 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESAD: End-to-end Deep Semi-supervised Anomaly Detection
Paper and Code
Dec 09, 2020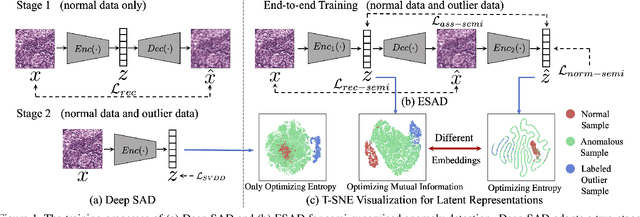
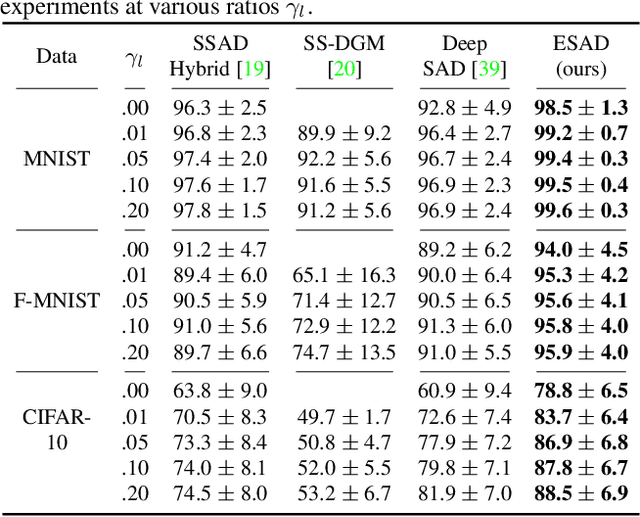
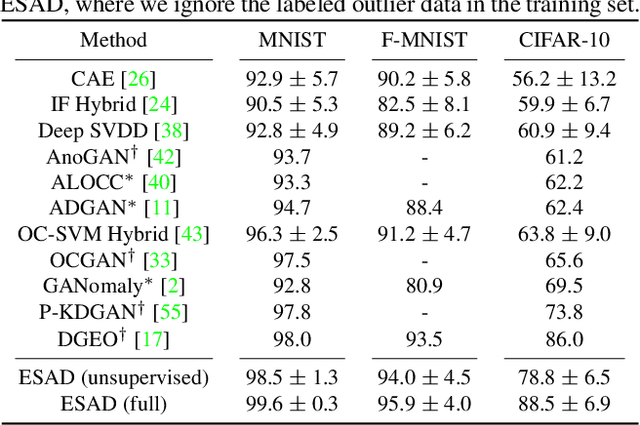
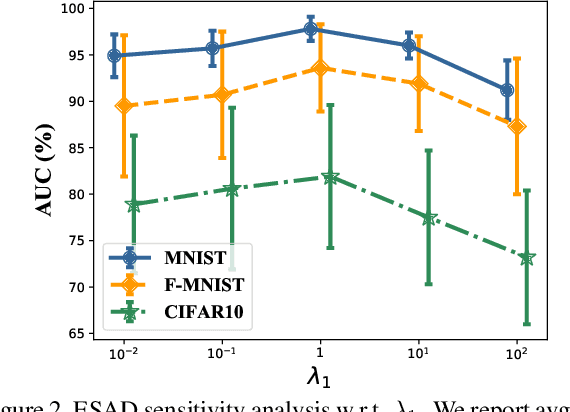
This paper explores semi-supervised anomaly detection, a more practical setting for anomaly detection where a small set of labeled outlier samples are provided in addition to a large amount of unlabeled data for training. Rethinking the optimization target of anomaly detection, we propose a new objective function that measures the KL-divergence between normal and anomalous data, and prove that two factors: the mutual information between the data and latent representations, and the entropy of latent representations, constitute an integral objective function for anomaly detection. To resolve the contradiction in simultaneously optimizing the two factors, we propose a novel encoder-decoder-encoder structure, with the first encoder focusing on optimizing the mutual information and the second encoder focusing on optimizing the entropy. The two encoders are enforced to share similar encoding with a consistent constraint on their latent representations. Extensive experiments have revealed that the proposed method significantly outperforms several state-of-the-arts on multiple benchmark datasets, including medical diagnosis and several classic anomaly detection benchmarks.