 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBI: Learning Dexterous In-hand Manipulation with Dynamic Visuotactile Shortcut Policy
Aug 20, 2025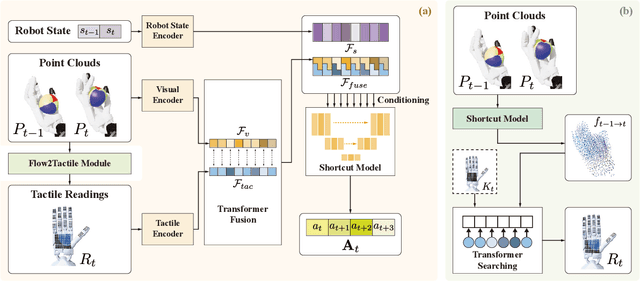


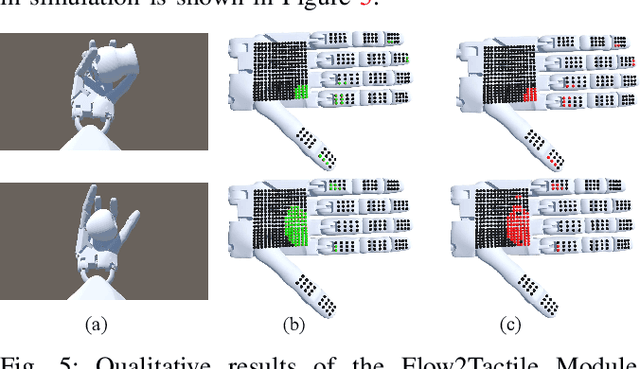
Dexterous in-hand manipulation is a long-standing challenge in robotics due to complex contact dynamics and partial observability. While humans synergize vision and touch for such tasks, robotic approaches often prioritize one modality, therefore limiting adaptability. This paper introduces Flow Before Imitation (FBI), a visuotactile imitation learning framework that dynamically fuses tactile interactions with visual observations through motion dynamics. Unlike prior static fusion methods, FBI establishes a causal link between tactile signals and object motion via a dynamics-aware latent model. FBI employs a transformer-based interaction module to fuse flow-derived tactile features with visual inputs, training a one-step diffusion policy for real-time execution. Extensive experiments demonstrate that the proposed method outperforms the baseline methods in both simulation and the real world on two customized in-hand manipulation tasks and three standard dexterous manipulation tasks. Code, models, and more results are available in the website https://sites.google.com/view/dex-fbi.
DexTOG: Learning Task-Oriented Dexterous Grasp with Language
Apr 06, 2025This study introduces a novel language-guided diffusion-based learning framework, DexTOG, aimed at advancing the field of task-oriented grasping (TOG) with dexterous hands. Unlike existing methods that mainly focus on 2-finger grippers, this research addresses the complexities of dexterous manipulation, where the system must identify non-unique optimal grasp poses under specific task constraints, cater to multiple valid grasps, and search in a high degree-of-freedom configuration space in grasp planning. The proposed DexTOG includes a diffusion-based grasp pose generation model, DexDiffu, and a data engine to support the DexDiffu. By leveraging DexTOG, we also proposed a new dataset, DexTOG-80K, which was developed using a shadow robot hand to perform various tasks on 80 objects from 5 categories, showcasing the dexterity and multi-tasking capabilities of the robotic hand. This research not only presents a significant leap in dexterous TOG but also provides a comprehensive dataset and simulation validation, setting a new benchmark in robotic manipulation research.
Kalib: Markerless Hand-Eye Calibration with Keypoint Tracking
Aug 20, 2024



Hand-eye calibration involves estimating the transformation between the camera and the robot. Traditional methods rely on fiducial markers, involving much manual labor and careful setup. Recent advancements in deep learning offer markerless techniques, but they present challenges, including the need for retraining networks for each robot, the requirement of accurate mesh models for data generation, and the need to address the sim-to-real gap. In this letter, we propose Kalib, an automatic and universal markerless hand-eye calibration pipeline that leverages the generalizability of visual foundation models to eliminate these barriers. In each calibration process, Kalib uses keypoint tracking and proprioceptive sensors to estimate the transformation between a robot's coordinate space and its corresponding points in camera space. Our method does not require training new networks or access to mesh models. Through evaluations in simulation environments and the real-world dataset DROID, Kalib demonstrates superior accuracy compared to recent baseline methods. This approach provides an effective and flexible calibration process for various robot systems by simplifying setup and removing dependency on precise physical markers.
