technique to improve the performance. MTL acts as a form of inductive bias which helps the model generalize better on each task by sharing representations between related tasks. Based on the prior knowledge that the mixed type can be viewed as both blastic and lytic, we model the task of bone quality classification as two binary classification sub-tasks, i.e., whether blastic and whether lytic, and leverage a multiple layer perceptron to combine their predictions. In order to make the model more robust and generalize better, self-paced learning is adopted to gradually involve from easy to more complex samples into the training process. The proposed learning-based method is evaluated on a proprietary spinal metastasis CT dataset. At slice level, our method significantly outperforms an 121-layer DenseNet classifier in sensitivities by $+12.54\%$, $+7.23\%$ and $+29.06\%$ for blastic, mixed and lytic lesions, respectively, meanwhile $+12.33\%$, $+23.21\%$ and $+34.25\%$ at vertebrae level.
Weakly Supervised Segmentation of Vertebral Bodies with Iterative Slice-propagation
Feb 14, 2024Vertebral body (VB) segmentation is an important preliminary step towards medical visual diagnosis for spinal diseases. However, most previous works require pixel/voxel-wise strong supervisions, which is expensive, tedious and time-consuming for experts to annotate. In this paper, we propose a Weakly supervised Iterative Spinal Segmentation (WISS) method leveraging only four corner landmark weak labels on a single sagittal slice to achieve automatic volumetric segmentation from CT images for VBs. WISS first segments VBs on an annotated sagittal slice in an iterative self-training manner. This self-training method alternates between training and refining labels in the training set. Then WISS proceeds to segment the whole VBs slice by slice with a slice-propagation method to obtain volumetric segmentations. We evaluate the performance of WISS on a private spinal metastases CT dataset and the public lumbar CT dataset. On the first dataset, WISS achieves distinct improvements with regard to two different backbones. For the second dataset, WISS achieves dice coefficients of $91.7\%$ and $83.7\%$ for mid-sagittal slices and 3D CT volumes, respectively, saving a lot of labeling costs and only sacrificing a little segmentation performance.
Registration based Few-Shot Anomaly Detection
Jul 15, 2022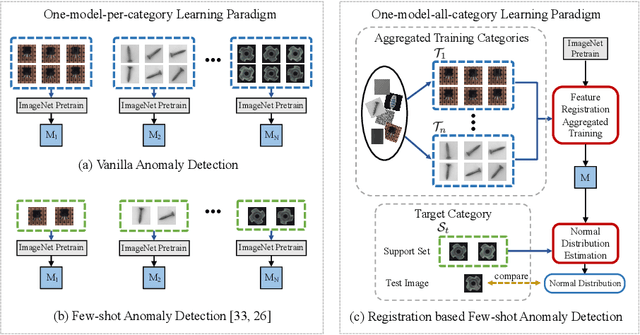
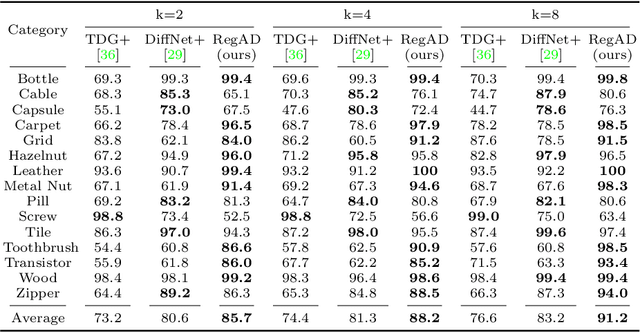
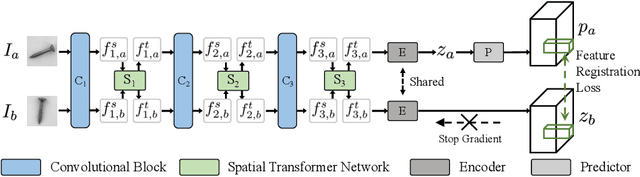
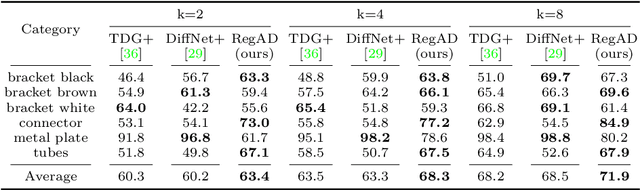
This paper considers few-shot anomaly detection (FSAD), a practical yet under-studied setting for anomaly detection (AD), where only a limited number of normal images are provided for each category at training. So far, existing FSAD studies follow the one-model-per-category learning paradigm used for standard AD, and the inter-category commonality has not been explored. Inspired by how humans detect anomalies, i.e., comparing an image in question to normal images, we here leverage registration, an image alignment task that is inherently generalizable across categories, as the proxy task, to train a category-agnostic anomaly detection model. During testing, the anomalies are identified by comparing the registered features of the test image and its corresponding support (normal) images. As far as we know, this is the first FSAD method that trains a single generalizable model and requires no re-training or parameter fine-tuning for new categories. Experimental results have shown that the proposed method outperforms the state-of-the-art FSAD methods by 3%-8% in AUC on the MVTec and MPDD benchmarks.
