 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Anomaly Detection via Category-Agnostic Registration Learning
Jun 13, 2024Most existing anomaly detection methods require a dedicated model for each category. Such a paradigm, despite its promising results, is computationally expensive and inefficient, thereby failing to meet the requirements for real-world applications. Inspired by how humans detect anomalies, by comparing a query image to known normal ones, this paper proposes a novel few-shot anomaly detection (FSAD) framework. Using a training set of normal images from various categories, registration, aiming to align normal images of the same categories, is leveraged as the proxy task for self-supervised category-agnostic representation learning. At test time, an image and its corresponding support set, consisting of a few normal images from the same category, are supplied, and anomalies are identified by comparing the registered features of the test image to its corresponding support image features. Such a setup enables the model to generalize to novel test categories. It is, to our best knowledge, the first FSAD method that requires no model fine-tuning for novel categories: enabling a single model to be applied to all categories. Extensive experiments demonstrate the effectiveness of the proposed method. Particularly, it improves the current state-of-the-art for FSAD by 11.3% and 8.3% on the MVTec and MPDD benchmarks, respectively. The source code is available at https://github.com/Haoyan-Guan/CAReg.
One Prompt Word is Enough to Boost Adversarial Robustness for Pre-trained Vision-Language Models
Mar 04, 2024



Large pre-trained Vision-Language Models (VLMs) like CLIP, despite having remarkable generalization ability, are highly vulnerable to adversarial examples. This work studies the adversarial robustness of VLMs from the novel perspective of the text prompt instead of the extensively studied model weights (frozen in this work). We first show that the effectiveness of both adversarial attack and defense are sensitive to the used text prompt. Inspired by this, we propose a method to improve resilience to adversarial attacks by learning a robust text prompt for VLMs. The proposed method, named Adversarial Prompt Tuning (APT), is effective while being both computationally and data efficient. Extensive experiments are conducted across 15 datasets and 4 data sparsity schemes (from 1-shot to full training data settings) to show APT's superiority over hand-engineered prompts and other state-of-the-art adaption methods. APT demonstrated excellent abilities in terms of the in-distribution performance and the generalization under input distribution shift and across datasets. Surprisingly, by simply adding one learned word to the prompts, APT can significantly boost the accuracy and robustness (epsilon=4/255) over the hand-engineered prompts by +13% and +8.5% on average respectively. The improvement further increases, in our most effective setting, to +26.4% for accuracy and +16.7% for robustness. Code is available at https://github.com/TreeLLi/APT.
Rethinking the backbone architecture for tiny object detection
Mar 20, 2023



Tiny object detection has become an active area of research because images with tiny targets are common in several important real-world scenarios. However, existing tiny object detection methods use standard deep neural networks as their backbone architecture. We argue that such backbones are inappropriate for detecting tiny objects as they are designed for the classification of larger objects, and do not have the spatial resolution to identify small targets. Specifically, such backbones use max-pooling or a large stride at early stages in the architecture. This produces lower resolution feature-maps that can be efficiently processed by subsequent layers. However, such low-resolution feature-maps do not contain information that can reliably discriminate tiny objects. To solve this problem we design 'bottom-heavy' versions of backbones that allocate more resources to processing higher-resolution features without introducing any additional computational burden overall. We also investigate if pre-training these backbones on images of appropriate size, using CIFAR100 and ImageNet32, can further improve performance on tiny object detection. Results on TinyPerson and WiderFace show that detectors with our proposed backbones achieve better results than the current state-of-the-art methods.
Registration based Few-Shot Anomaly Detection
Jul 15, 2022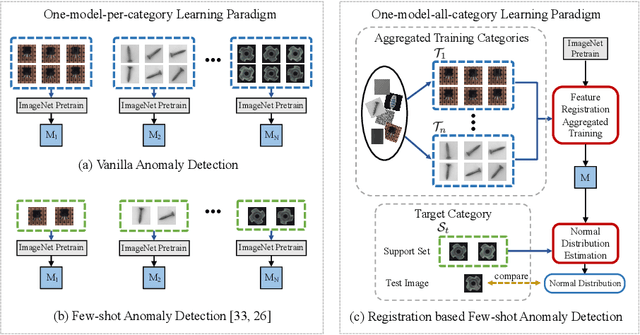
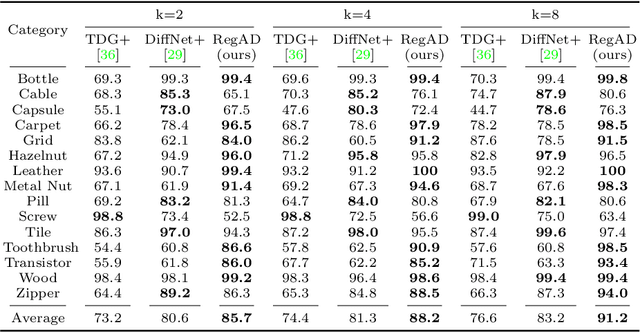
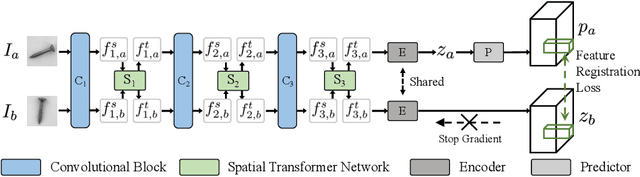
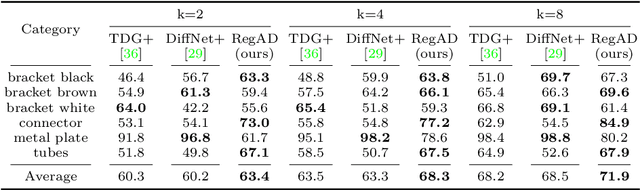
This paper considers few-shot anomaly detection (FSAD), a practical yet under-studied setting for anomaly detection (AD), where only a limited number of normal images are provided for each category at training. So far, existing FSAD studies follow the one-model-per-category learning paradigm used for standard AD, and the inter-category commonality has not been explored. Inspired by how humans detect anomalies, i.e., comparing an image in question to normal images, we here leverage registration, an image alignment task that is inherently generalizable across categories, as the proxy task, to train a category-agnostic anomaly detection model. During testing, the anomalies are identified by comparing the registered features of the test image and its corresponding support (normal) images. As far as we know, this is the first FSAD method that trains a single generalizable model and requires no re-training or parameter fine-tuning for new categories. Experimental results have shown that the proposed method outperforms the state-of-the-art FSAD methods by 3%-8% in AUC on the MVTec and MPDD benchmarks.