DiPGrasp: Parallel Local Searching for Efficient Differentiable Grasp Planning
Aug 08, 2024
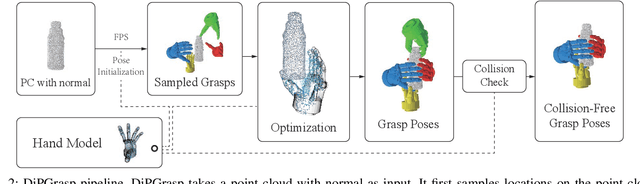
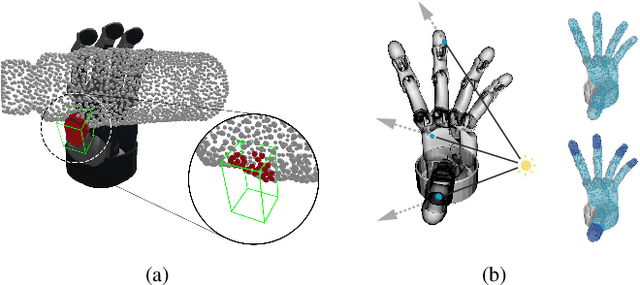

Grasp planning is an important task for robotic manipulation. Though it is a richly studied area, a standalone, fast, and differentiable grasp planner that can work with robot grippers of different DOFs has not been reported. In this work, we present DiPGrasp, a grasp planner that satisfies all these goals. DiPGrasp takes a force-closure geometric surface matching grasp quality metric. It adopts a gradient-based optimization scheme on the metric, which also considers parallel sampling and collision handling. This not only drastically accelerates the grasp search process over the object surface but also makes it differentiable. We apply DiPGrasp to three applications, namely grasp dataset construction, mask-conditioned planning, and pose refinement. For dataset generation, as a standalone planner, DiPGrasp has clear advantages over speed and quality compared with several classic planners. For mask-conditioned planning, it can turn a 3D perception model into a 3D grasp detection model instantly. As a pose refiner, it can optimize the coarse grasp prediction from the neural network, as well as the neural network parameters. Finally, we conduct real-world experiments with the Barrett hand and Schunk SVH 5-finger hand. Video and supplementary materials can be viewed on our website: \url{https://dipgrasp.robotflow.ai}.
MS-MANO: Enabling Hand Pose Tracking with Biomechanical Constraints
Apr 16, 2024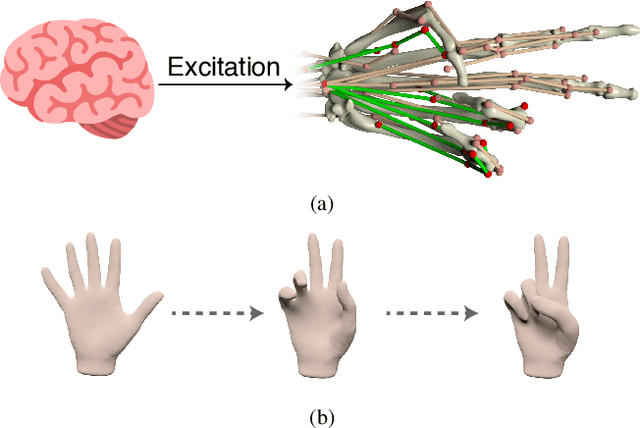
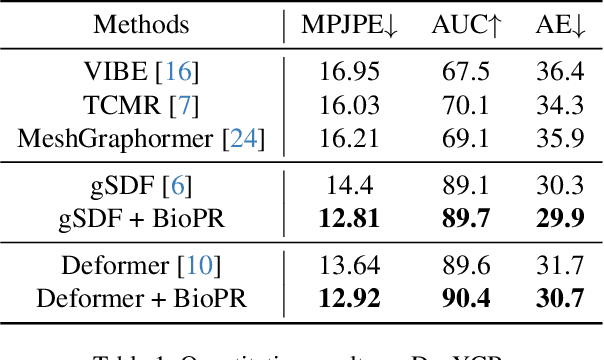
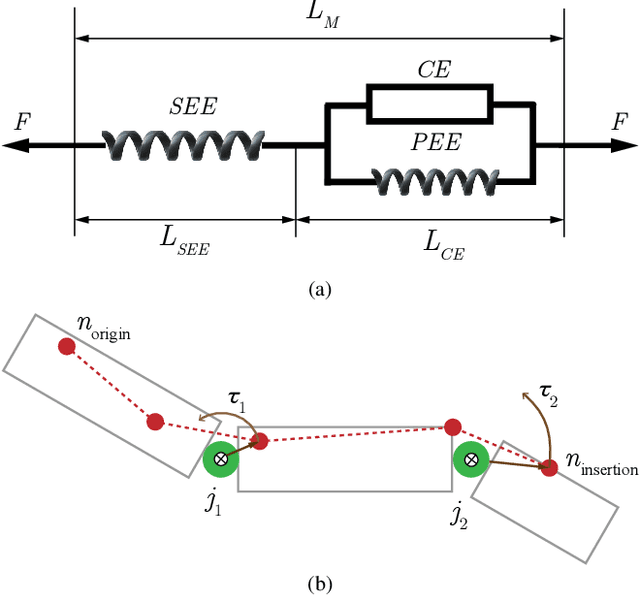
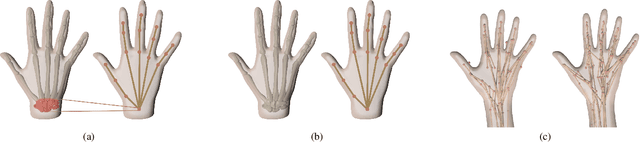
This work proposes a novel learning framework for visual hand dynamics analysis that takes into account the physiological aspects of hand motion. The existing models, which are simplified joint-actuated systems, often produce unnatural motions. To address this, we integrate a musculoskeletal system with a learnable parametric hand model, MANO, to create a new model, MS-MANO. This model emulates the dynamics of muscles and tendons to drive the skeletal system, imposing physiologically realistic constraints on the resulting torque trajectories. We further propose a