CaT: Weakly Supervised Object Detection with Category Transfer
Aug 17, 2021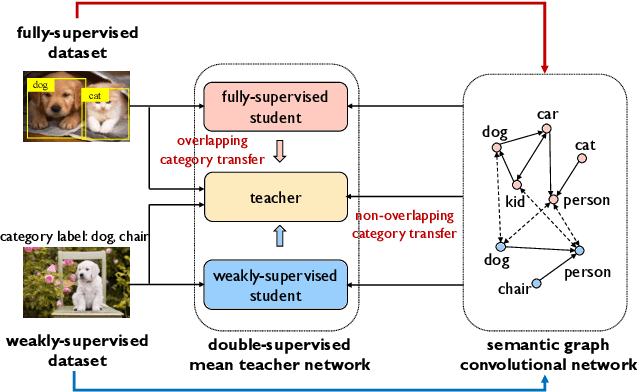
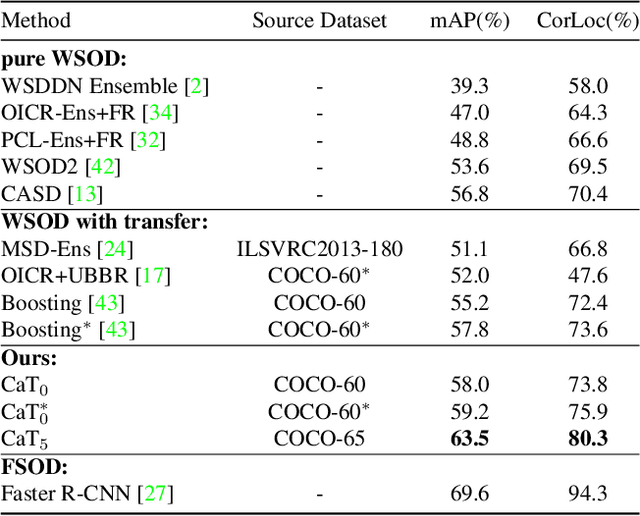
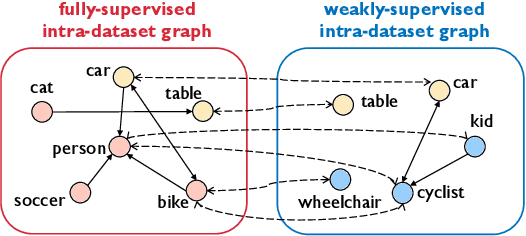
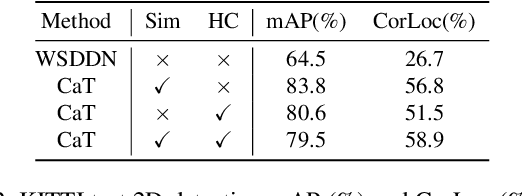
A large gap exists between fully-supervised object detection and weakly-supervised object detection. To narrow this gap, some methods consider knowledge transfer from additional fully-supervised dataset. But these methods do not fully exploit discriminative category information in the fully-supervised dataset, thus causing low mAP. To solve this issue, we propose a novel category transfer framework for weakly supervised object detection. The intuition is to fully leverage both visually-discriminative and semantically-correlated category information in the fully-supervised dataset to enhance the object-classification ability of a weakly-supervised detector. To handle overlapping category transfer, we propose a double-supervision mean teacher to gather common category information and bridge the domain gap between two datasets. To handle non-overlapping category transfer, we propose a semantic graph convolutional network to promote the aggregation of semantic features between correlated categories. Experiments are conducted with Pascal VOC 2007 as the target weakly-supervised dataset and COCO as the source fully-supervised dataset. Our category transfer framework achieves 63.5% mAP and 80.3% CorLoc with 5 overlapping categories between two datasets, which outperforms the state-of-the-art methods. Codes are avaliable at https://github.com/MediaBrain-SJTU/CaT.