simulation-in-the-loop pose refinement framework, BioPR, that refines the initial estimated pose through a multi-layer perceptron (MLP) network. Our evaluation of the accuracy of MS-MANO and the efficacy of the BioPR is conducted in two separate parts. The accuracy of MS-MANO is compared with MyoSuite, while the efficacy of BioPR is benchmarked against two large-scale public datasets and two recent state-of-the-art methods. The results demonstrate that our approach consistently improves the baseline methods both quantitatively and qualitatively.
RFTrans: Leveraging Refractive Flow of Transparent Objects for Surface Normal Estimation and Manipulation
Nov 21, 2023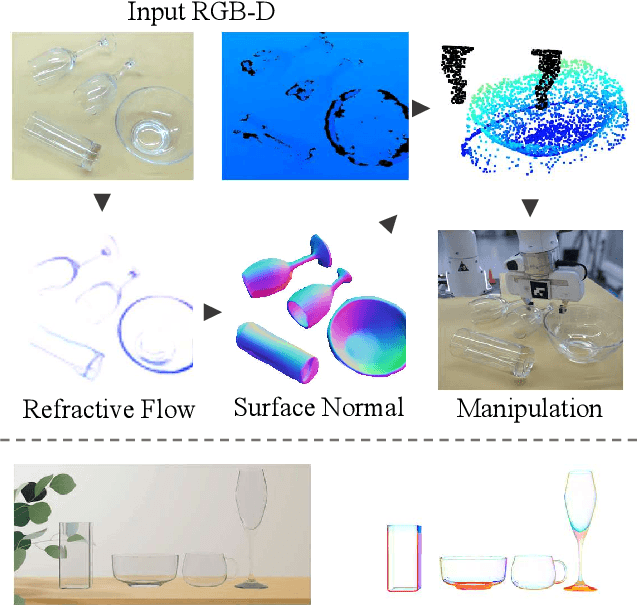
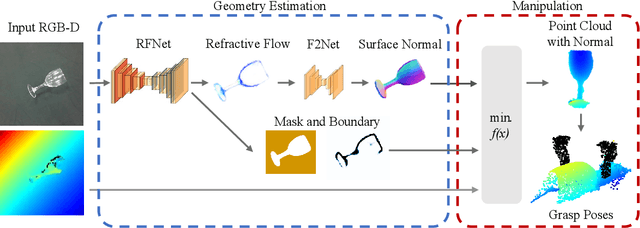
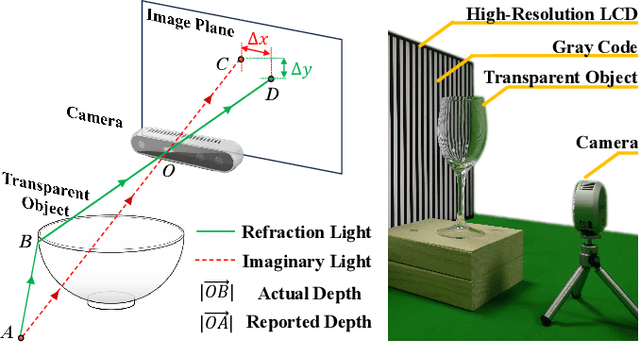

Transparent objects are widely used in our daily lives, making it important to teach robots to interact with them. However, it's not easy because the reflective and refractive effects can make RGB-D cameras fail to give accurate geometry measurements. To solve this problem, this paper introduces RFTrans, an RGB-D-based method for surface normal estimation and manipulation of transparent objects. By leveraging refractive flow as an intermediate representation, RFTrans circumvents the drawbacks of directly predicting the geometry (e.g. surface normal) from RGB images and helps bridge the sim-to-real gap. RFTrans integrates the RFNet, which predicts refractive flow, object mask, and boundaries, followed by the F2Net, which estimates surface normal from the refractive flow. To make manipulation possible, a global optimization module will take in the predictions, refine the raw depth, and construct the point cloud with normal. An analytical grasp planning algorithm, ISF, is followed to generate the grasp poses. We build a synthetic dataset with physically plausible ray-tracing rendering techniques to train the networks. Results show that the RFTrans trained on the synthetic dataset can consistently outperform the baseline ClearGrasp in both synthetic and real-world benchmarks by a large margin. Finally, a real-world robot grasping task witnesses an 83% success rate, proving that refractive flow can help enable direct sim-to-real transfer. The code, data, and supplementary materials are available at https://rftrans.robotflow.ai.
Precise Robotic Needle-Threading with Tactile Perception and Reinforcement Learning
Nov 04, 2023This work presents a novel tactile perception-based method, named T-NT, for performing the needle-threading task, an application of deformable linear object (DLO) manipulation. This task is divided into two main stages: Tail-end Finding and Tail-end Insertion. In the first stage, the agent traces the contour of the thread twice using vision-based tactile sensors mounted on the gripper fingers. The two-run tracing is to locate the tail-end of the thread. In the second stage, it employs a tactile-guided reinforcement learning (RL) model to drive the robot to insert the thread into the target needle eyelet. The RL model is trained in a Unity-based simulated environment. The simulation environment supports tactile rendering which can produce realistic tactile images and thread modeling. During insertion, the position of the poke point and the center of the eyelet are obtained through a pre-trained segmentation model, Grounded-SAM, which predicts the masks for both the needle eye and thread imprints. These positions are then fed into the reinforcement learning model, aiding in a smoother transition to real-world applications. Extensive experiments on real robots are conducted to demonstrate the efficacy of our method. More experiments and videos can be found in the supplementary materials and on the website: https://sites.google.com/view/tac-needlethreading.
GarmentTracking: Category-Level Garment Pose Tracking
Mar 24, 2023Garments are important to humans. A visual system that can estimate and track the complete garment pose can be useful for many downstream tasks and real-world applications. In this work, we present a complete package to address the category-level garment pose tracking task: (1) A recording system VR-Garment, with which users can manipulate virtual garment models in simulation through a VR interface. (2) A large-scale dataset VR-Folding, with complex garment pose configurations in manipulation like flattening and folding. (3) An end-to-end online tracking framework GarmentTracking, which predicts complete garment pose both in canonical space and task space given a point cloud sequence. Extensive experiments demonstrate that the proposed GarmentTracking achieves great performance even when the garment has large non-rigid deformation. It outperforms the baseline approach on both speed and accuracy. We hope our proposed solution can serve as a platform for future research. Codes and datasets are available in https://garment-tracking.robotflow.ai.
Level 2 Autonomous Driving on a Single Device: Diving into the Devils of Openpilot
Jun 16, 2022

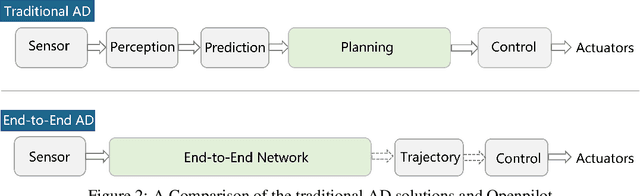
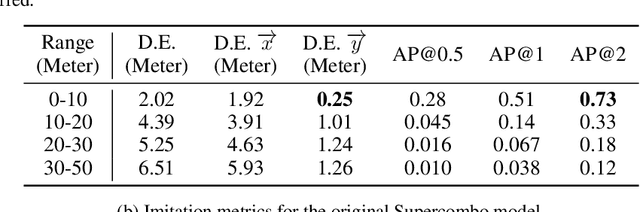
Equipped with a wide span of sensors, predominant autonomous driving solutions are becoming more modular-oriented for safe system design. Though these sensors have laid a solid foundation, most massive-production solutions up to date still fall into L2 phase. Among these, Comma.ai comes to our sight, claiming one $999 aftermarket device mounted with a single camera and board inside owns the ability to handle L2 scenarios. Together with open-sourced software of the entire system released by Comma.ai, the project is named Openpilot. Is it possible? If so, how is it made possible? With curiosity in mind, we deep-dive into Openpilot and conclude that its key to success is the end-to-end system design instead of a conventional modular framework. The model is briefed as Supercombo, and it can predict the ego vehicle's future trajectory and other road semantics on the fly from monocular input. Unfortunately, the training process and massive amount of data to make all these work are not publicly available. To achieve an intensive investigation, we try to reimplement the training details and test the pipeline on public benchmarks. The refactored network proposed in this work is referred to as OP-Deepdive. For a fair comparison of our version to the original Supercombo, we introduce a dual-model deployment scheme to test the driving performance in the real world. Experimental results on nuScenes, Comma2k19, CARLA, and in-house realistic scenarios verify that a low-cost device can indeed achieve most L2 functionalities and be on par with the original Supercombo model. In this report, we would like to share our latest findings, shed some light on the new perspective of end-to-end autonomous driving from an industrial product-level side, and potentially inspire the community to continue improving the performance. Our code, benchmarks are at https://github.com/OpenPerceptionX/Openpilot-Deepdive.