ContourRender: Detecting Arbitrary Contour Shape For Instance Segmentation In One Pass
Jun 07, 2021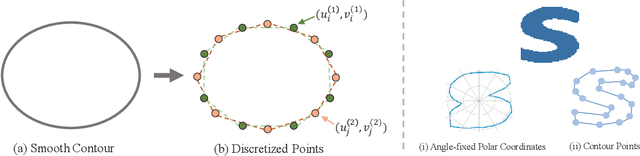
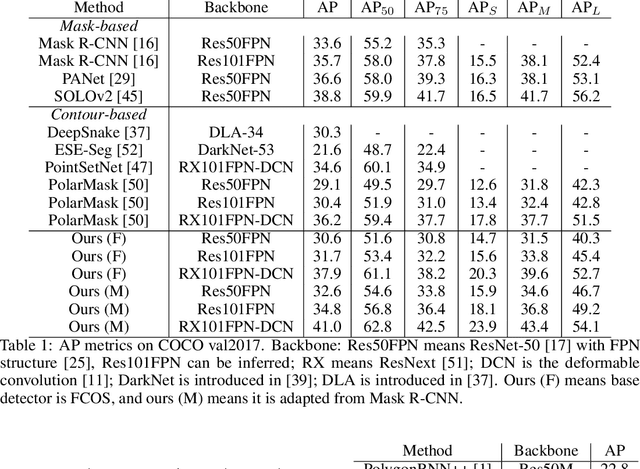
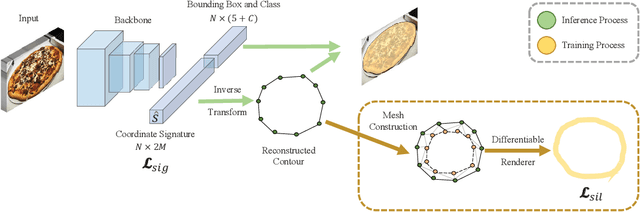
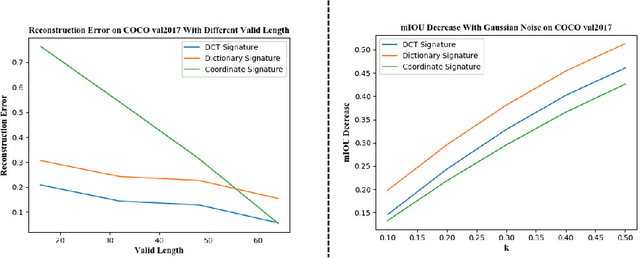
Direct contour regression for instance segmentation is a challenging task. Previous works usually achieve it by learning to progressively refine the contour prediction or adopting a shape representation with limited expressiveness. In this work, we argue that the difficulty in regressing the contour points in one pass is mainly due to the ambiguity when discretizing a smooth contour into a polygon. To address the ambiguity, we propose a novel differentiable rendering-based approach named \textbf{ContourRender}. During training, it first predicts a contour generated by an invertible shape signature, and then optimizes the contour with the more stable silhouette by converting it to a contour mesh and rendering the mesh to a 2D map. This method significantly improves the quality of contour without iterations or cascaded refinements. Moreover, as optimization is not needed during inference, the inference speed will not be influenced. Experiments show the proposed ContourRender outperforms all the contour-based instance segmentation approaches on COCO, while stays competitive with the iteration-based state-of-the-art on Cityscapes. In addition, we specifically select a subset from COCO val2017 named COCO ContourHard-val to further demonstrate the contour quality improvements. Codes, models, and dataset split will be released.