ContourRender: Detecting Arbitrary Contour Shape For Instance Segmentation In One Pass
Jun 07, 2021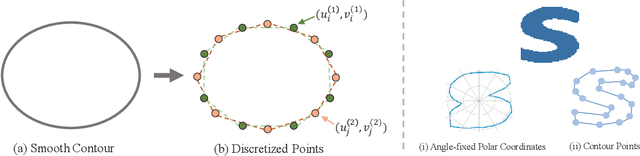
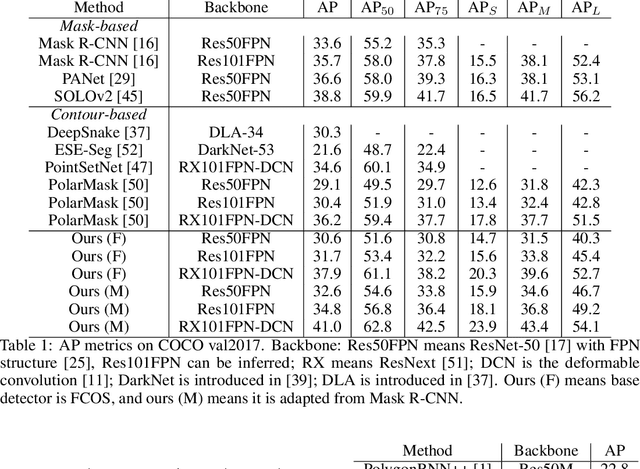
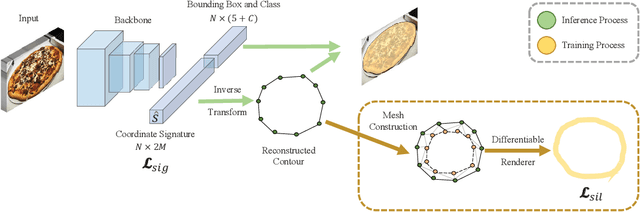
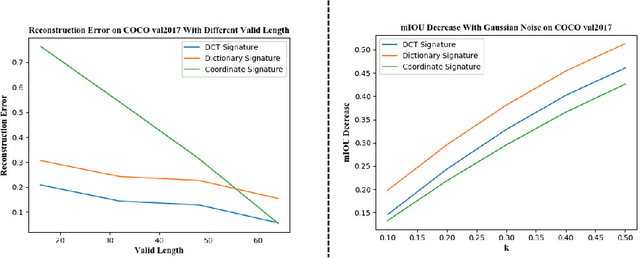
Direct contour regression for instance segmentation is a challenging task. Previous works usually achieve it by learning to progressively refine the contour prediction or adopting a shape representation with limited expressiveness. In this work, we argue that the difficulty in regressing the contour points in one pass is mainly due to the ambiguity when discretizing a smooth contour into a polygon. To address the ambiguity, we propose a novel differentiable rendering-based approach named \textbf{ContourRender}. During training, it first predicts a contour generated by an invertible shape signature, and then optimizes the contour with the more stable silhouette by converting it to a contour mesh and rendering the mesh to a 2D map. This method significantly improves the quality of contour without iterations or cascaded refinements. Moreover, as optimization is not needed during inference, the inference speed will not be influenced. Experiments show the proposed ContourRender outperforms all the contour-based instance segmentation approaches on COCO, while stays competitive with the iteration-based state-of-the-art on Cityscapes. In addition, we specifically select a subset from COCO val2017 named COCO ContourHard-val to further demonstrate the contour quality improvements. Codes, models, and dataset split will be released.