ESAD: End-to-end Deep Semi-supervised Anomaly Detection
Dec 09, 2020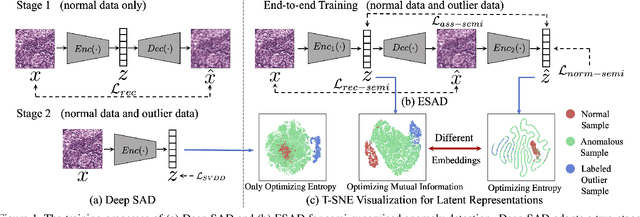
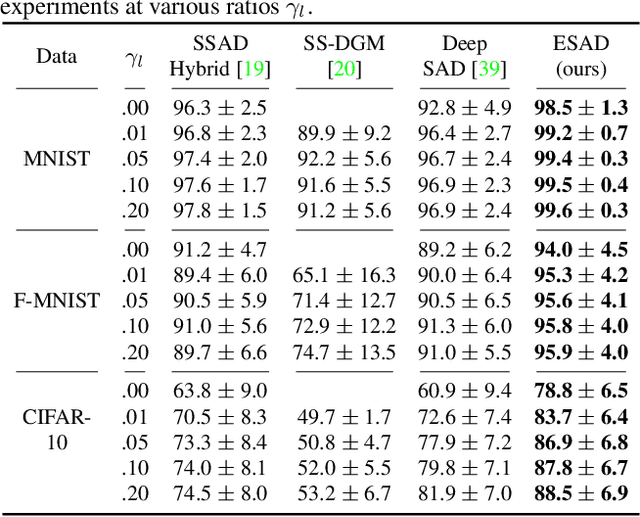
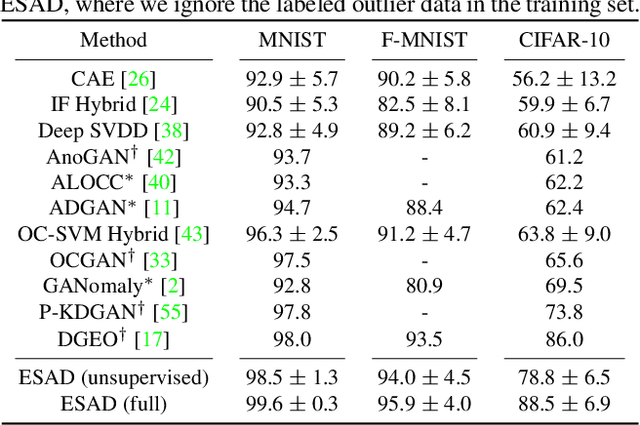
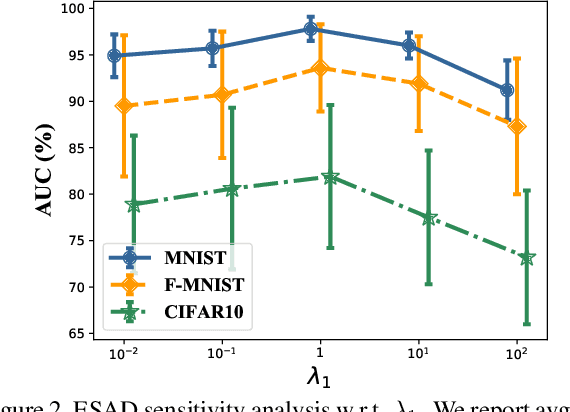
This paper explores semi-supervised anomaly detection, a more practical setting for anomaly detection where a small set of labeled outlier samples are provided in addition to a large amount of unlabeled data for training. Rethinking the optimization target of anomaly detection, we propose a new objective function that measures the KL-divergence between normal and anomalous data, and prove that two factors: the mutual information between the data and latent representations, and the entropy of latent representations, constitute an integral objective function for anomaly detection. To resolve the contradiction in simultaneously optimizing the two factors, we propose a novel encoder-decoder-encoder structure, with the first encoder focusing on optimizing the mutual information and the second encoder focusing on optimizing the entropy. The two encoders are enforced to share similar encoding with a consistent constraint on their latent representations. Extensive experiments have revealed that the proposed method significantly outperforms several state-of-the-arts on multiple benchmark datasets, including medical diagnosis and several classic anomaly detection benchmarks.
Phase Collaborative Network for Multi-Phase Medical Imaging Segmentation
Dec 06, 2018



Integrating multi-phase information is an effective way of boosting visual recognition. In this paper, we investigate this problem from the perspective of medical imaging analysis, in which two phases in CT scans known as arterial and venous are combined towards higher segmentation accuracy. To this end, we propose Phase Collaborative Network (PCN), an end-to-end network which contains both generative and discriminative modules to formulate phase-to-phase relations and data-to-label relations, respectively. Experiments are performed on several CT image segmentation datasets. PCN achieves superior performance with either two phases or only one phase available. Moreover, we empirically verify that the accuracy gain comes from the collaboration between phases.
Transferable Interactiveness Prior for Human-Object Interaction Detection
Nov 23, 2018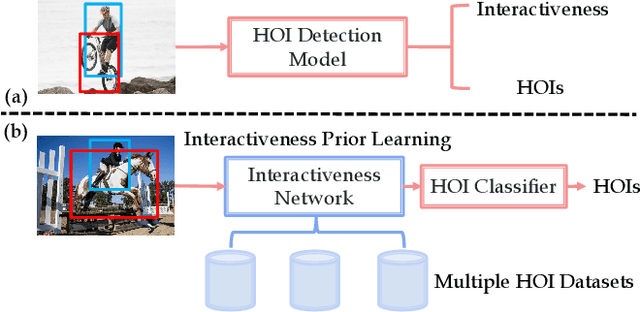
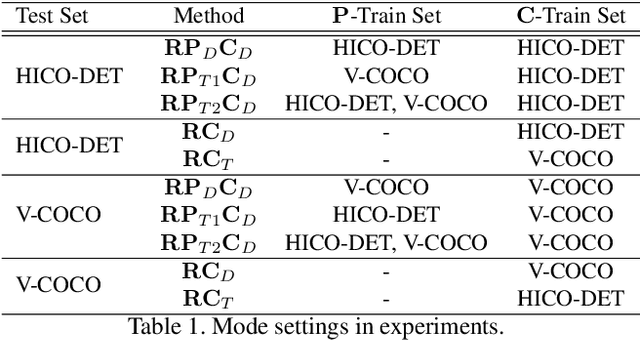
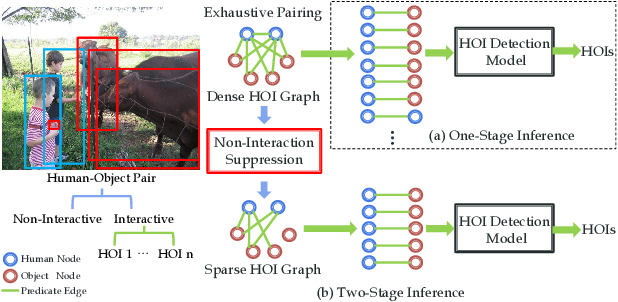
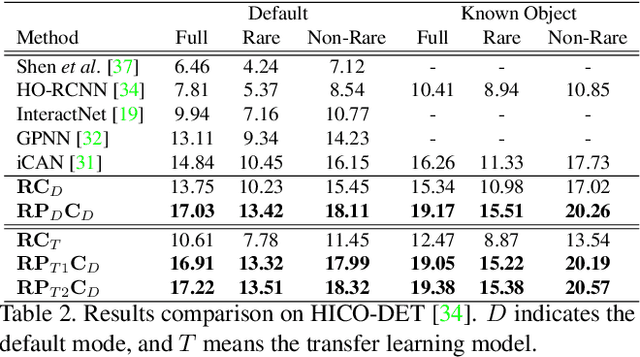
Human-Object Interaction (HOI) Detection is an important problem to understand how humans interact with objects. In this paper, we explore Interactiveness Prior which indicates whether human and object interact with each other or not. We found that interactiveness prior can be learned across HOI datasets, regardless of HOI category settings. Our core idea is to exploit an Interactiveness Network to learn the general interactiveness prior from multiple HOI datasets and perform Non-Interaction Suppression before HOI classification in inference. On account of the generalization of interactiveness prior, interactiveness network is a transferable knowledge learner and can be cooperated with any HOI detection models to achieve desirable results. We extensively evaluate the proposed method on HICO-DET and V-COCO datasets. Our framework outperforms state-of-the-art HOI detection results by a great margin, verifying its efficacy and flexibility. Source codes and models will be made publicly available.